











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






你一定要知道!数据科学家提高工作效率的基本工具
2017年09月20日 由 xiaoshan.xiang 发表
787812
0
介绍
很多人都会有这个问题,当开始从事数据科学的时候,会被各种各样的可用工具所困扰。
虽然有一些与这个问题相关的可用指南。例如“对于不擅长编程者的19日数据科学工具(链接地址为https://www.analyticsvidhya.com/blog/2016/05/19-data-science-tools-for-people-dont-understand-coding/)”或“Python学习数据科学的完整教程(链接地址为https://www.analyticsvidhya.com/blog/2016/01/complete-tutorial-learn-data-science-python-scratch-2/)”,本文将展示在日常数据科学中我更喜欢使用的工具。
“数据科学堆栈”是什么样子?
我从事软件工程工作。人们对目前从业者正在使用的“堆栈”感到好奇。他们希望找出正在流行的工具,以及该工具在使用时表现出的优点和缺点。因为每天都有新的工具来解决人们每天面临的恼人问题。
在数据科学中,你应该更倾向于使用哪种技术来解决问题,而不是使用工具。不过,还是要了解哪些工具是可用的。有一份相关的调查总结(链接地址为https://becomingadatascientist.wordpress.com/2013/07/26/choosing-a-data-science-technology-stack-w-survey/)。

深度学习问题的案例研究:从Python生态系统开始
我将用一个实际的示例给你介绍这些工具,而不是直接地说要使用哪些工具。我们将在“识别数字(链接地址为https://datahack.analyticsvidhya.com/contest/practice-problem-identify-the-digits/)”练习问题上做这个练习。
我们首先要了解的是需要解决的问题是什么。首页提到“在这里,我们需要在给定图像中识别数字。我们总共有7万张图片,其中49000张是用数字标记的训练图像的一部分,剩下的21000张图片没有标记(称为测试图像)。现在,我们需要确定测试图像的数字”。
实际上这意味着该问题是图像识别问题。第一步是设置问题的系统。我通常为每个问题我开始创建一个特定的文件夹结构(yes I’m windows用户�),首先从这里开始工作
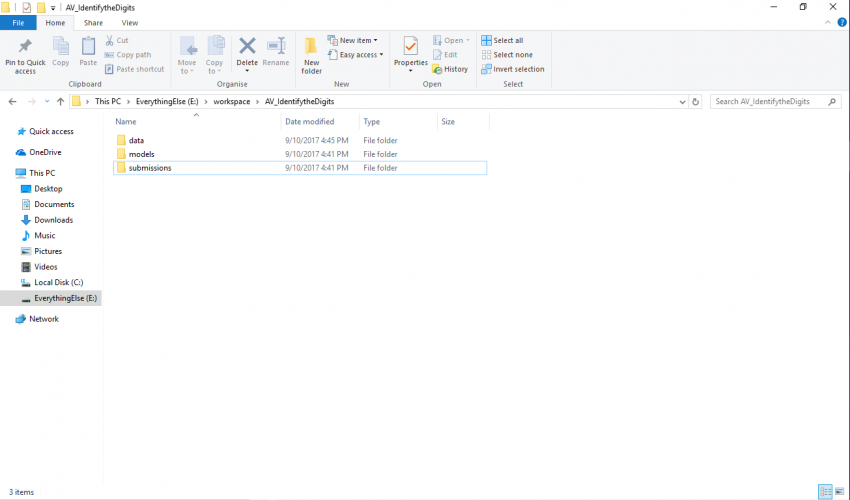
对于这类问题,我倾向于使用以下工具包:
- python3:用于启动
- Numpy / Scipy:用于基本数据的读取和处理
- Pandas:用于构造数据,并将其呈形状进行处理
- Matplotlib:用于数据可视化
- scikit- learn / Tensorflow / Keras:用于预测模型
幸运的是,上面的大部分内容都可以使用一个名为Anaconda的软件读取。我习惯使用Anaconda(链接地址为https://www.anaconda.com/),因为它具有数据科学包的全面性和易用性。
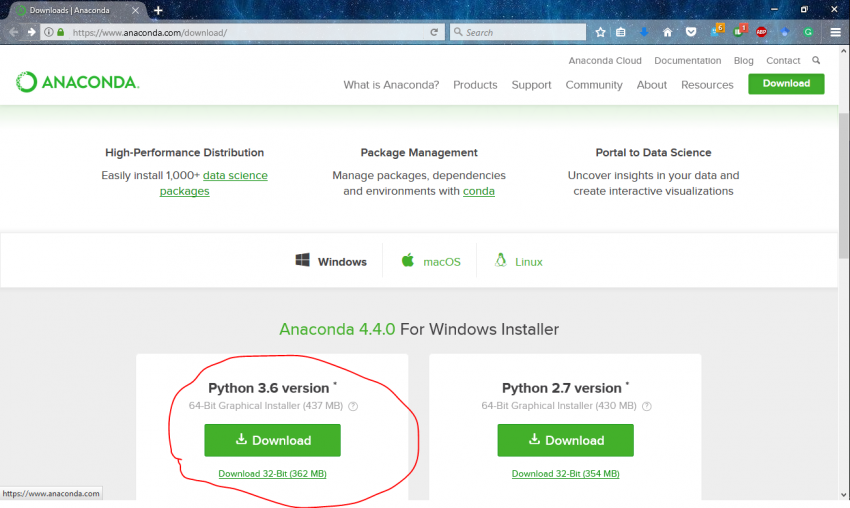
要在系统中设置anaconda,只需下载适当的平台版本(链接地址为https://www.anaconda.com/download/)。更具体地说,我有适用于anaconda 4.4.0的python 3.6版本。
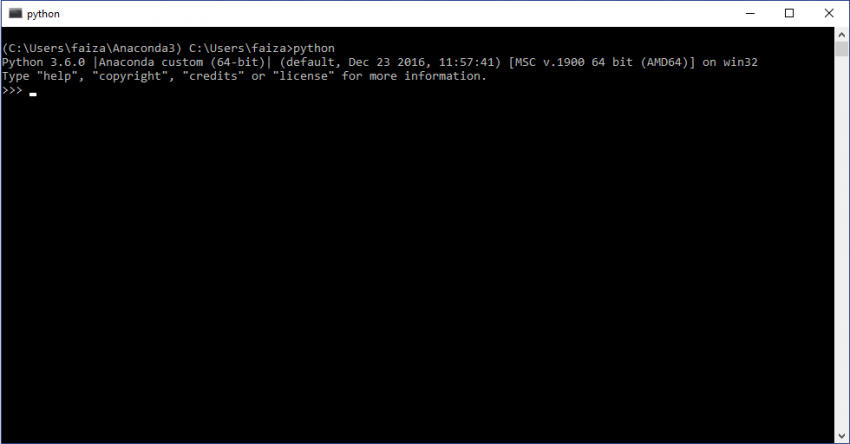
现在,要使用新安装的python生态系统,打开anaconda命令提示符并输入python
就像我之前说的,大多数东西都是预先安装在anaconda中的。剩下的文件库只有tensorflow和keras。在这里,anaconda为创建环境提供特性。这样做是因为当设置出现失误的时候,它也不会影响原来的系统。这就像为所有的实验创建一个沙箱。要做到这一点,请访问anaconda命令提示符和类型。
conda create -n dl anaconda
现在不进行安装,输入剩下的程序包
pip install --ignore-installed --upgrade tensorflow keras
现在,你可以开始在你最喜欢的文本编辑器中编写代码,并运行python脚本
Jupyter概述:快速成型工具
使用纯文本编辑器的问题是每次更新某个东西时,必须从头开始运行代码。假设你有一个用于读取数据和处理的小代码。数据读取的数据代码运行正常,但运行需要一个小时。如果你要尝试更改处理的代码,就必须等待数据读取的数据代码运行结束,然后查看更新是否有效。这太浪费时间了。
你可以使用jupyter笔记本解决这个问题。Jupyter笔记本本质上是保存你的进展,让你从你离开的地方继续前进。在这里你可以用结构化的方式来写代码,这样你就可以在需要的时候重新编写代码并更新它。
在上面的部分中,你已经用anaconda软件设置了python生态系统。如前所述,anaconda在它上面预先安装了jupyter。打开jupyter笔记本,打开anaconda提示符,转到创建和输入的目录
jupyter notebook
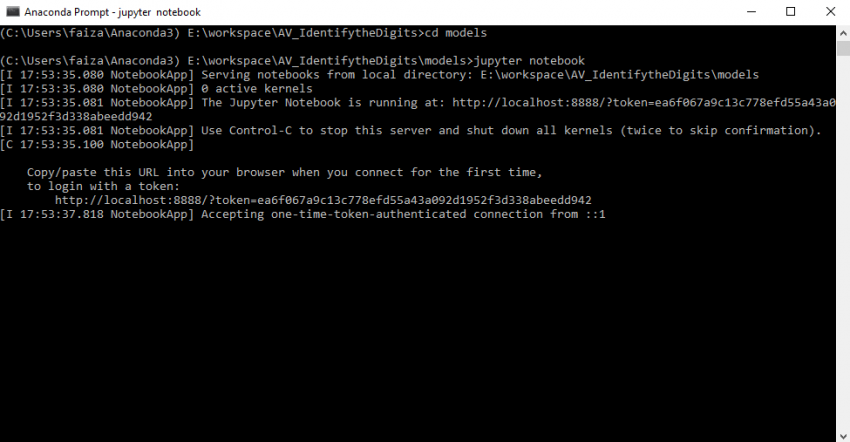
在你的网页浏览器中打开jupyter笔记本(我是Mozilla Firefox)。现在,要创建一个笔记本,单击New-Python 3
现在我通常做的是把代码分成小块的代码,这样就更容易调试了。当我写代码的时候,我时刻记着以下几条:
- 把想做的事情记下来
- 导入所有必需的库
- 编写尽可能多的通用型代码,这样我就不必更新太多。
- 当我做的时候,尽可能测试每一件小事。
这是我写的代码示例(链接地址为http://nbviewer.jupyter.org/github/analyticsvidhya/identify_the_digits/blob/master/keras/notebooks/simple_neural_network.ipynb),用来解决前面提到的深度学习问题。
实验记录标签:GitHub版本控制
一个数据科学项目需要多次迭代的实验和测试。很难记住你尝试过的所有事情中,哪个是有效的,哪个无效。
控制这个问题的一种方法是记下你做的所有实验并总结它们。但这也有点乏味和浪费体力。这个问题(和我个人的选择)的一个解决方案是使用GitHub。最初GitHub被用作软件工程师的代码共享平台,但现在它逐渐被数据科学社区所接受。GitHub所做的是为你提供一个框架,用于保存你在代码中所做的所有更改,并在需要的时候返回。这为你提供了有效地执行数据科学项目所需的灵活性。
我将给你一个如何使用GitHub的例子。但首先,在我们的系统中安装它。转到下载链接(链接地址为https://git-scm.com/downloads),按你的系统点击版本。下载并安装。
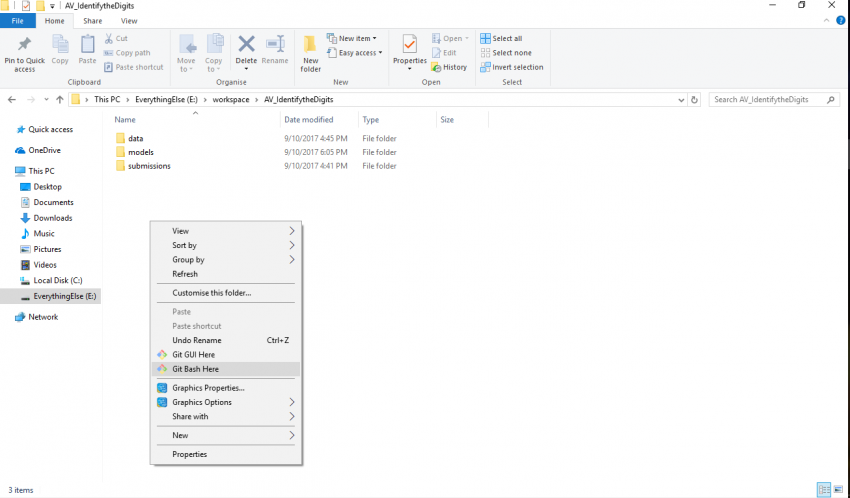
在你的系统中安装git,并为其调用git bash命令提示符。下一步是使用你的git帐户配置系统。只要你注册了GitHub(链接地址为https://github.com/),你就可以使用它来设置你的系统。打开你的git bash并输入以下命令。
git config --global user.name "jalFaizy"
git config --global user.email ff@ff.com
现在有两个任务要做。
- 在GitHub上创建一个存储库
- 将储存库与你的代码目录连接起来
要完成任务,遵循下面提到的步骤
步骤1:在GitHub上添加一个新的存储库
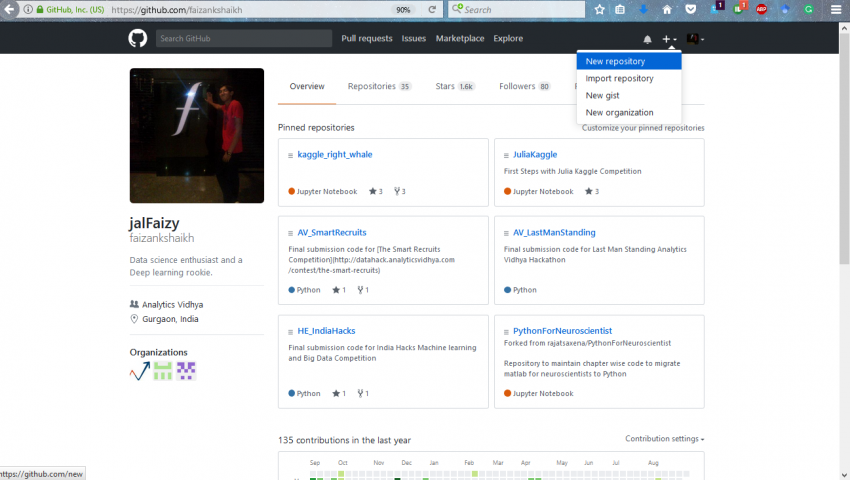
步骤2:给出适当的说明来设置存储库。
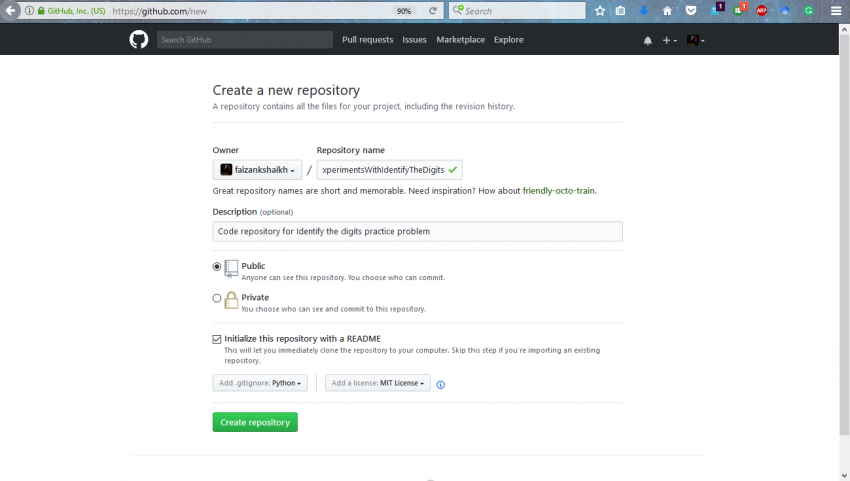
步骤3:连接到存储库
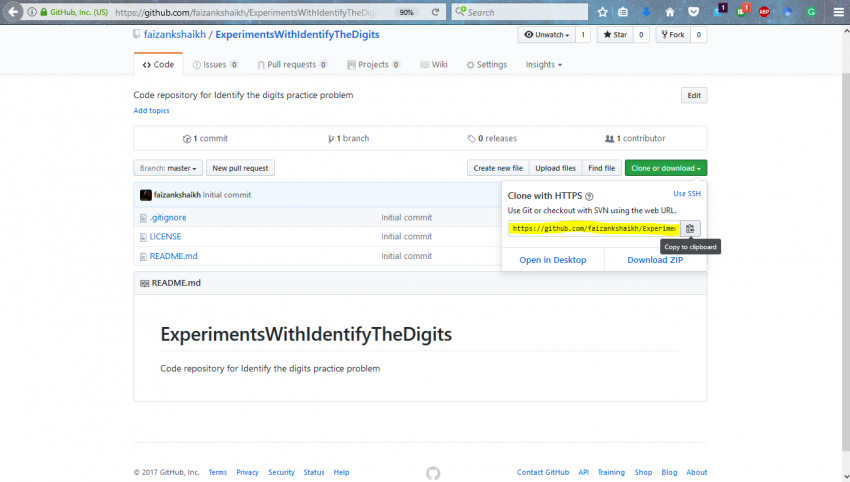
步骤4:使用下面的命令将本地存储库与GitHub上的存储库连接起来。
git init
git remote add origin
git pull origin master
现在,如果你想让GitHub忽略文件中的更改,你可以在.gitignore文件中提到它们。打开它并添加你想要忽略的文件或文件夹。
git add -A .
git commit -m "add first commit"
git push -u origin master
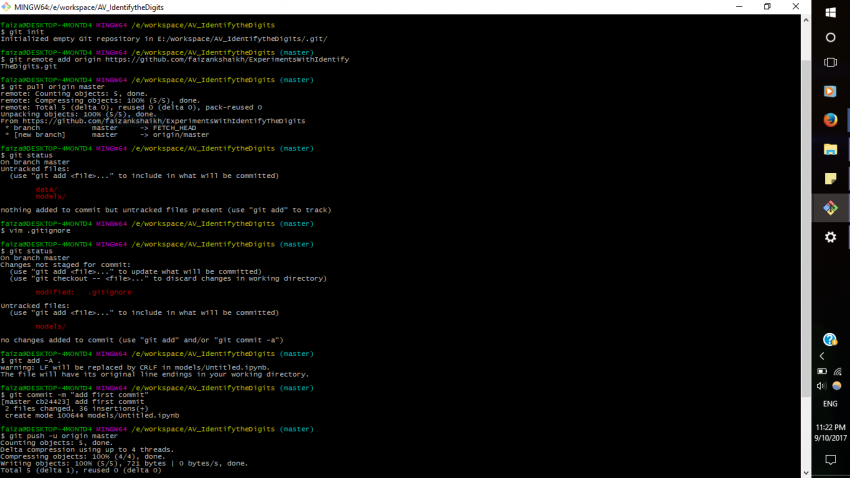
每当你想要保存你的进度时,再次运行这些命令
git add -A .
git commit -m ""
git push -u origin master
这将确保你能回到你离开的地方。
同时运行多个实验:概述Tmux
Jupyter笔记本对我们的实验很有帮助。但如果你同时想做多个实验,在运行另一个命令之前,必须等待前面的命令完成。
我通常有很多想要测试的想法。有时我想扩大规模。我使用了公司的几个月前建立的深度学习箱(链接地址为https://www.analyticsvidhya.com/blog/2016/11/building-a-machine-learning-deep-learning-workstation-for-under-5000/)。所以我更喜欢用tmux。tmux或终端多路复用器让你在同一终端的几个程序之间轻松切换。这是我的指挥中心
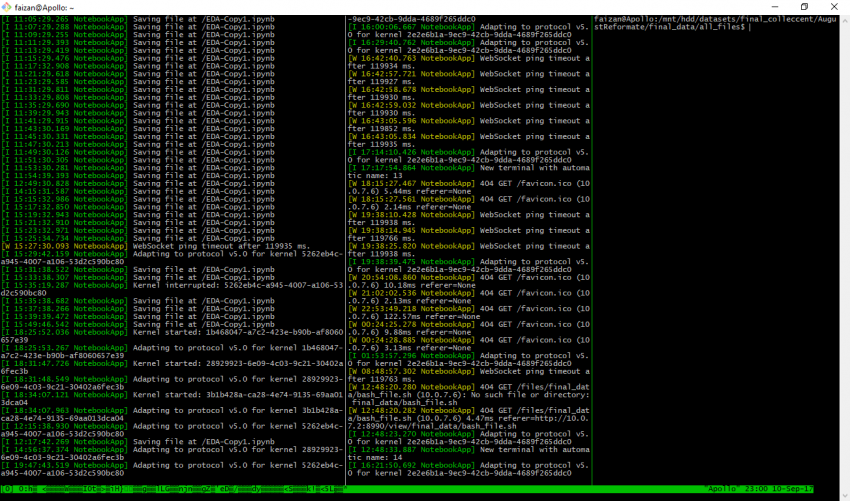
我们在monster中设置乌班图是个不错的想法。在系统中设置tmux非常简单,只需使用下面的命令来安装它
sudo apt-get install tmux
在命令行中键入“tmux”以打开tmux。

只需按ctrl+B,然后shift+5,就可以创建一个新窗口
如果你想让这个实验继续下去并且做些别的事情,只需要输入
tmux detach
它会再次给你一个终端。如果你想再次回到实验中,输入
tmux attach
非常简单。请注意,在windows中设置tmux有点不同。可以参考这篇文章(链接地址为https://blogs.msdn.microsoft.com/commandline/2016/06/08/tmux-support-arrives-for-bash-on-ubuntu-on-windows/)。
部署解决方案:使用Docker来最小化依赖性
完成了所有的实现之后,我们仍然需要部署解决方案,以便开发人员能够访问它。但我们经常面临的问题是,我们所拥有的系统可能与用户的系统不一样。在他们的系统中总会有安装和设置问题。
对于在市场上部署产品,这是一个非常大的问题。你可以使用名为docker的工具解决这个问题。Docker的工作原理是,你可以将代码连同它的依赖项一起打包成一个独立的单元。然后,这个单元可以分发给最终用户。
我通常在我的本地机器上做玩具问题,但当涉及到最终解决方案时,我依赖于monster。我在这个系统中使用这些命令设置了docker
# docker installation
sudo apt-get update
sudo apt-get install apt-transport-https ca-certificates
sudo apt-key adv \
--keyserver hkp://ha.pool.sks-keyservers.net:80 \
--recv-keys 58118E89F3A912897C070ADBF76221572C52609D
echo "deb https://apt.dockerproject.org/repo ubuntu-xenial main" | sudo tee /etc/apt/sources.list.d/docker.list
sudo apt-get update
sudo apt-get install linux-image-extra-$(uname -r) linux-image-extra-virtual
sudo apt-get install docker-engine
sudo service docker start
# setup docker for another user
sudo groupadd docker
sudo gpasswd -a ${USER} docker
sudo service docker restart
# check installation
docker run hello-world
在docker上集成GPU有一些额外的步骤
wget -P /tmp https://github.com/NVIDIA/nvidia-docker/releases/download/v1.0.0-rc.3/nvidia-docker_1.0.0.rc.3-1_amd64.deb
sudo dpkg -i /tmp/nvidia-docker*.deb && rm /tmp/nvidia-docker*.deb
# Test nvidia-smi
nvidia-docker run --rm nvidia/cuda nvidia-smi
现在主要是在docker上安装DL库。我们从零开始构建了docker,遵循了这个优秀的向导(链接地址为https://github.com/saiprashanths/dl-docker/blob/master/README.md)
git clone https://github.com/saiprashanths/dl-docker.git
cd dl-docker
docker build -t floydhub/dl-docker:gpu -f Dockerfile.gpu
要在docker上运行代码,请使用以下命令打开docker的命令提示符
nvidia-docker run -it -p 8888:8888 -p 6006:6006 floydhub/dl-docker:gpu bash
现在,每当我有一个完整的工作模型,我就把它放入docker系统中,以便在规模上进行尝试。你可以在不同的系统中使用dockerfile安装相同的软件和库。不会任何安装问题
工具总结
综上所述,这些是我使用的工具及其用法
- Anaconda用于设置python生态系统和基础数据包
- Jupyter笔记本进行连续实验
- GitHub保存实验进度
- Tmux同时运行多个实验
- 最后使用docker的部署
希望这些工具也能在你的实验中帮助你!

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消