












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






使用深度学习检测面部特征,让实时视频聊天变得更有趣
2017年09月14日 由 xiaoshan.xiang 发表
953903
0
也许你想知道如何在实时视频聊天或者检测情绪的时候把有趣的东西放在脸上?我们可以利用深度学习以及一种较老的方法实现它。

过去,检测人脸及其特征(如眼睛、鼻子、嘴,甚至从它们的形态中获知情感)一项是极具挑战性的任务。而现在,这个任务可以通过深度学习解决,任何有天赋的青少年都可以在几个小时内完成这项任务。我将在这篇文章中向你展示这种方法。

如果你像我一样,需要执行面部跟踪(将姿态从网络摄像机转换成动画角色),你可能会发现一个用于限制当地模型(CLM:链接地址为https://sites.google.com/site/xgyanhome/home/projects/clm-implementation/ConstrainedLocalModel-tutorial%2Cv0.7.pdf?attredirects=0)的最佳算法,由如 Cambridge Face Trackeror(链接地址为https://github.com/TadasBaltrusaitis/CLM-framework)实现其新的OpenFaceincarnation(链接地址为https://github.com/TadasBaltrusaitis/OpenFace)。这是基于将检测任务分割为检测形状向量特征(ASM:链接地址为http://slidegur.com/doc/3183242/face-and-facial-feature-tracking-asm--aam--clm)和补丁图像模板(AAM:链接地址为http://slidegur.com/doc/3183242/face-and-facial-feature-tracking-asm--aam--clm),并使用预先训练的线性SVM来改进检测。
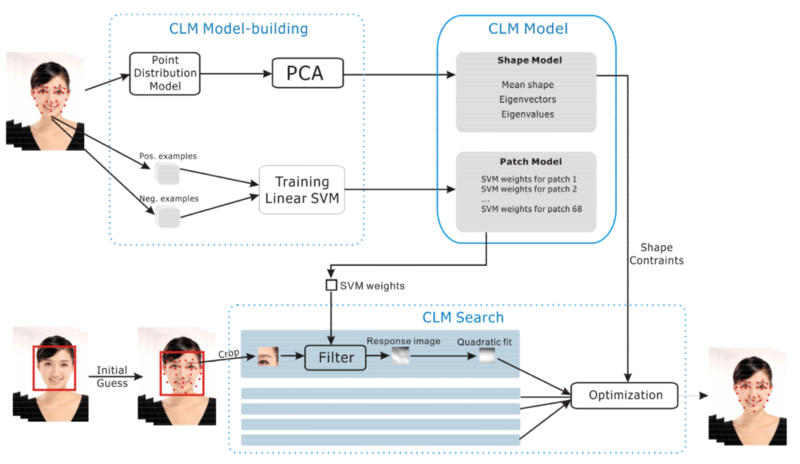
它通过粗略估计关键点的位置来工作,然后使用SVM预先训练的图像中包含脸部的部分并且调整关键点的位置。重复这一过程直到错误降到足够低。此外,值得一提的是,它假定图像上的脸部位置已经被估计,例如使用viola - jones(链接地址为https://en.wikipedia.org/wiki/Viola%E2%80%93Jones_object_detection_framework)探测器(Haar cascade:链接地址为https://en.wikipedia.org/wiki/Haar-like_feature)。CLM过程非常复杂,而且非常重要,绝对不会由一个高级中学的向导来实现。你可以看到这里的整体架构:
我们可以使用一个非常简单的卷积神经网络(CNN:链接地址为https://en.wikipedia.org/wiki/Convolutional_neural_network),并在我们希望在包含人脸的图像上执行关键点的检测。为此我们需要有一个训练数据集;我们可以使用“Kaggle”(链接地址为https://www.kaggle.com/)提供的一个包含15个关键点的“面部关键点检测挑战”(链接地址为https://www.kaggle.com/c/facial-keypoints-detection/data),或者一个带有76个关键点的复杂的“MUCT数据集”(链接地址为http://www.milbo.org/muct/)。
很明显,拥有高质量的训练数据集在这里是必不可少的。
这里是一个样本的巴洛克式样貌和它在Kaggle数据集的关键点的样子:
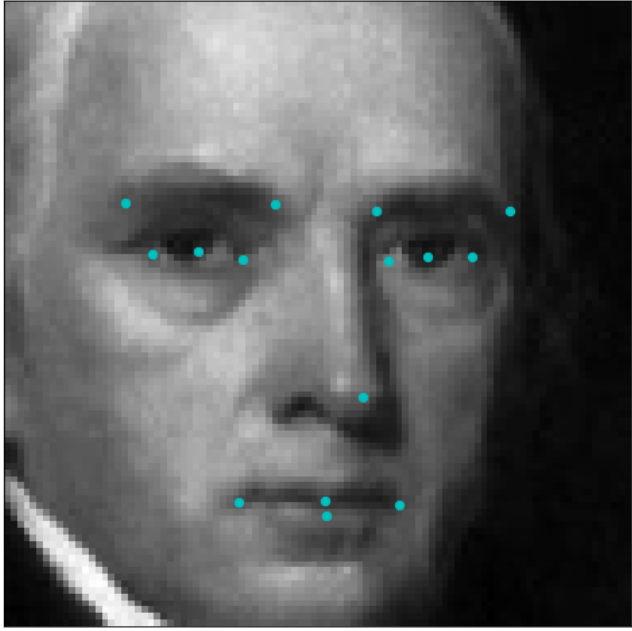
数据集包含有96x96分辨率的灰度图像和15个关键点,其中每个眼睛有5个关键点,嘴巴\鼻子有5个关键点。
对于任意一张图像,我们首先需要检测人脸图像的位置;前面提到的基于Haar cascades的viola - jones探测器可以使用(它的工作原理和CNNs类似)。或者,如果你更有冒险精神,你可以使用完全卷积网络(FCN:链接地址为https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn.pdf),并进行深度评估的图像分割。

总之,使用OpenCV是一件很简单的事:
这段代码返回图像上所有可能的面部边界框。
接下来,对于Viola-Jones返回的每个边界框,我们提取出相应的子图像,将它们转换成灰度,并将它们调整到96x96。他们将会成为我们完成CNN的输入。
CNN的架构非常琐碎;一堆5x5的卷积层(实际上3个,分别带有24个、36个和48个过滤器),然后2个或者更多的3x3卷积层(64个过滤器)和3个完全连接层(分别有500个、90个和30个节点)。一些max pooling可以防止过度拟合和全局平均池,以减少flatten参数的数量。输出将是30个浮点数,表示每个15个关键点的x,y坐标。
以下是Keras(链接地址为https://keras.io/)的实现:
你可能希望选择均方根传播(rmsprop:链接地址为http://root%20mean%20square%20propagation/)优化器和均方误差(MSE:链接地址为https://en.wikipedia.org/wiki/Mean_squared_error)作为损失函数和精度指标。
就像在输入图像上批量标准化,全球平均池,以及 HE normal重量初始化一样,在大约30个训练时期,可以得到80 - 90%的验证精度和低于0.001的损失。
然后预测关键点位置的简单运行:
现在已经掌握了检测面部关键点的技术。
记住,你的预测结果将是15对x,y坐标,按照如下图所示:

如果你想做得更好,你可能想做一些额外的作业:
你可能会觉得这一切都太简单了,如果你想要挑战自己,那就转到3D,看看Facebook(链接地址为https://research.fb.com/wp-content/uploads/2016/11/deepface-closing-the-gap-to-human-level-performance-in-face-verification.pdf)和英伟达(链接地址为http://research.nvidia.com/sites/default/files/publications/laine2017sca_paper_0.pdf)是如何追踪人脸的。
很明显,你可以用这个新学会的魔法来做一些你可能一直想做但不知道怎么做的事情:
过去,检测人脸及其特征(如眼睛、鼻子、嘴,甚至从它们的形态中获知情感)一项是极具挑战性的任务。而现在,这个任务可以通过深度学习解决,任何有天赋的青少年都可以在几个小时内完成这项任务。我将在这篇文章中向你展示这种方法。
“古典”方法(CLM)
如果你像我一样,需要执行面部跟踪(将姿态从网络摄像机转换成动画角色),你可能会发现一个用于限制当地模型(CLM:链接地址为https://sites.google.com/site/xgyanhome/home/projects/clm-implementation/ConstrainedLocalModel-tutorial%2Cv0.7.pdf?attredirects=0)的最佳算法,由如 Cambridge Face Trackeror(链接地址为https://github.com/TadasBaltrusaitis/CLM-framework)实现其新的OpenFaceincarnation(链接地址为https://github.com/TadasBaltrusaitis/OpenFace)。这是基于将检测任务分割为检测形状向量特征(ASM:链接地址为http://slidegur.com/doc/3183242/face-and-facial-feature-tracking-asm--aam--clm)和补丁图像模板(AAM:链接地址为http://slidegur.com/doc/3183242/face-and-facial-feature-tracking-asm--aam--clm),并使用预先训练的线性SVM来改进检测。
它通过粗略估计关键点的位置来工作,然后使用SVM预先训练的图像中包含脸部的部分并且调整关键点的位置。重复这一过程直到错误降到足够低。此外,值得一提的是,它假定图像上的脸部位置已经被估计,例如使用viola - jones(链接地址为https://en.wikipedia.org/wiki/Viola%E2%80%93Jones_object_detection_framework)探测器(Haar cascade:链接地址为https://en.wikipedia.org/wiki/Haar-like_feature)。CLM过程非常复杂,而且非常重要,绝对不会由一个高级中学的向导来实现。你可以看到这里的整体架构:
深度学习
我们可以使用一个非常简单的卷积神经网络(CNN:链接地址为https://en.wikipedia.org/wiki/Convolutional_neural_network),并在我们希望在包含人脸的图像上执行关键点的检测。为此我们需要有一个训练数据集;我们可以使用“Kaggle”(链接地址为https://www.kaggle.com/)提供的一个包含15个关键点的“面部关键点检测挑战”(链接地址为https://www.kaggle.com/c/facial-keypoints-detection/data),或者一个带有76个关键点的复杂的“MUCT数据集”(链接地址为http://www.milbo.org/muct/)。
很明显,拥有高质量的训练数据集在这里是必不可少的。
这里是一个样本的巴洛克式样貌和它在Kaggle数据集的关键点的样子:
数据集包含有96x96分辨率的灰度图像和15个关键点,其中每个眼睛有5个关键点,嘴巴\鼻子有5个关键点。
对于任意一张图像,我们首先需要检测人脸图像的位置;前面提到的基于Haar cascades的viola - jones探测器可以使用(它的工作原理和CNNs类似)。或者,如果你更有冒险精神,你可以使用完全卷积网络(FCN:链接地址为https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn.pdf),并进行深度评估的图像分割。
总之,使用OpenCV是一件很简单的事:
Grayscale_image = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY)
face_cascade = cv2.CascadeClassifier(‘haarcascade_frontalface_default.xml’)
bounding_boxes = face_cascade.detectMultiScale(grayscale_image, 1.25, 6)
这段代码返回图像上所有可能的面部边界框。
接下来,对于Viola-Jones返回的每个边界框,我们提取出相应的子图像,将它们转换成灰度,并将它们调整到96x96。他们将会成为我们完成CNN的输入。
CNN的架构非常琐碎;一堆5x5的卷积层(实际上3个,分别带有24个、36个和48个过滤器),然后2个或者更多的3x3卷积层(64个过滤器)和3个完全连接层(分别有500个、90个和30个节点)。一些max pooling可以防止过度拟合和全局平均池,以减少flatten参数的数量。输出将是30个浮点数,表示每个15个关键点的x,y坐标。
以下是Keras(链接地址为https://keras.io/)的实现:
model = Sequential()
model.add(BatchNormalization(input_shape=(96, 96, 1)))
model.add(Convolution2D(24, 5, 5, border_mode=”same”, init=’he_normal’, input_shape=(96, 96, 1), dim_ordering=”tf”))
model.add(Activation(“relu”))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), border_mode=”valid”))
model.add(Convolution2D(36, 5, 5))
model.add(Activation(“relu”))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), border_mode=”valid”))
model.add(Convolution2D(48, 5, 5))
model.add(Activation(“relu”))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), border_mode=”valid”))
model.add(Convolution2D(64, 3, 3))
model.add(Activation(“relu”))
model.add(MaxPooling2D(pool_size=(2, 2), strides=(2, 2), border_mode=”valid”))
model.add(Convolution2D(64, 3, 3))
model.add(Activation(“relu”))
model.add(GlobalAveragePooling2D());
model.add(Dense(500, activation=”relu”))
model.add(Dense(90, activation=”relu”))
model.add(Dense(30))
你可能希望选择均方根传播(rmsprop:链接地址为http://root%20mean%20square%20propagation/)优化器和均方误差(MSE:链接地址为https://en.wikipedia.org/wiki/Mean_squared_error)作为损失函数和精度指标。
就像在输入图像上批量标准化,全球平均池,以及 HE normal重量初始化一样,在大约30个训练时期,可以得到80 - 90%的验证精度和低于0.001的损失。
model.compile(optimizer=’rmsprop’, loss=’mse’, metrics=[‘accuracy’])
checkpointer = ModelCheckpoint(filepath=’face_model.h5', verbose=1, save_best_only=True)
epochs = 30
hist = model.fit(X_train, y_train, validation_split=0.2, shuffle=True, epochs=epochs, batch_size=20, callbacks=[checkpointer], verbose=1)
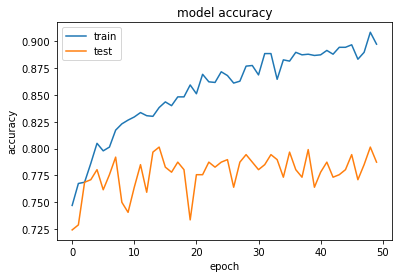
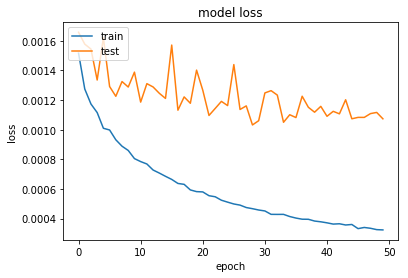
然后预测关键点位置的简单运行:
features = model.predict(region, batch_size=1)
现在已经掌握了检测面部关键点的技术。
记住,你的预测结果将是15对x,y坐标,按照如下图所示:
如果你想做得更好,你可能想做一些额外的作业:
- 试验如何减少卷积层数和过滤大小,同时保持精度和提高推理速度
- 用转移学习代替卷积部分(我最喜欢的是Xception:链接地址为https://arxiv.org/abs/1610.02357)
- 使用更详细的数据集
- 做一些高级的图像增强来提高稳健性
你可能会觉得这一切都太简单了,如果你想要挑战自己,那就转到3D,看看Facebook(链接地址为https://research.fb.com/wp-content/uploads/2016/11/deepface-closing-the-gap-to-human-level-performance-in-face-verification.pdf)和英伟达(链接地址为http://research.nvidia.com/sites/default/files/publications/laine2017sca_paper_0.pdf)是如何追踪人脸的。
很明显,你可以用这个新学会的魔法来做一些你可能一直想做但不知道怎么做的事情:
- 在视频聊天中,把某些物体放在脸上,比如太阳镜,奇怪的帽子,胡子等等。
- 与朋友、敌人、动物和物品交换脸部
- 通过允许在自拍实时视频上测试新的发型、珠宝或化妆,满足人类的虚荣心。
- 检测你的员工是否醉酒,以致于不能执行指定的任务
- 如果你想使情感处理自动化,就需要在你的视频中识别人们的情绪
- 使用了GANs(链接地址为https://en.wikipedia.org/wiki/Generative_adversarial_networks)的实时face-to-cartoon转换,根据你在网络摄像头上的脸来弯曲卡通脸,进而模仿你的动作、谈话和情绪。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消