



















AI新技术:利用神经网络对图片进行超级压缩
像神经网络这样的数据驱动算法已席卷全球。他们最近的激增是由于硬件变得更加便宜也更加强大,同时也不缺乏大量的数据的支持。神经网络目前发展到“图像识别”,“自然语言理解”等认知任务,当然也仅限于此类任务。在这篇文章中,我将讨论一种使用神经网络压缩图像的方法,以更快的速度实现图像压缩的最新技术。
本文基于“基于卷积神经网络的端到端压缩框架”(https://arxiv.org/pdf/1708.00838v1.pdf)。
你需要对神经网络有一些熟悉,包括卷积和损失函数。
什么是图像压缩
图像压缩是转换图像使其占用较少空间的过程。简单地存储图像会占用大量空间,因此存在编解码器,例如JPEG和PNG,旨在减小原始图像的大小。
有损与无损压缩
图像压缩有两种类型:无损和有损。正如他们的名字所暗示的那样,在无损压缩中,有可能获取原始图像的所有数据,而在有损压缩中,有些数据在转换中丢失。
例如JPG是一种有损算法,而PNG是一种无损算法

仔细看会发现右边的图像有很多小块,这就是信息的丢失。类似颜色附近的像素被压缩为一个区域,节省了空间,但也丢失关于实际像素的信息。当然,像JGEG,PNG等编解码器的实际算法要复杂得多,但这是有损压缩的良好直观示例。无损当然好,但它在磁盘上占用了太大的空间。
虽然有更好的方法压缩图像而不会丢失大量信息,但是它们太慢了,许多使用迭代的方法,这意味着它们不能在多个CPU内核或GPU上并行运行。这使得它们应用在日常使用中并不现实。
进入卷积神经网络
如果需要计算任何东西并且可以近似,就可以让一个神经网络来做。作者使用一个相当标准的卷积神经网络来改善图像压缩。他们的方法不仅能达到“更好的压缩图像方法”的效果,还可以利用并行计算,让速度的快速提升。
因为,卷积神经网络(CNN)非常擅长从图像中提取空间信息,然后以更紧凑的结构表现(例如,仅存储图像的“重要”比特)。作者想利用CNN的这种能力更好地表现图像。
架构
作者提出了一个双重网络。第一个网络,将采集图像并生成压缩表示(ComCNN)。然后,这个网络的输出通过标准的编解码器(例如JPEG)进行处理。经过编解码器后,图像将被传递到第二个网络,从编解码器“修复”图像,试图恢复原始图像。作者称之为重建CNN(RecCNN)。这两个网络都被反复地训练,类似于GAN。
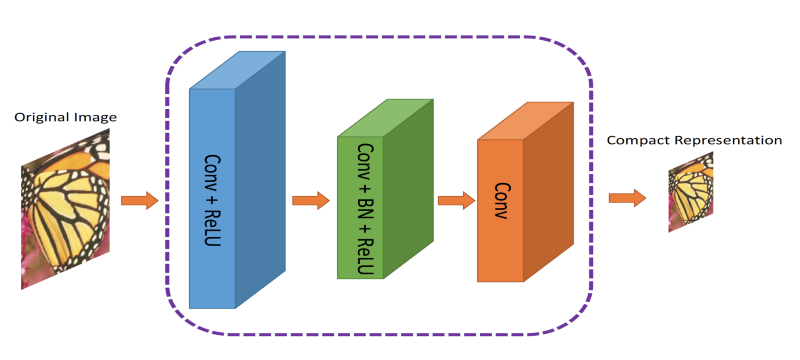
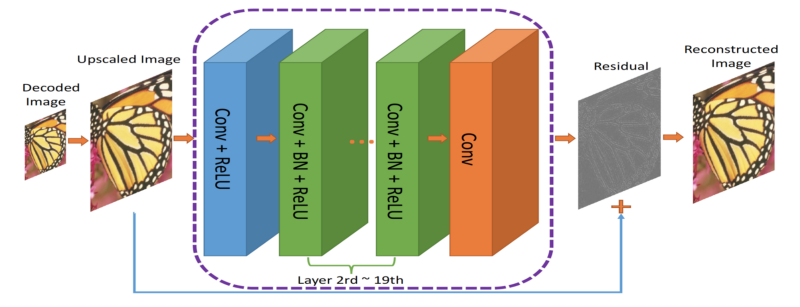
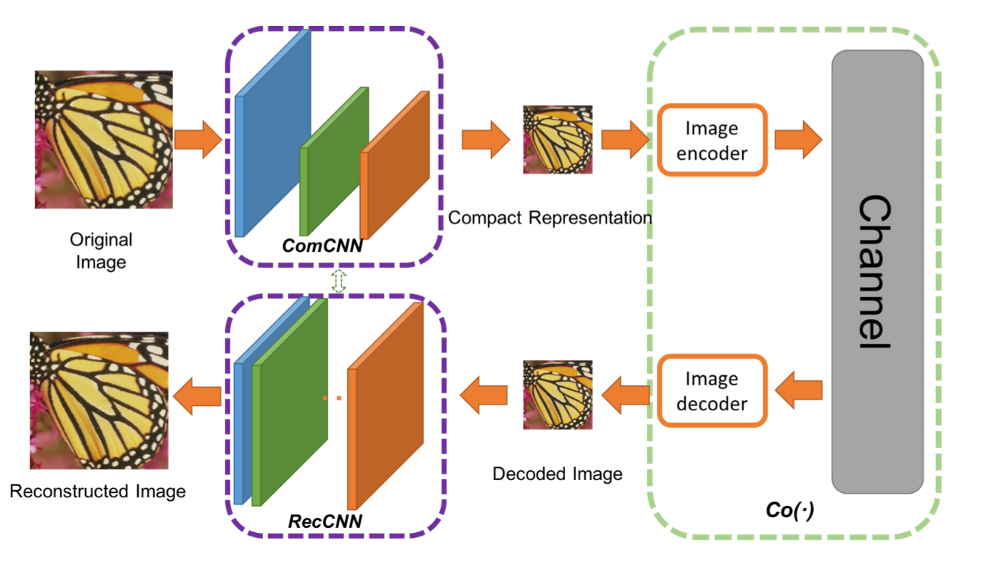
残差是什么
残差可以被认为是“改善”编解码器解码的图像的后处理步骤。神经网络有很多关于世界的“信息”,可以对“修复”做出认知决定。这个想法是基于残差学习,你点击链接进行更深入的了解(https://arxiv.org/pdf/1708.00838v1.pdf)。
损失函数
由于有两个网络,所以使用两个损失函数函数。第一个,对于ComCNN,标记为L1,定义为:
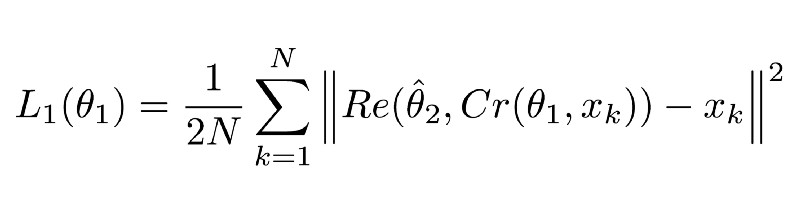
说明
这个方程可能看起来很复杂,但它实际上是标准MSE(均方误差)。||²表示它们所包含的矢量的“标准”。
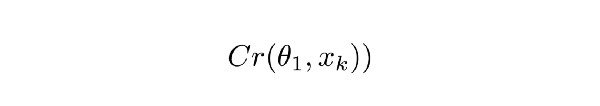
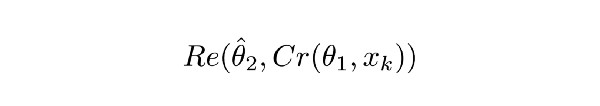
Re()表示RecCNN。该方程将公式1.1的值传递给RecCNN。“θ帽”表示RecCNN的可训练参数(帽表示参数固定)
直观的定义
公式1.0将使ComCNN修改它的权重,这样,在经过RecCNN重新创建后,最终图像将尽可能接近真实的输入图像。
RecCNN的第二个损失函数定义为:
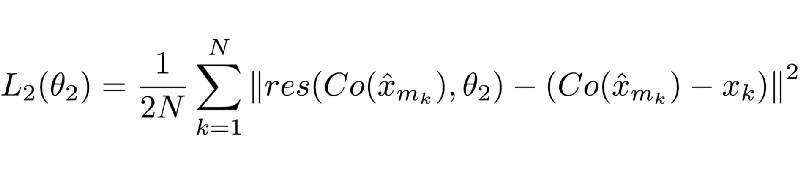
说明
同样的,这个函数可能看起来很复杂,但它是一个常见而标准的神经网络损失函数(MSE)。
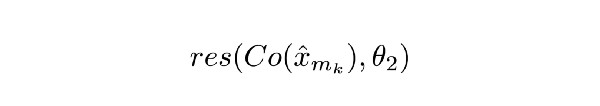
Co()表示编解码器的输出。x帽表示ComCNN的输出。θ2表示RecCNN的可训练参数。res()只表示网络学习的残差,它只是RecCNN的输出。值得注意的是,RecCNN在Co()和输入图像之间的差异进行训练,而不是直接从输入图像中进行训练。
直观的定义
公式2.0将使RecCNN修改其权重,使得其输出看起来尽可能接近原始图像。
训练计划
这些模型经过类似于GAN的训练方式的迭代训练。第一个模型的权重是固定的,而第二个模型的权重被更新,然后第二个模型的权重是固定的,而第一个模型被训练。
基准
作者将其方法与现有方法进行了比较,包括简单的编解码器。他们的方法比其他方法更好,同时在有能力的硬件上使用时保持高速。作者注意到尝试只使用其中一个网络性能会下降。
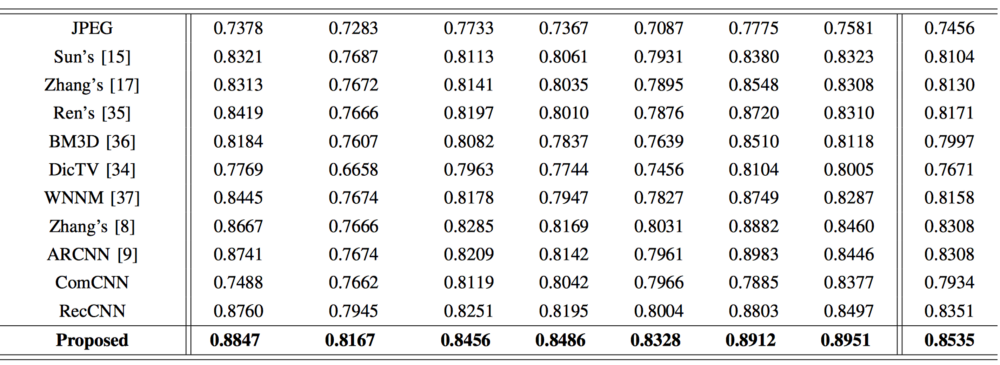
结论
一种应用深度学习来压缩图像的新技术。我们讨论了除了图像分类和语言处理等常用任务之外,使用神经网络的可能性。这种技术不仅压缩表现良好,处理图像的速度也更快。









