












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






OpenAI开发的分级强化学习算法旨在解决高级操作
2017年11月05日 由 yuxiangyu 发表
506122
0
我们已经开发了一种分层强化学习算法,它学习用于解决一组任务的高级操作,可以快速解决需要数千个时间步长的任务。我们的算法应用于一组导航问题时,会发现一组用于在不同方向上进行走路和爬行的高级动作,这使智能体能够快速掌握新的导航任务。
[video width="1280" height="640" mp4="https://www.atyun.com/uploadfile/2017/10/videoplayback-5.mp4"][/video]
人类解决复杂挑战的方法是将它分解成很多小的易于控制的部分。例如,煎饼由一系列高层次的行动组成,如和面,加蛋,入锅等。人类能够通过对这些已经学会的部分进行排序来快速学习新的任务,即使这个任务可能需要数百万个的低级动作,如肌肉收缩等。
另一方面,现在的强化学习方法是通过对低级别行动的暴力搜索来进行的,它需要大量的尝试来解决新的任务。当你需要处理拥有大量时间步的任务时,这种方法效率极低。
我们的解决方案是基于分成强化学习的思想,智能体将复杂的操作表示为一个高级操作的简短序列。这样我们的智能体可以解决更难的任务:尽管解决方案可能需要2000个低级别的操作,但分成策略将其转换为10个高级操作的序列,这比搜索2000步序列效率高多了。
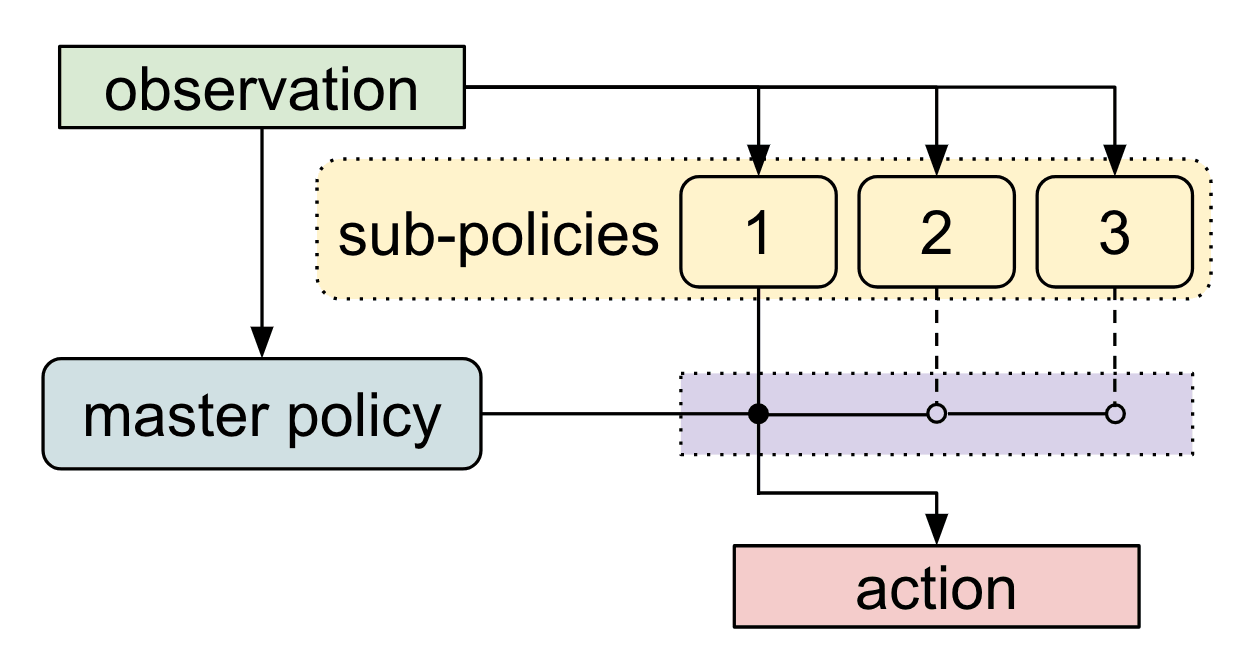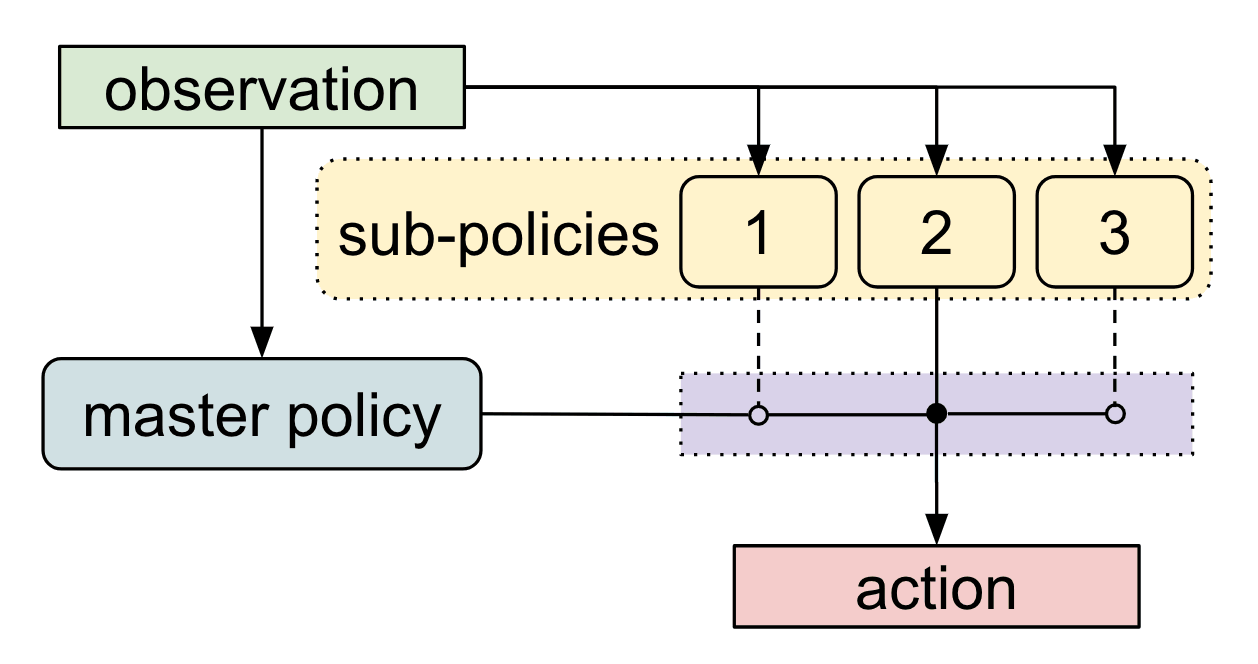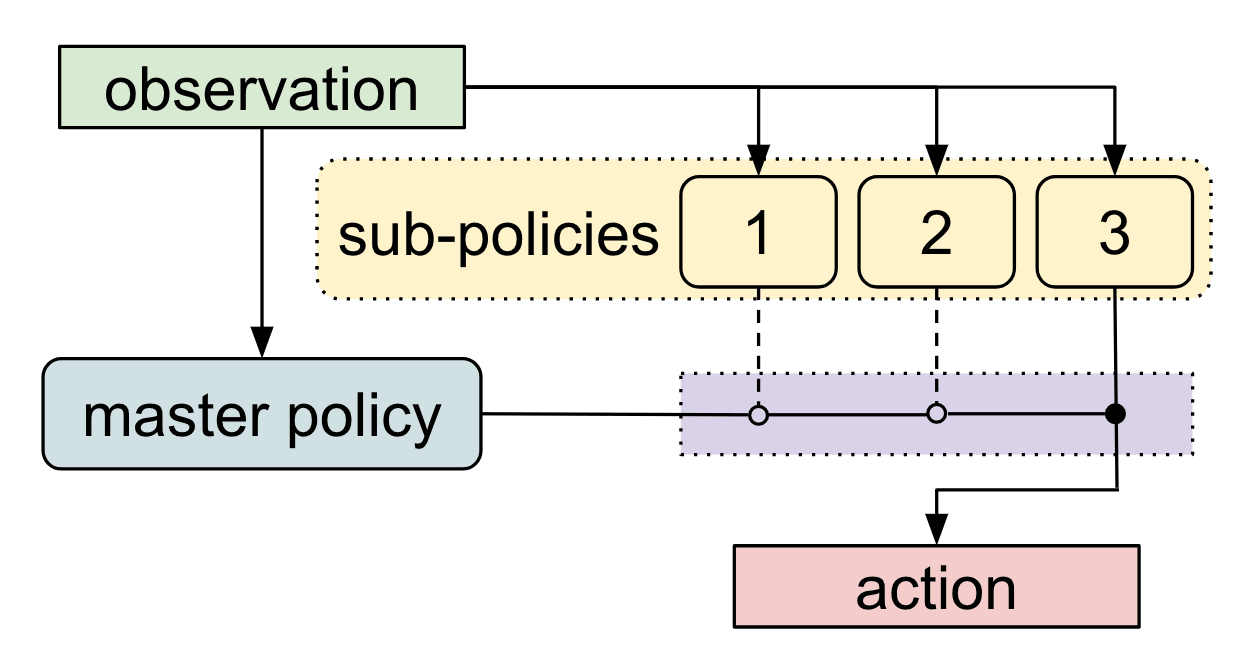
我们的算法,元学习共享分层(MLSH)学习了主策略在一组子策略之间切换的分层策略。主策略每N个时间步长选择一个动作,我们假设N = 200。执行N个时间步的子策略构成高级动作,就我们的导航任务而言,子策略对应于不同方向的爬行。
在以前的大多数工作中,分层政策都被明确地手工设计。而我们的目标是通过与环境的交互自动发现这种分层结构。从元学习的角度来看,我们定义一个好的分层结构可以很快的在未知的任务上获得高回报。因此,MLSH算法是在学习在未知的任务中实现快速学习的子策略。
我们对任务分配进行训练,在每个抽样任务学习新的主策略时共享子策略。通过反复训练新的主策略,这个过程会自动查找适应主策略学习动态的子策略。
[video width="1280" height="640" mp4="https://www.atyun.com/uploadfile/2017/10/dfgh.mp4"][/video]
经过一夜之后,经过训练的智能体解决了九个不同的迷宫,发现了与向上,向右和向下运动相对应的子策略,然后自己导航走出了迷宫。
在我们的AntMaze环境中,Mujoco Ant机器人被放置在9个不同的迷宫中,要求它必须独立从入口走到出口。我们的算法能够成功地找到一组不同的子策略,这些子策略可以通过与环境的交互来解决迷宫任务。然后可以使用这组子策略来完成更大的任务。
[video width="1280" height="720" mp4="https://www.atyun.com/uploadfile/2017/10/tyui.mp4"][/video]
代码:https://github.com/openai/mlsh
[video width="1280" height="640" mp4="https://www.atyun.com/uploadfile/2017/10/videoplayback-5.mp4"][/video]
人类解决复杂挑战的方法是将它分解成很多小的易于控制的部分。例如,煎饼由一系列高层次的行动组成,如和面,加蛋,入锅等。人类能够通过对这些已经学会的部分进行排序来快速学习新的任务,即使这个任务可能需要数百万个的低级动作,如肌肉收缩等。
另一方面,现在的强化学习方法是通过对低级别行动的暴力搜索来进行的,它需要大量的尝试来解决新的任务。当你需要处理拥有大量时间步的任务时,这种方法效率极低。
我们的解决方案是基于分成强化学习的思想,智能体将复杂的操作表示为一个高级操作的简短序列。这样我们的智能体可以解决更难的任务:尽管解决方案可能需要2000个低级别的操作,但分成策略将其转换为10个高级操作的序列,这比搜索2000步序列效率高多了。
元学习共享分层
我们的算法,元学习共享分层(MLSH)学习了主策略在一组子策略之间切换的分层策略。主策略每N个时间步长选择一个动作,我们假设N = 200。执行N个时间步的子策略构成高级动作,就我们的导航任务而言,子策略对应于不同方向的爬行。
在以前的大多数工作中,分层政策都被明确地手工设计。而我们的目标是通过与环境的交互自动发现这种分层结构。从元学习的角度来看,我们定义一个好的分层结构可以很快的在未知的任务上获得高回报。因此,MLSH算法是在学习在未知的任务中实现快速学习的子策略。
我们对任务分配进行训练,在每个抽样任务学习新的主策略时共享子策略。通过反复训练新的主策略,这个过程会自动查找适应主策略学习动态的子策略。
实验
[video width="1280" height="640" mp4="https://www.atyun.com/uploadfile/2017/10/dfgh.mp4"][/video]
经过一夜之后,经过训练的智能体解决了九个不同的迷宫,发现了与向上,向右和向下运动相对应的子策略,然后自己导航走出了迷宫。
在我们的AntMaze环境中,Mujoco Ant机器人被放置在9个不同的迷宫中,要求它必须独立从入口走到出口。我们的算法能够成功地找到一组不同的子策略,这些子策略可以通过与环境的交互来解决迷宫任务。然后可以使用这组子策略来完成更大的任务。
[video width="1280" height="720" mp4="https://www.atyun.com/uploadfile/2017/10/tyui.mp4"][/video]
在单独的迷宫环境下进行训练,可以自动学习子策略来解决任务。
代码:https://github.com/openai/mlsh

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消