超越机器学习到机器推理
2020年01月21日 由 KING 发表
605317
0
关于人工智能的对话通常围绕着以技术为中心的主题:机器学习、对话界面、自主代理以及数据科学、数学和实现的其他方面。但是,AI的历史和演变不仅仅是一个技术故事。人工智能的故事也与创新和研究突破的浪潮密不可分,这些创新和研究突破首先进入了经济和技术障碍。似乎不断有发现、创新、兴趣、投资、谨慎乐观、无限热情、意识到局限性、技术障碍、兴趣消退以及AI研究退回到学术背景的连续模式。这些前进和后退的浪潮似乎和海岸上的海浪来回一样。 这种兴趣、投资、炒作、然后下降、反复冲洗和重复的模式对于技术人员和投资者而言尤其令人烦恼,因为它没有遵循通常的技术采用生命周期。在杰弗里·摩尔(Geoffrey Moore)的著作《穿越鸿沟》中得到普及,技术的采用通常遵循明确的路径。技术得到了发展,并首先被创新者和早期采用者所发现,如果该技术能够跨越“鸿沟”,它就会被早期多数市场采用,然后在后期多数人的需求下进入竞争最后是技术落后者。如果这项技术无法跨越鸿沟,那么它将最终陷入历史的垃圾箱。但是,使AI与众不同的是,它不适合技术采用生命周期的模式。
这种兴趣、投资、炒作、然后下降、反复冲洗和重复的模式对于技术人员和投资者而言尤其令人烦恼,因为它没有遵循通常的技术采用生命周期。在杰弗里·摩尔(Geoffrey Moore)的著作《穿越鸿沟》中得到普及,技术的采用通常遵循明确的路径。技术得到了发展,并首先被创新者和早期采用者所发现,如果该技术能够跨越“鸿沟”,它就会被早期多数市场采用,然后在后期多数人的需求下进入竞争最后是技术落后者。如果这项技术无法跨越鸿沟,那么它将最终陷入历史的垃圾箱。但是,使AI与众不同的是,它不适合技术采用生命周期的模式。
但是AI并不是离散技术。相反,它是一系列技术,概念和方法,所有这些都与对智能机器的追求保持一致。这一追求激发了学者和研究人员提出关于大脑和智力如何工作的理论,以及他们关于如何利用技术模仿这些方面的概念。人工智能是技术的产生者,它们分别贯穿技术生命周期。投资者不是在投资“AI”,而是投资于可以帮助实现AI目标的AI研究和技术成果;随着研究人员发现有助于他们克服先前挑战的新见解,或者最终成为技术基础架构赶上以前不可行的概念,然后产生新技术,并更新投资周期。
需要理解
显然,智力就像洋葱一样有很多层。一旦理解了一层,我们就会发现它仅解释了关于智能的有限内容。我们发现还有一个尚未完全了解的层,然后回到我们的研究机构,我们去弄清楚它是如何工作的。在Cognilytica 对语音助手智能的探索中,该基准旨在挑逗揭示下一层:理解。就是说,知道什么是东西,在经过训练的概念类别中识别图像,将音频波形转换为单词,在一组数据中识别模式,甚至玩高级游戏,都与实际了解这些东西不同。缺乏理解是为什么用户会从语音助手的问题中得到热烈的回答,也是为什么我们在很多情况下都无法真正获得自主机器功能的原因。没有理解,就没有常识。没有常识和理解,机器学习只是一堆学习的模式,无法适应现实世界不断变化的变化。
有助于理解这些不断增加的价值的视觉概念之一是“ DIKUW金字塔 ”:
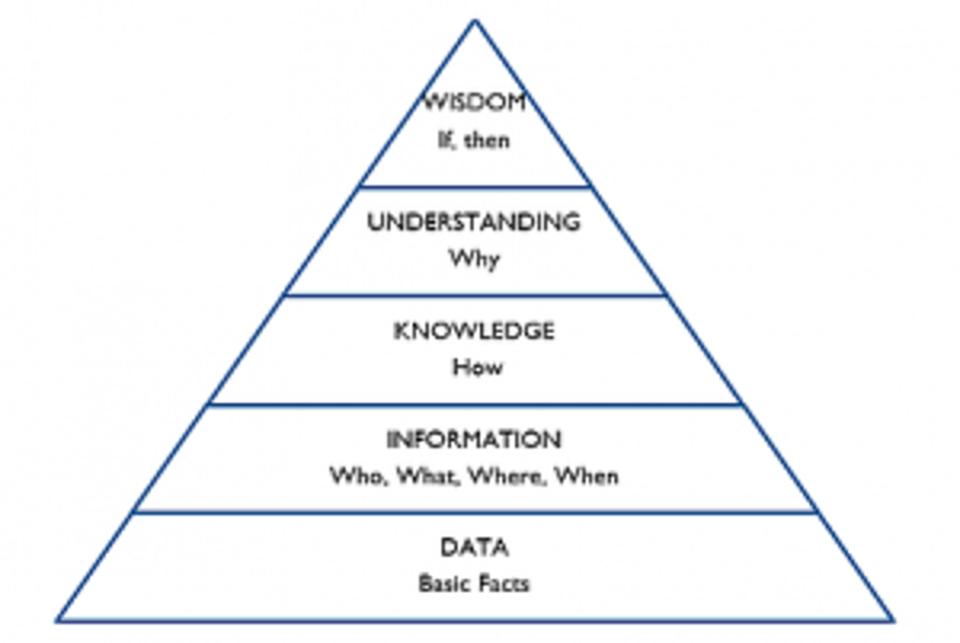
尽管上面的Wikipedia条目方便地跳过了其条目中的“理解”步骤,但我们认为,理解是AI能力的下一个逻辑门槛。与该AI洋葱的所有先前层一样,应对这一层将需要新的研究突破,计算能力的显着提高以及数据量。什么?我们难道没有几乎无限的数据和无限的计算能力吗?
追求常识:机器推理
在人工智能发展的早期,研究人员意识到,要使机器成功地在现实世界中导航,他们必须了解世界如何运转以及各种不同事物如何相互关联。1984年,世界上寿命最长的AI项目开始了。Cyc项目的重点是生成关于世界如何运转的全面“本体”和常识,基本概念以及“经验法则”的知识库。Cyc本体使用知识图来构造不同概念之间的相互关系,并使用推理引擎使系统对事实进行推理。
Cyc和其他建立理解的知识编码背后的主要思想是认识到,如果系统不了解他们正在识别或分类的基础事物是什么,那么它们就无法真正地智能化。这意味着我们必须比机器学习更深入地研究智能。我们需要将洋葱去皮更深一层,然后挖出另一个美味的冻糕层。我们不仅需要机器学习,还需要机器推理。 机器理性是赋予机器力量以在事实,观察结果和我们可以训练机器进行机器学习的所有神奇事物之间建立联系的概念。机器学习已实现了广泛的功能和功能,并开辟了一个可能的世界,如果没有训练机器来识别和识别数据模式的能力,这是不可能的。但是,这些系统无法真正在功能上将信息用于更高端,或者在没有人工参与的情况下将一个领域的学习应用于另一个领域,这一事实削弱了这种能力。甚至转移学习的应用也受到限制。
机器理性是赋予机器力量以在事实,观察结果和我们可以训练机器进行机器学习的所有神奇事物之间建立联系的概念。机器学习已实现了广泛的功能和功能,并开辟了一个可能的世界,如果没有训练机器来识别和识别数据模式的能力,这是不可能的。但是,这些系统无法真正在功能上将信息用于更高端,或者在没有人工参与的情况下将一个领域的学习应用于另一个领域,这一事实削弱了这种能力。甚至转移学习的应用也受到限制。
确实,我们正在迅速面对一个现实,即将以面向机器学习的AI克服当前功能的障碍。为了达到更高的水平,我们需要突破这堵墙,从以机器学习为中心的AI转变为以机器推理为中心的AI。但是,这将需要一些我们尚未意识到的研究突破。
Cyc项目是寿命最长的AI项目而与众不同,这一事实有点反驳。Cyc项目之所以存在很长一段时间,是因为在过去的几十年中,对常识知识的追求被证明是遥不可及的。将常识编码成机器可处理的形式是一个巨大的挑战。您不仅需要以机器知道您在说什么的方式对实体本身进行编码,而且还需要编码这些实体之间的所有相互关系。机器需要知道的数百万甚至数十亿的“事物”。其中一些东西是有形的,例如“雨”,而另一些则是无形的,例如“口渴”。编码这些关系的工作是部分自动化的,但是仍然需要人工来验证连接的准确性。因为毕竟,如果机器能够做到这一点,我们将解决机器识别方面的挑战。这样有点像鸡和鸡蛋的问题。如果没有某种方法来整理信息之间的关系,就无法解决机器识别问题。但是,如果没有某种形式的自动化,就无法将机器需要知道的所有关系进行整理。 我们仍然受到数据和计算能力的限制吗?
我们仍然受到数据和计算能力的限制吗?
事实证明,机器学习非常耗费数据和计算量。在过去的十年中,许多迭代增强功能减轻了计算负荷,并帮助提高了数据使用效率。GPU,TPU和新兴的FPGA正在帮助提供所需的原始计算能力。然而,尽管有了这些进步,但是具有许多维度和参数的复杂机器学习模型仍然需要大量的计算和数据。机器推理很容易是机器学习之外的一个或多个复杂性。完成推理事物之间复杂关系并真正理解这些事物的任务可能超出了当今的计算和数据资源。
当前对人工智能的兴趣和投资浪潮没有任何迹象表明会很快放缓或停止,但不可避免的是,出于某种简单的原因,它会在某个时候放缓:我们仍然不了解智能及其运作方式。尽管研究人员和技术人员做出了惊人的贡献,但我们仍在黑暗中猜测认知,智力和意识的神秘本质。在某个时候,我们将面临假设和实现方式的局限性,我们将努力将洋葱剥去一层,以应对下一组挑战。机器推理正在迅速接近,这是我们在寻求人工智能时必须克服的下一个挑战。如果我们可以运用我们的研究和投资人才来解决这一问题,我们可以通过AI研究和投资来保持发展势头。否则,AI模式将重演,并且当前的波峰将到来。可能不是现在,甚至在未来几年之内,但AI的潮起潮落却不可避免。





























