












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






苹果WWDC学习框架Core ML的发布,正式嵌入终端设备
2017年06月06日 由 duketxl 发表
402510
0

苹果不是唯一一家致力于将机器学习带入移动设备的公司。 Google在几周前的 I / O开发者大会上宣布推出新的 TensorFlow Lite编程框架,让开发人员更轻松地构建运行在低功耗的 Android设备模型。
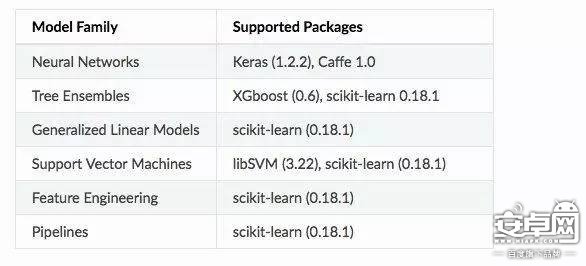
使用该机器学习框架,开发人员必须将训练好的模型转换为兼容 Core ML的特殊格式。然后将模型加载到 Apple的 Xcode开发环境中,并部署到 iOS设备上。苹果发布了基于流行开源项目的四个预训练机器学习模型,并且还提供了一个转换器,以便开发人员自己移植。该转换器可用于 Caffe,Keras,scikit-learning,XGBoost和 LibSVM等框架。

苹果技术主管 Kevin Lynch说,通过机器学习,个人助理软件 Siri会更积极主动。
软件技术主管Craig Federighi强调 Safari使用机器学习来智能阻止浏览器跟踪,还谈到先进的卷积神经网络改善了照片中的面部识别,并使 Siri更加智能化,深度学习使 Siri的声音更加自然。
硬件工程师 John Ternus讲解了 Radeon Vega GPU有助于机器学习功能,提高了苹果即将推出的 iMac Pro的计算能力。

苹果自 2011年以来一直在培养 Siri,但直到去年 10月才聘请卡内基·梅隆大学教授深度学习知名人物 Ruslan Salakhutdinov为其首席 AI研究主管。
苹果一度以严格的保密制度闻名,苹果的安全政策甚至延伸到博客、演讲安排甚至与配偶的对话等。一直以来,苹果都不对外公布自己的人工智能发展情况,“保密”的文化传统让苹果的人工智能研究进展变得神秘,但同时也给自己带来了麻烦:难以从学术圈招到人才。想要在学术圈获得知名度和认可,公开研究成果与大家进行交流是关键。在人工智能的浪潮下,一些巨头公司如 Google、Facebook都有自己机器学习研究小组,并可发布论文。这些也造成了苹果在人工智能等方面的专利申请数量已被其主要竞争对手超越。
去年 NIPS大会上,苹果新聘请的这位首席 AI研究主管 Russ Salakhutdinov才宣布允许其人工智能和机器学习研究员公开发布和分享他们的最新研究成果。并在 12月,发布了第一篇人工智能研究论文:模拟 +无监督方法改善合成图像质量(《Learning from Simulated and Unsupervised Images through Adversarial Training》)。
众所周知,AI的发展需要收集和挖掘大量的数据,但苹果隐私保护文化让他们花费了相当多的资源在建立额外的隐私层级保护上。苹果一度高调宣称他们不像其他公司那样收集大量用户数据来进行用户画像。比如优化 Siri,必须收集和解读应用程序的数据,例如日历,餐厅预订,以及浏览。这个立场无疑使苹果在人工智能的赛跑中处于落后地位。
去年的 WWDC大会上,苹果还特地讲解了他们的差异隐私项目(differential privacy)。软件技术主管 Craig Federighi曾说:“需要明确的是,对于这些照片本身,其架构集以加密方式存储在云端,而元数据——包括用户创建的元数据以及我们深度学习后分类得出的元数据——同样经过加密,苹果无法进行读取“。
差异隐私基本思路是,如果大量用户输入某个实际上并不存在的单词,那么我们将不再将其视为拼写错误,甚至可能将其纳入拼写补全推荐。在这种情况下,我们希望全部客户都能够理解该单词,但我们又不希望知晓具体是哪位用户输入了该词。我们刻意回避这种将习惯与个人挂钩的信息。
但只要样本量充足,这种不相符的问题将自行得到解决。因此如果我们希望学习新出现的单词,我们会对其进行哈希处理,并从哈希中提取单一 bit,例如将其称为 1。与此同时,手机设备会对数据内容进行混淆,意味着即使其读取到的数据为 1,其也可能通过随机算法将其表达为 0。
苹果公司获得的数据正是这类混淆处理后的结果。但由于拥有充足的数据量,苹果方面仍然能够建立起宏观视角,并了解大规模群体表现出的真实倾向。具体来讲,苹果公司能够借此了解广泛用户的思维方式,但却无法具体将其与个人联系起来。
涉及个性化信息时,苹果公司的政策限制要求其只能在设备内部进行模型训练。数据匮乏问题也限制了基于个人的深度学习。根据 Jeff Dean的说法,整套神经网络是由成千上万的参数构成,而非单纯参考设备内运行的信息。这种个性化能力的缺失是否致命?至少对谷歌而言是如此。谷歌在 2016年 I/O大会上发布了全面普及机器学习的战略,其中的典型方案就是 Google Assistant个人 AI服务。谷歌公司似乎希望将深度学习本身作为主要目标,而苹果则更倾向于利用这项技术打造更出色的产品。每支人工智能团队都需要决定其是否需要构建深度学习系统。这不仅是一项技术方案,更会带来道德层面的拷问。直到现在,苹果公司的思路显然提供了不同的实现模式。

那么最后,苹果所做的这一切,将成为后发制人的人工智能企业吗?

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消