



















用虚假数据集教AI作曲,谷歌的音乐创作技术揭秘

缺乏标记的音乐数据
ChatGPT 或 Bard 等大型语言模型 (LLM) 在大量非结构化文本数据上进行训练。虽然收集数百万个网站的内容在计算上可能很昂贵,但公共网络上有大量的训练数据。相比之下,像 DALL-E 2 这样的文本到图像模型需要一种完全不同的数据集,该数据集由具有相应描述的图像对组成。
同样,文本到音乐模型依赖于带有音乐内容描述的歌曲。然而,与图像不同,带标签的音乐在互联网上确实很难找到。有时,可以使用乐器、流派或情绪等元数据,但很难获得全文的深入描述。这给试图收集数据以训练生成音乐模型的研究人员和公司带来了严重的问题。
2023 年初,谷歌研究人员凭借其突破性模型 MusicLM 和 Noise2Music 在音乐 AI 方面引起了广泛关注。然而,音乐家们对这些模型的数据是如何收集的知之甚少。让我们一起深入探讨这个话题,了解谷歌音乐 AI 研究中应用的一些技巧。
谷歌如何克服数据稀缺
弱关联标签
对于 MusicLM 和 Noise2Music,谷歌依赖于他们的另一个名为 MuLan 的模型,该模型经过训练可以计算任何音乐片段和任何文本描述之间的相似度。为了训练MuLan,谷歌使用了我们所说的“弱关联标签”。他们没有精心策划具有高质量文本描述的音乐数据集,而是有目的地采用了不同的方法。
首先,他们从 YouTube 上的 4400 万个音乐视频中各提取了 30 秒的片段,从而产生了 37 万小时的音频。然后,音乐被贴上与视频相关的各种文本标签:视频标题和描述、评论、视频播放列表的名称等等。为了减少这个数据集中的噪音,他们采用了一个大型语言模型来识别哪些关联的文本信息具有与音乐相关的内容,并丢弃所有没用的内容。
弱关联标签还不能被认为是“假”数据集,因为文本信息仍然是由真人编写的,并且无疑在某种程度上与音乐相关联。然而,这种方法肯定会优先考虑数量而不是质量,这在过去会引起大多数机器学习研究人员的担忧。谷歌才刚刚起步……
伪标签
Noise2Music 是一种基于扩散技术的生成音乐 AI,它也被用于 DALL-E 或 Midjourney 等图像生成模型。
为了训练 Noise2Music,谷歌将他们之前的方法发挥到了极致,从弱关联标签过渡到完全人工标签。在他们所谓的“伪标签”中,作者采用了一种非凡的方法来收集音乐描述文本。他们促使大型语言模型 (LaMDA) 为 15 万首流行歌曲编写多个描述,从而产生了 400 万个描述。以下是此类描述的示例:
皇后乐队的“Don't Stop Me Now”:这首充满活力的摇滚歌曲以钢琴、贝斯吉他和鼓为基础。乐队热力四射,蓄势待发,意气风发。
随后,研究人员移除了歌曲和艺术家名称,从而生成原则上也适用于其他歌曲的描述。然而,即使有了这些描述,研究人员仍需要将它们与合适的歌曲匹配,以获取大量的标注数据集。这就是他们训练在弱相关标签上的模型MuLan发挥作用的地方。
研究人员收集了大量未标记音乐的数据集,产生了 34 万小时的音乐。对于这些曲目中的每一个,他们都使用 MuLan 来识别与其最匹配的人工生成的歌曲描述。从本质上讲,每首音乐都没有映射到描述歌曲本身的文本,而是映射到封装了与其相似的音乐的描述。
为什么这有效?
问题
在传统的机器学习中,分配给每个观察结果(在本例中为一段音乐)的标签应该理想地代表客观事实。然而,音乐描述本身就缺乏客观性,这是第一个问题。此外,通过使用音频到文本的映射技术,标签不再“真实”地反映歌曲中发生的事情。他们没有提供对音乐的准确描述。鉴于这些明显的缺陷,人们可能想知道为什么这种方法仍然产生有用的结果。
偏差与噪声
当数据集的标签没有准确地分配时,可能有两个主要原因:偏差和噪音。偏差指的是标签在某种特定方式上一直不真实。例如,如果数据集经常将器乐作品标记为歌曲,但从未将歌曲标记为器乐作品,则表明存在一种偏向于预测有无人声的偏差。
另一方面,噪声表示标签中的一般可变性,与方向无关。例如,如果每首曲目都被标记为“悲伤的钢琴曲”,那么数据集就存在严重偏差,因为它始终为许多歌曲提供不准确的标签。但是,由于它对每个轨道应用相同的标签,因此没有可变性,因此数据集中不存在噪声。
通过将曲目映射到为其他曲目编写的描述性文本,我们引入了噪音。这是因为对于大多数曲目,数据集中很难找到完美的描述。因此,大多数标签都有点偏差,即不真实,这会产生噪声。但是,标签有偏差吗?
由于可用描述是为流行歌曲生成的,因此合理地假设描述池偏向于(西方)流行音乐。尽管如此,基于15万首独特歌曲生成了400万个描述,人们期望有不同范围的描述可供选择。此外,大多数有标记的音乐数据集都表现出相同的偏差,因此与其他方法相比,这种方法并没有独特的劣势。真正使这种方法与众不同的是引入更多的噪音。
为什么噪声在机器学习中可以接受
训练一个机器学习模型在一个有偏差的数据集上通常不是一个理想的方法,因为它将导致模型学习和复制有偏差的任务理解。然而,训练一个机器学习模型在没有偏差但有噪音的数据上仍然可以产生令人印象深刻的结果。请允许这里用一个例子来说明这一点。
请看下面的图表,它展示了由橙色和蓝色点组成的两个数据集。在无噪音的数据集中,蓝点和橙点是完全可分的。然而,在有噪声的数据集中,一些橙点已经移动到了蓝点簇中,反之亦然。尽管有了这些额外的噪声,但是如果我们检查训练好的模型,我们会发现两个模型识别了大致相同的模式。这是因为即使在噪声存在的情况下,AI也会学习识别能够最大程度地减少错误的最优模式。
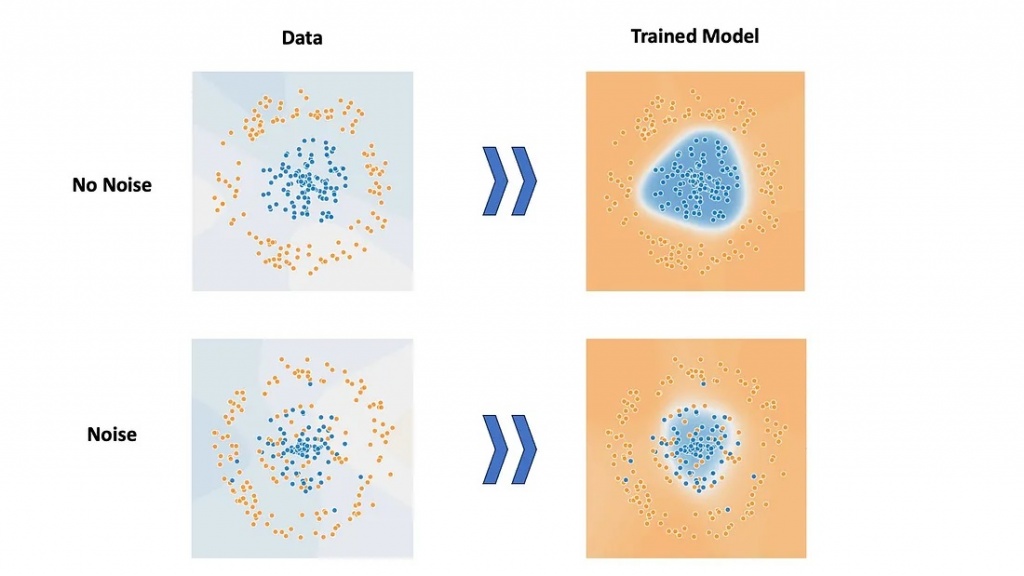 这个例子证明了AI确实可以从噪声数据集中学习,例如谷歌生成的数据集。然而,主要的挑战在于噪声数据集越大,需要用来有效地训练模型的训练数据就越多。这种合理性是有理由的,因为与相同大小的无噪声数据集相比,噪声数据集本质上包含的有价值信息较少。
这个例子证明了AI确实可以从噪声数据集中学习,例如谷歌生成的数据集。然而,主要的挑战在于噪声数据集越大,需要用来有效地训练模型的训练数据就越多。这种合理性是有理由的,因为与相同大小的无噪声数据集相比,噪声数据集本质上包含的有价值信息较少。
结论
总之,谷歌采用了创新的技术来解决在训练生成音乐AI模型时的标记音乐数据受限问题。他们利用弱关联的标签与MuLan相关联,利用与音乐视频相关的各种来源的文本信息,并采用语言模型来过滤不相关的数据。在开发Noise2Music时,他们通过为流行歌曲生成多个描述,并使用他们的预训练模型将其映射到合适的曲目来引入伪标签。
尽管这些方法可能偏离了传统的标记方法,但它们仍然被证明是有效的。尽管引入了噪声,但模型仍然能够学习并确定最优模式。虽然使用虚假数据集可能被视为非传统的方法,但它突显了现代语言模型在创建大规模和有价值的机器学习数据集方面的巨大潜力。
来源:https://towardsdatascience.com/how-google-used-fake-datasets-to-train-generative-music-ai-def6f3f71f19









