












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






自动驾驶:使用自动驾驶预测汽车的转向角度
2017年09月29日 由 xiaoshan.xiang 发表
609211
0
近年来,特别是在10年前Darpa挑战赛成功之后,全自动驾驶汽车的开发速度大大加快。自动驾驶汽车由许多部件组成,其中最关键的部件是驱动它的传感器和人工智能软件。此外,随着计算能力的增加,我们现在能够训练复杂的和深层的神经网络,该神经网络能够学习关键的细节,并且成为汽车的大脑,了解汽车的环境,以便做出下一个决定。
在这篇文章中,我们将讨论如何训练一个深度学习模型来预测方向盘转角,并帮助虚拟汽车在模拟器中自动驾驶。该模型使用Keras(https://keras.io/)创建,使用Tensorflow(https://www.tensorflow.org/)作为后端。
对于该项目,我们提供了一个以Unity为基础的模拟器,它有两种模式:
数据日志保存在csv文件中,包含了图像路径,以及方向盘转角、油门和速度。我们只关心这个项目的方向盘转角和图像。
如下图所示,模拟器包含两条轨道。右边的轨道(轨道2)比轨道1难度更大,因为它包含斜坡和急转弯。

这个项目实际上是受NVIDIA研究员的论文“自动驾驶汽车的端到端学习”(https://arxiv.org/abs/1604.07316)的启发,这篇论文通过训练一个卷积神经网络使汽车自动驾驶,根据转向角度数据和三个相机(左、中、右)拍摄的图像,预测方向盘转角。经过训练的模型只用中央相机就能够精确地驾驶汽车。下图显示了创建这样一个高效模型的过程。
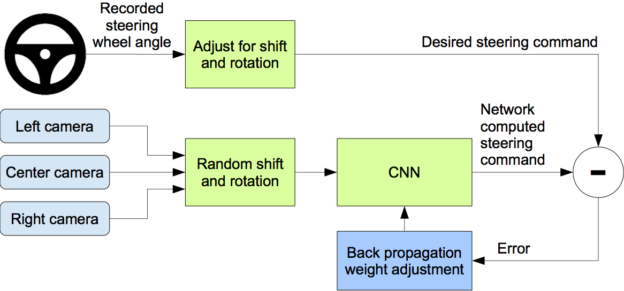
与英伟达正在做的真实的自动驾驶不同,我们的汽车在模拟器中驾驶。不管怎样,同样的原则也应该适用。我们在这方面得到了进一步的支持,这要归功于最近对“仿真在如何在Waymo(https://www.theatlantic.com/technology/archive/2017/08/inside-waymos-secret-testing-and-simulation-facilities/537648/)等公司的自动驾驶技术的发展中发挥关键作用”的相关报道。
我们使用了4个数据集:
请注意,在所有手动创建的数据集中,我们在两个方向上驱动,以帮助我们的模型通用化。
然而,在分析了我们的数据集所捕获的转向角后,我们很快意识到一个问题:我们的数据非常不平衡,有大量的方向盘角度数据是中性的(即0)。这意味着,除非我们采取矫正措施,否则我们的模型将会倾向于直线行驶。
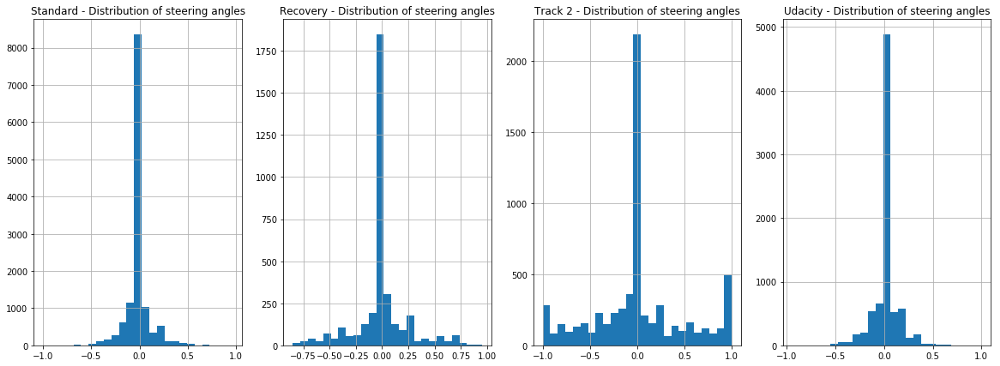
轨道2上的数据显示了许多急剧变化的变化,这正是我们所期望的。但即使是在这种情况下,模型仍倾向于直线行驶。
最后,我们决定创建一个集成训练数据集,该数据集由Udacity数据集、恢复数据集和轨道2的数据集组成。我们决定使用来自轨道1的标准数据集作为验证集。
这帮助我们从55K的训练图像和潜在的44K的验证图像开始。
我们有很多数据点,但不幸的是,大多数的数据显示,我们的汽车以一个中性的方向盘转角行驶,我们的汽车将倾向于直线行驶。下面的例子展示了我们的第一个模型,该模型没有平衡训练数据集:

此外,在轨道上也有阴影,可能会使模型陷入混乱。该模型还需要学会正确驾驶,无论汽车在道路的左边或右边。因此,我们必须找到一种方法来人为地增加和改变我们的图像和转向角度。为此,我们致力于数据增长技术。
首先,我们添加了一个转向角校准,以抵消左右相机捕捉到的图像:
上面的数值是根据经验选择的。
因为我们想让我们的汽车在道路上的任何位置,都能自主驾驶,所以我们对图像的比例进行左右反转,并且自然地逆转原始的转向角度。

由于阴影或其他原因,轨道的某些部分变暗,我们还通过将所有RGB颜色通道乘以一个从范围中随机选取的标量,以使我们的一部分图像变暗。

因为偶尔会有阴影覆盖的轨迹,我们也必须训练我们的模型来识别它们。

为了对抗大量的中性角度,并为数据集提供更多的多样性,我们对图像进行随机移动,并在每个像素横向移动的方向上添加一个给定的偏移量。在我们的案例中,我们根据经验决定在每个像素向左或向右移动时增加(或减去)0.0035。向上/向下移动图像会使模型相信它在向上/向下倾斜。从实验中我们可以知道,这些侧向位移可能是使汽车正常驾驶所需的最重要的增长。
我们的图像增长函数很简单:每个提供的图像都经过一系列的增长,每一个发生概率p在0到1之间的。所有增长图像的代码都被委托给了上面所示的适当的增长函数。
由于我们在训练模型的过程中产生了新的和增长的图像,所以我们创建了一个kera生成器来在每个批处理中生成新的图像。
请注意,我们有能力降低一定比例的中性角,并保持(即不增加)每批图像的比例。
下面展示了一小部分批量的增长图像:

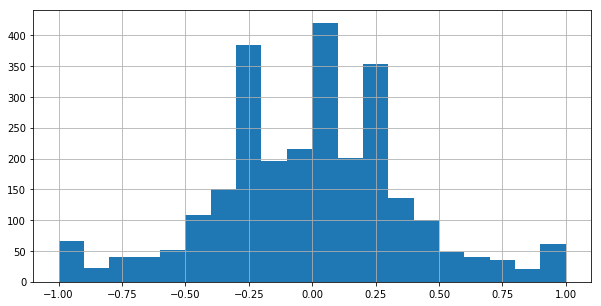
此外,这些增强图像的转向角度的直方图显示了更多的平衡。
我们最初尝试了VGG架构的一种变体,它的层次较低,并且没有转移学习,但它能得到令人满意的结果。最终,我们选定了NVIDIA论文中使用的架构,因为它能得到最好的结果。
我们在模型上添加了一些细微的调整:
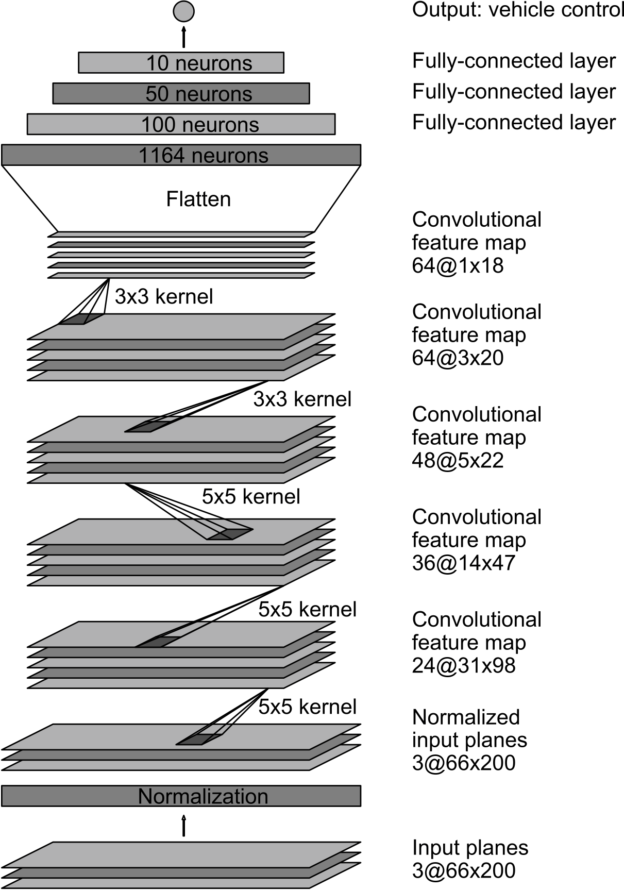
该模型的完整架构如下:
在所有层中使用的激活函数,除了最后一个,都是ReLU(https://stats.stackexchange.com/questions/226923/why-do-we-use-relu-in-neural-networks-and-how-do-we-use-it)。我们也尝试了ELU,但使用ReLU + BatchNormalization能得到更好的结果。我们利用输出层的均方误差激活,因为这是一个回归问题,而不是一个分类问题。
如上所述,我们使用了BatchNormalization 来加速收敛。我们确实尝试了某种程度的Dropout(https://www.quora.com/What-does-a-dropout-in-neural-networks-mean),但没有发现任何明显的差异。我们相信,我们在每一批中都产生了新的图像,并且丢弃了一些中性角度的图像,这将有助于减少过度拟合。此外,我们没有将任何MaxPool(http://cs231n.github.io/convolutional-networks/#pool)操作应用到我们的NVIDIA网络(尽管我们尝试用VGG启发了一个),因为它需要架构上的重大更改,因为我们更早地减少了维度。此外,我们没有时间用L2规范化进行试验,但计划在未来尝试它。
我们使用Adam(https://www.quora.com/Can-you-explain-basic-intuition-behind-ADAM-a-method-for-stochastic-optimization)作为优化器来训练模型,学习率为0.001。经过多次调整参数和多模型试验之后,我们最终得到了一能够让我们的虚拟汽车在两个轨道上自动驾驶的能力。

我们可以看到,汽车如何设法沿着轨道2的陡峭的斜坡向下行驶。

我们还展示了前置摄像头在轨道2上自动驾驶时看到的情况。我们可以看到汽车是如何坚持在车道上而不是在中间行驶的,因为我们在数据收集阶段,汽车只在道路的一侧行驶。这表明模型确实学会了保持在自己的车道内。

更重要的是,我甚至为你制作了一段视频剪辑,把Grid作为背景音乐。(https://www.youtube.com/watch?v=0lxHpVUJ5U0&feature=youtu.be)
[video width="1280" height="720" mp4="https://www.atyun.com/uploadfile/2017/09/11.mp4"][/video]
我们已经证明,通过深度神经网络和大量的数据增长技术建立一个模型,可以可靠地预测汽车的方向盘转角。虽然我们取得了令人鼓舞的结果,但我们希望未来可以探索以下几点:
我们可以探索许多领域,以进一步推动这个项目,取得更令人信服的结果。这个项目最重要的就是数据:如果没有这些图像和转向角,以及它们潜在的无限扩展,我们就无法建立足够稳健的模型。
这个项目是迄今为止最困难的项目,通过该项目能够获得更多的实践经验,包括超参数调整、数据增强和其他重要概念之间的数据集平衡。也可以加深对神经网络架构的理解。
在这篇文章中,我们将讨论如何训练一个深度学习模型来预测方向盘转角,并帮助虚拟汽车在模拟器中自动驾驶。该模型使用Keras(https://keras.io/)创建,使用Tensorflow(https://www.tensorflow.org/)作为后端。
项目设置
对于该项目,我们提供了一个以Unity为基础的模拟器,它有两种模式:
- 训练模式:我们手动驾驶汽车,收集数据;
- 自动模式:汽车以从收集的数据中训练出来的模型为基础进行自驾。
数据日志保存在csv文件中,包含了图像路径,以及方向盘转角、油门和速度。我们只关心这个项目的方向盘转角和图像。
如下图所示,模拟器包含两条轨道。右边的轨道(轨道2)比轨道1难度更大,因为它包含斜坡和急转弯。
这个项目实际上是受NVIDIA研究员的论文“自动驾驶汽车的端到端学习”(https://arxiv.org/abs/1604.07316)的启发,这篇论文通过训练一个卷积神经网络使汽车自动驾驶,根据转向角度数据和三个相机(左、中、右)拍摄的图像,预测方向盘转角。经过训练的模型只用中央相机就能够精确地驾驶汽车。下图显示了创建这样一个高效模型的过程。
与英伟达正在做的真实的自动驾驶不同,我们的汽车在模拟器中驾驶。不管怎样,同样的原则也应该适用。我们在这方面得到了进一步的支持,这要归功于最近对“仿真在如何在Waymo(https://www.theatlantic.com/technology/archive/2017/08/inside-waymos-secret-testing-and-simulation-facilities/537648/)等公司的自动驾驶技术的发展中发挥关键作用”的相关报道。
数据集
我们使用了4个数据集:
- Udacity在轨道1上的数据集;
- 在轨道1上手动创建的数据集(我们将其命名为标准数据集);
- 另一个在轨道1上手动创建的数据集,这个数据集记录了我们开车接近边界的数据,然后重新训练这个模型如何避免超出范围——在现实世界中,这将被称为鲁莽或酒后驾驶;
- 在轨道2上手动创建的数据集。
请注意,在所有手动创建的数据集中,我们在两个方向上驱动,以帮助我们的模型通用化。
数据集探索
然而,在分析了我们的数据集所捕获的转向角后,我们很快意识到一个问题:我们的数据非常不平衡,有大量的方向盘角度数据是中性的(即0)。这意味着,除非我们采取矫正措施,否则我们的模型将会倾向于直线行驶。
轨道2上的数据显示了许多急剧变化的变化,这正是我们所期望的。但即使是在这种情况下,模型仍倾向于直线行驶。
数据集分割
最后,我们决定创建一个集成训练数据集,该数据集由Udacity数据集、恢复数据集和轨道2的数据集组成。我们决定使用来自轨道1的标准数据集作为验证集。
frames = [recovery_csv, udacity_csv, track2_csv]
ensemble_csv = pd.concat(frames)
validation_csv = standard_csv
这帮助我们从55K的训练图像和潜在的44K的验证图像开始。
数据增长
我们有很多数据点,但不幸的是,大多数的数据显示,我们的汽车以一个中性的方向盘转角行驶,我们的汽车将倾向于直线行驶。下面的例子展示了我们的第一个模型,该模型没有平衡训练数据集:
此外,在轨道上也有阴影,可能会使模型陷入混乱。该模型还需要学会正确驾驶,无论汽车在道路的左边或右边。因此,我们必须找到一种方法来人为地增加和改变我们的图像和转向角度。为此,我们致力于数据增长技术。
摄像机和转向角校准
首先,我们添加了一个转向角校准,以抵消左右相机捕捉到的图像:
- 对于左边的相机,我们想让汽车转向右边(正偏移);
- 对于右边的的相机,我们希望汽车转向左边(负偏移)。
st_angle_names = ["Center", "Left", "Right"]
st_angle_calibrations = [0, 0.25, -0.25]
上面的数值是根据经验选择的。
图像左右反转
因为我们想让我们的汽车在道路上的任何位置,都能自主驾驶,所以我们对图像的比例进行左右反转,并且自然地逆转原始的转向角度。
def fliph_image(img):
"""
Returns a horizontally flipped image
"""
return cv2.flip(img, 1)
变暗的图像
由于阴影或其他原因,轨道的某些部分变暗,我们还通过将所有RGB颜色通道乘以一个从范围中随机选取的标量,以使我们的一部分图像变暗。
def change_image_brightness_rgb(img, s_low=0.2, s_high=0.75):
"""
Changes the image brightness by multiplying all RGB values by the same scalacar in [s_low, s_high).
Returns the brightness adjusted image in RGB format.
"""
img = img.astype(np.float32)
s = np.random.uniform(s_low, s_high)
img[:,:,:] *= s
np.clip(img, 0, 255)
return img.astype(np.uint8)
随机阴影
因为偶尔会有阴影覆盖的轨迹,我们也必须训练我们的模型来识别它们。
def add_random_shadow(img, w_low=0.6, w_high=0.85):
"""
Overlays supplied image with a random shadow polygon
The weight range (i.e. darkness) of the shadow can be configured via the interval [w_low, w_high)
"""
cols, rows = (img.shape[0], img.shape[1])
top_y = np.random.random_sample() * rows
bottom_y = np.random.random_sample() * rows
bottom_y_right = bottom_y + np.random.random_sample() * (rows - bottom_y)
top_y_right = top_y + np.random.random_sample() * (rows - top_y)
if np.random.random_sample() <= 0.5:
bottom_y_right = bottom_y - np.random.random_sample() * (bottom_y)
top_y_right = top_y - np.random.random_sample() * (top_y)
poly = np.asarray([[ [top_y,0], [bottom_y, cols], [bottom_y_right, cols], [top_y_right,0]]], dtype=np.int32)
mask_weight = np.random.uniform(w_low, w_high)
origin_weight = 1 - mask_weight
mask = np.copy(img).astype(np.int32)
cv2.fillPoly(mask, poly, (0, 0, 0))
#masked_image = cv2.bitwise_and(img, mask)
return cv2.addWeighted(img.astype(np.int32), origin_weight, mask, mask_weight, 0).astype(np.uint8)
左/右/上/下移动图像
为了对抗大量的中性角度,并为数据集提供更多的多样性,我们对图像进行随机移动,并在每个像素横向移动的方向上添加一个给定的偏移量。在我们的案例中,我们根据经验决定在每个像素向左或向右移动时增加(或减去)0.0035。向上/向下移动图像会使模型相信它在向上/向下倾斜。从实验中我们可以知道,这些侧向位移可能是使汽车正常驾驶所需的最重要的增长。
# Read more about it here: http://docs.opencv.org/3.0-beta/doc/py_tutorials/py_imgproc/py_geometric_transformations/py_geometric_transformations.html
def translate_image(img, st_angle, low_x_range, high_x_range, low_y_range, high_y_range, delta_st_angle_per_px):
"""
Shifts the image right, left, up or down.
When performing a lateral shift, a delta proportional to the pixel shifts is added to the current steering angle
"""
rows, cols = (img.shape[0], img.shape[1])
translation_x = np.random.randint(low_x_range, high_x_range)
translation_y = np.random.randint(low_y_range, high_y_range)
st_angle += translation_x * delta_st_angle_per_px
translation_matrix = np.float32([[1, 0, translation_x],[0, 1, translation_y]])
img = cv2.warpAffine(img, translation_matrix, (cols, rows))
return img, st_angle

图像增长管道
我们的图像增长函数很简单:每个提供的图像都经过一系列的增长,每一个发生概率p在0到1之间的。所有增长图像的代码都被委托给了上面所示的适当的增长函数。
def augment_image(img, st_angle, p=1.0):
"""
Augment a given image, by applying a series of transformations, with a probability p.
The steering angle may also be modified.
Returns the tuple (augmented_image, new_steering_angle)
"""
aug_img = img
if np.random.random_sample() <= p:
aug_img = fliph_image(aug_img)
st_angle = -st_angle
if np.random.random_sample() <= p:
aug_img = change_image_brightness_rgb(aug_img)
if np.random.random_sample() <= p:
aug_img = add_random_shadow(aug_img, w_low=0.45)
if np.random.random_sample() <= p:
aug_img, st_angle = translate_image(aug_img, st_angle, -60, 61, -20, 21, 0.35/100.0)
return aug_img, st_angle
Keras图像生成器
由于我们在训练模型的过程中产生了新的和增长的图像,所以我们创建了一个kera生成器来在每个批处理中生成新的图像。
def generate_images(df, target_dimensions, img_types, st_column, st_angle_calibrations, batch_size=100, shuffle=True,
data_aug_pct=0.8, aug_likelihood=0.5, st_angle_threshold=0.05, neutral_drop_pct=0.25):
"""
Generates images whose paths and steering angle are stored in the supplied dataframe object df
Returns the tuple (batch,steering_angles)
"""
# e.g. 160x320x3 for target_dimensions
batch = np.zeros((batch_size, target_dimensions[0], target_dimensions[1], target_dimensions[2]), dtype=np.float32)
steering_angles = np.zeros(batch_size)
df_len = len(df)
while True:
k = 0
while k < batch_size:
idx = np.random.randint(0, df_len)
for img_t, st_calib in zip(img_types, st_angle_calibrations):
if k >= batch_size:
break
row = df.iloc[idx]
st_angle = row[st_column]
# Drop neutral-ish steering angle images with some probability
if abs(st_angle) < st_angle_threshold and np.random.random_sample() <= neutral_drop_pct :
continue
st_angle += st_calib
img_type_path = row[img_t]
img = read_img(img_type_path)
# Resize image
img, st_angle = augment_image(img, st_angle, p=aug_likelihood) if np.random.random_sample() <= data_aug_pct else (img, st_angle)
batch[k] = img
steering_angles[k] = st_angle
k += 1
yield batch, np.clip(steering_angles, -1, 1)
请注意,我们有能力降低一定比例的中性角,并保持(即不增加)每批图像的比例。
下面展示了一小部分批量的增长图像:
此外,这些增强图像的转向角度的直方图显示了更多的平衡。
模型
我们最初尝试了VGG架构的一种变体,它的层次较低,并且没有转移学习,但它能得到令人满意的结果。最终,我们选定了NVIDIA论文中使用的架构,因为它能得到最好的结果。
模型调整
我们在模型上添加了一些细微的调整:
- 我们裁剪了图像的顶部,以排除水平线(它在直接决定转向角时并不起作用);
- 在模型中,我们将图像大小调整为66x200,作为早期的层,以利用GPU的优势;
- 我们在每一个激活函数后应用BatchNormalization (https://www.quora.com/Why-does-batch-normalization-help)来加快收敛;
- 第二个致密层的输出大小为200,而不是100。
模型架构
该模型的完整架构如下:
- 输入图像为160x320(高度x宽度格式);
- 图像顶部垂直裁剪,剪掉一半高度(80像素),形成80x320图像;
- 裁剪图像是标准化的,以确保像素分布的均值为0;
- 使用Tensorflow的image.resize_images(https://www.tensorflow.org/api_docs/python/tf/image/resize_images)将裁剪的图像调整到66x200;
- 我们应用了一系列的3个5x5卷积层,使用2x2的步幅。每一个卷积层后面都有一个BatchNormalization操作来改善收敛性。当我们深入网络的时候,每一层的深度分别是24、36和48;
- 我们应用2个连续的3x3卷积层,深度为64。每一个卷积层后紧接着是一个BatchNormalization操作;
- 我们在这个阶段将平面化输入,然后进入完全连通的阶段;
- 我们采用一系列完全连通的层,逐渐减小尺寸:1164、200、50和10;
- 输出层的大小是1,因为我们只预测一个变量:方向盘转角。
激活和正规化
在所有层中使用的激活函数,除了最后一个,都是ReLU(https://stats.stackexchange.com/questions/226923/why-do-we-use-relu-in-neural-networks-and-how-do-we-use-it)。我们也尝试了ELU,但使用ReLU + BatchNormalization能得到更好的结果。我们利用输出层的均方误差激活,因为这是一个回归问题,而不是一个分类问题。
如上所述,我们使用了BatchNormalization 来加速收敛。我们确实尝试了某种程度的Dropout(https://www.quora.com/What-does-a-dropout-in-neural-networks-mean),但没有发现任何明显的差异。我们相信,我们在每一批中都产生了新的图像,并且丢弃了一些中性角度的图像,这将有助于减少过度拟合。此外,我们没有将任何MaxPool(http://cs231n.github.io/convolutional-networks/#pool)操作应用到我们的NVIDIA网络(尽管我们尝试用VGG启发了一个),因为它需要架构上的重大更改,因为我们更早地减少了维度。此外,我们没有时间用L2规范化进行试验,但计划在未来尝试它。
训练和结果
我们使用Adam(https://www.quora.com/Can-you-explain-basic-intuition-behind-ADAM-a-method-for-stochastic-optimization)作为优化器来训练模型,学习率为0.001。经过多次调整参数和多模型试验之后,我们最终得到了一能够让我们的虚拟汽车在两个轨道上自动驾驶的能力。
我们可以看到,汽车如何设法沿着轨道2的陡峭的斜坡向下行驶。
我们还展示了前置摄像头在轨道2上自动驾驶时看到的情况。我们可以看到汽车是如何坚持在车道上而不是在中间行驶的,因为我们在数据收集阶段,汽车只在道路的一侧行驶。这表明模型确实学会了保持在自己的车道内。
视频
更重要的是,我甚至为你制作了一段视频剪辑,把Grid作为背景音乐。(https://www.youtube.com/watch?v=0lxHpVUJ5U0&feature=youtu.be)
[video width="1280" height="720" mp4="https://www.atyun.com/uploadfile/2017/09/11.mp4"][/video]
结论
我们已经证明,通过深度神经网络和大量的数据增长技术建立一个模型,可以可靠地预测汽车的方向盘转角。虽然我们取得了令人鼓舞的结果,但我们希望未来可以探索以下几点:
- 在模型中考虑速度和油门;
- 让汽车的时速超过15 - 20英里;
- 通过迁移学习的实验模型以VGG /ResNets/ Inception为基础;
- 使用循环神经网络,如论文中使用Udacity数据集;
- 通过ai 阅读论文“驾驶模拟器”(https://arxiv.org/abs/1608.01230),并尝试实现他们的模型;
- 使用强化学习进行试验。
我们可以探索许多领域,以进一步推动这个项目,取得更令人信服的结果。这个项目最重要的就是数据:如果没有这些图像和转向角,以及它们潜在的无限扩展,我们就无法建立足够稳健的模型。
这个项目是迄今为止最困难的项目,通过该项目能够获得更多的实践经验,包括超参数调整、数据增强和其他重要概念之间的数据集平衡。也可以加深对神经网络架构的理解。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消