












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






不用P图软件,TensorFlow pix2pix也能帮你打造出六块腹肌!
2017年10月18日 由 yining 发表
597454
0
可视化结果是十分强大的。然而,在健身领域,要想清楚地看到未来的锻炼结果往往是很困难的。我们是否可以利用深度学习让人们更接近他们的个人健康目标,从而帮助他们设想未来的结果?
gan的网络
2014年,Ian Goodfellow和其他一些人在蒙特利尔实验室首次提出了生成对抗网络(Generative Adversarial Networks),从那时起,他们就受到了很大的关注,因为他们说:
生成模型是一种无监督的学习技能,它试图学习一些数据的分布(如语料库中的文字或在一张图片中物体的像素大小)。
生成对抗网络包含两个有相反目标的网络,以某种游戏的形式在它们之中寻求平衡。“生成器(Generator)”将一些采样于所谓的“潜在的空间(latent space)”的输入转换。“鉴别器(Discriminator)”只是一个分类器,它接收来自生成器和真实对象的输出,然后接受训练,以确定它所观察的输入是生成的还是真实的。
其基本思想是,当两个网络的性能都达到最佳时,生成器就会创建在各自的输出空间内分布的图像,就像鉴别器的实际输入一样。
一些流行的对抗网络架构是:
关于生成对抗网络的一套全面的资源:https://github.com/nightrome/really-awesome-gan
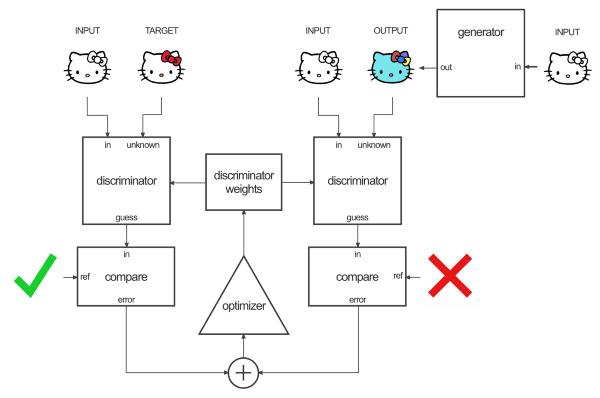
这里有一个关于鉴别器的图表概述:
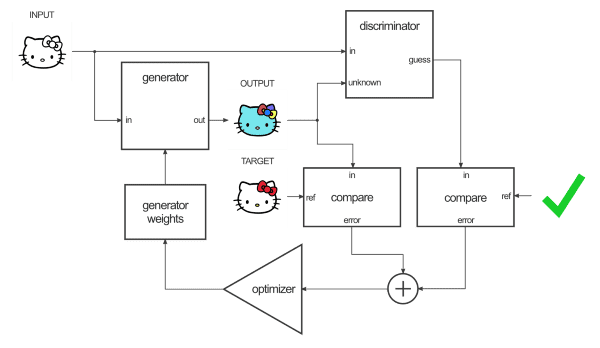
生成器的图表概述:
我们的实现
我们选择用一个有条件的生成对抗网络,学习成人男性在身材转换之间的映射。然后,我选择使用FloydHub而不是AWS EC2或谷歌云来计算和存储我的网络的调整权重,原因有很多:
装载数据:https://docs.floydhub.com/guides/data/mounting_data/
在FloydHub里运行着pix2pix的Tensorflow实现,需要对代码进行一些细微的调整,我将在这里详细说明,希望将来任何尝试类似项目的人都可以节省一些时间。
一个典型的训练命令,可以spin up一个FloydHub的云GPU训练服务器,看起来像下面这样:
Christopher Hesse的pix2pix实现是在Tensorflow 1.0.0中进行的,这意味着现在已经有的
此外,你应该意识到这一点,而不是从单一的
 为什么这会成为一个问题? 因为在pix2pix.py中的第625行和725行中,使用tf.train.latest_checkpoint(a.checkpoint)来恢复对saver的参数,这将产生一个在FloydHub上的
为什么这会成为一个问题? 因为在pix2pix.py中的第625行和725行中,使用tf.train.latest_checkpoint(a.checkpoint)来恢复对saver的参数,这将产生一个在FloydHub上的
因为在接下来在FloudHub工作中,检查点目录在后面的工作中不能被装载到/output中,该目录将被保留,当试图恢复模型时,会产生一个错误。
解决方法非常简单。对于一个更复杂的项目,我建议添加一个可以在命令中设置的附加参数,你可以简单地改变pix2pix.py中的第625行和725行:
例如,如果我要测试或导出一个名为model-99200的模型,只需将checkpoint = tf.train.latest_checkpoint(a.checkpoint)与checkpoint = r'/model/model-99200'替换,然后确保将数据装载在FloydHub上。
现在你应该能够测试训练过的模型了:
请注意值传递到--data和--checkpoint参数。
另一个无需修改代码的快速解决方案是在运行推断之前预先填充输出目录,并使用预先训练过的检查点。
结果可视化
成年男性的身材前后转换图像的映射有多成功呢? 看下图:
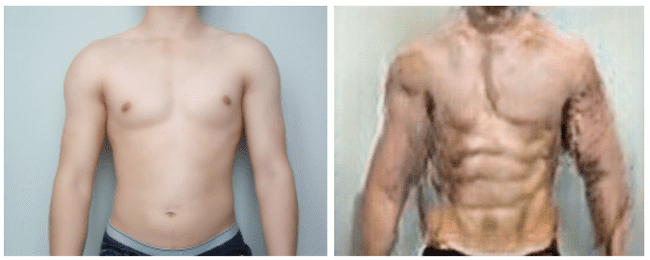
呵,不完全逼真的效果。但是考虑到我们只有不到150张训练图片,这些结果可能并不是那么糟糕!我使用了两种标准的数据扩充:随机剪裁和水平反射。我们也将之前的图像与未反射的之后的图像进行了配对,反之亦然,但是我们没有时间来测试这一改进的泛化是否仅仅是在反射和非反射图像之中相互配对的。这对于未来的项目来说是很有帮助的。
数据增强显然改善了我们的结果——下面是一些使用增强数据(下行)训练的模型,和没有使用增强数据的模型(上行):
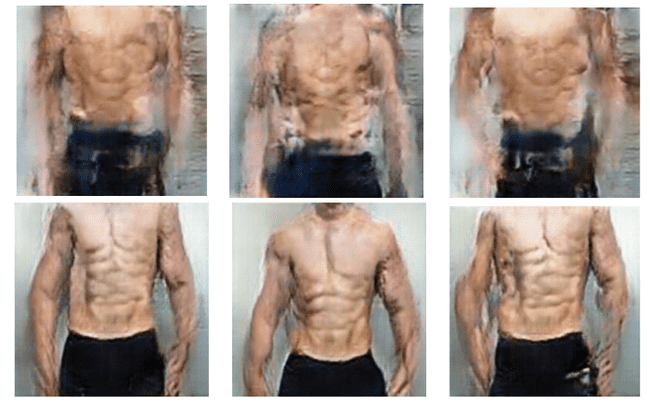
训练这些模型可能还不够让它们完全收敛,但结果却很吸引人。我认为这些低保真生成的图像是一个像样的概念验证,生成对抗网络可以使用更大的数据集来进行商业应用。
我们的想法是:采用有条件的生成对抗网络(GANs),虚构出一张一个人在经过健康饮食和锻炼的情况下未来的身材变化的图片。结果如下:在这篇文章中,我将简要地介绍一下生成对抗网络。然后,我会提供一些指导,用于训练一个TensorFlow实现的模型,该模型使用GPU训练和部署平台FloydHub。
gan的网络
2014年,Ian Goodfellow和其他一些人在蒙特利尔实验室首次提出了生成对抗网络(Generative Adversarial Networks),从那时起,他们就受到了很大的关注,因为他们说:
…在过去的10年里,最有趣的想法是进行机器学习。
生成模型是一种无监督的学习技能,它试图学习一些数据的分布(如语料库中的文字或在一张图片中物体的像素大小)。
生成对抗网络包含两个有相反目标的网络,以某种游戏的形式在它们之中寻求平衡。“生成器(Generator)”将一些采样于所谓的“潜在的空间(latent space)”的输入转换。“鉴别器(Discriminator)”只是一个分类器,它接收来自生成器和真实对象的输出,然后接受训练,以确定它所观察的输入是生成的还是真实的。
其基本思想是,当两个网络的性能都达到最佳时,生成器就会创建在各自的输出空间内分布的图像,就像鉴别器的实际输入一样。
一些流行的对抗网络架构是:
- 深度卷积生成对抗网络(Deep Convolutional GANs),用来生成真实的图像。
- 有条件的生成对抗网络(Conditional GANs),它学习了输出图像的分布,给出了对应用程序的成对输入,例如,图像与图像之间的转换。
- 循环一致的生成对抗网络(Cycle-Consistent GANs),它可以在不需要成对输入的情况下学习图像与图像之间的映射。
关于生成对抗网络的一套全面的资源:https://github.com/nightrome/really-awesome-gan
这里有一个关于鉴别器的图表概述:
生成器的图表概述:
我们的实现
我们选择用一个有条件的生成对抗网络,学习成人男性在身材转换之间的映射。然后,我选择使用FloydHub而不是AWS EC2或谷歌云来计算和存储我的网络的调整权重,原因有很多:
- 只需少数的几个简单的shell命令,在无需处理FTP的情况下,装载数据(mount data)的处理在FloydHub上是非常简单的。
- 在无需请求或下载这些日志的情况下,日志与
floyd-clicommand-line工具或者FloydHub网络仪表盘可以随时使用,并且操作十分容易。 - 定价有竞争力。
装载数据:https://docs.floydhub.com/guides/data/mounting_data/
在FloydHub里运行着pix2pix的Tensorflow实现,需要对代码进行一些细微的调整,我将在这里详细说明,希望将来任何尝试类似项目的人都可以节省一些时间。
一个典型的训练命令,可以spin up一个FloydHub的云GPU训练服务器,看起来像下面这样:
floyd run --gpu --data rayheberer/datasets/dreamfit/4:/dreamfit_data 'python pix2pix.py --mode
train --output_dir /output --max_epochs 200 --input_dir /dreamfit_data --which_direction AtoB
- --data path:/dir装载了一个FloydHub数据集,并且使它在/dir上是可用的。
- 保存输出,例如模型检查点(checkpoint),必须总是被储存到/output(这是一个重要的细节)。
Christopher Hesse的pix2pix实现是在Tensorflow 1.0.0中进行的,这意味着现在已经有的
save_relative_pathsoption对tf.train.saver还没有实现。此外,你应该意识到这一点,而不是从单一的
.ckptfile中恢复。该模型将许多文件保存在训练期间指定的输出目录中,然后在测试或导出过程中选择作为检查点目录。为什么这会成为一个问题? 因为在pix2pix.py中的第625行和725行中,使用tf.train.latest_checkpoint(a.checkpoint)来恢复对saver的参数,这将产生一个在FloydHub上的/output绝对路径。因为在接下来在FloudHub工作中,检查点目录在后面的工作中不能被装载到/output中,该目录将被保留,当试图恢复模型时,会产生一个错误。
解决方法非常简单。对于一个更复杂的项目,我建议添加一个可以在命令中设置的附加参数,你可以简单地改变pix2pix.py中的第625行和725行:
例如,如果我要测试或导出一个名为model-99200的模型,只需将checkpoint = tf.train.latest_checkpoint(a.checkpoint)与checkpoint = r'/model/model-99200'替换,然后确保将数据装载在FloydHub上。
现在你应该能够测试训练过的模型了:
floyd run --gpu --data rayheberer/projects/burda-gan/6/output:/model 'python pix2pix.py --mode
test --output_dir /output --input_dir test --checkpoint /model'
请注意值传递到--data和--checkpoint参数。
另一个无需修改代码的快速解决方案是在运行推断之前预先填充输出目录,并使用预先训练过的检查点。
floyd run --gpu --data rayheberer/projects/burda-gan/6/output:/model 'cp /model/* /output;
python pix2pix.py --mode test --output_dir /output --input_dir test --checkpoint /model'
结果可视化
成年男性的身材前后转换图像的映射有多成功呢? 看下图:
呵,不完全逼真的效果。但是考虑到我们只有不到150张训练图片,这些结果可能并不是那么糟糕!我使用了两种标准的数据扩充:随机剪裁和水平反射。我们也将之前的图像与未反射的之后的图像进行了配对,反之亦然,但是我们没有时间来测试这一改进的泛化是否仅仅是在反射和非反射图像之中相互配对的。这对于未来的项目来说是很有帮助的。
数据增强显然改善了我们的结果——下面是一些使用增强数据(下行)训练的模型,和没有使用增强数据的模型(上行):
训练这些模型可能还不够让它们完全收敛,但结果却很吸引人。我认为这些低保真生成的图像是一个像样的概念验证,生成对抗网络可以使用更大的数据集来进行商业应用。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消