












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






初学者福利!无需编码,使用KNIME构建你的第一个机器学习模型
2017年08月22日 由 yining 发表
681893
0
对初学者来说,有太多的东西需要同时学习是机器学习面临的最大挑战之一,特别在你不知道如何编码的情况下。如果你没有过编写代码的经验,那么你可以使用GUI驱动的工具开始学习数据科学。这篇文章将首先介绍一个基于GUI的工具-KNIME。到本文结束时,你将能够在不编写代码的情况下预测零售商店的销售情况。

KNIME是一个基于GUI的工作流建立的强大的分析平台。这意味着,你不需要知道如何编写代码就可以使用KNIME,并获得深入的见解。你可以执行从基本的输入输出到数据操作、转换和数据挖掘等功能。它将整个流程的所有功能整合到一个单独的工作流中。
下面让我们开始吧!
首先需要安装KNIME,并将它设置在你的PC上。
步骤1:访问 www.knime.com/downloads

步骤2:为你的PC确定正确的版本。
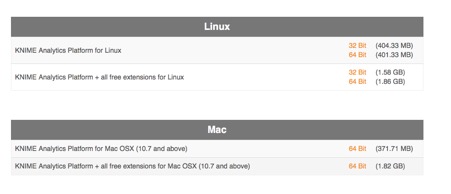
步骤3:安装该平台,并为KNIME设置工作目录以存储其文件。

这就是你的主屏幕在KNIME上的样子。
1.1创建你的第一个工作流
在我们深入了解KNIME的工作原理之前,让我们先定义几个关键术语来帮助我们理解,然后看看如何在KNIME中开创一个新的项目。
节点(Node):节点是任何数据操作的基本处理点。它可以根据你在工作流程中选择的内容进行多种操作。
工作流(Workflow):工作流是你在平台上完成特定任务的步骤或操作的序列。
左上角的Workflow Coach将向你展示KNIME社区中所推荐的特定节点的百分比。Node Repository(节点存储库)将显示特定工作流所拥有的所有节点,这取决于你的需求。一旦你创建了第一个工作流,你还可以去“Browse Example Workflows(浏览示例工作流)”查看更多的工作流。这是向任何问题构建解决方案的第一步。
要设置工作流,你可以遵循以下步骤。
步骤1:找到File菜单,点击New。

步骤2:在你的平台中创建一个新的KNIME工作流,并将其命名为“Introduction”。
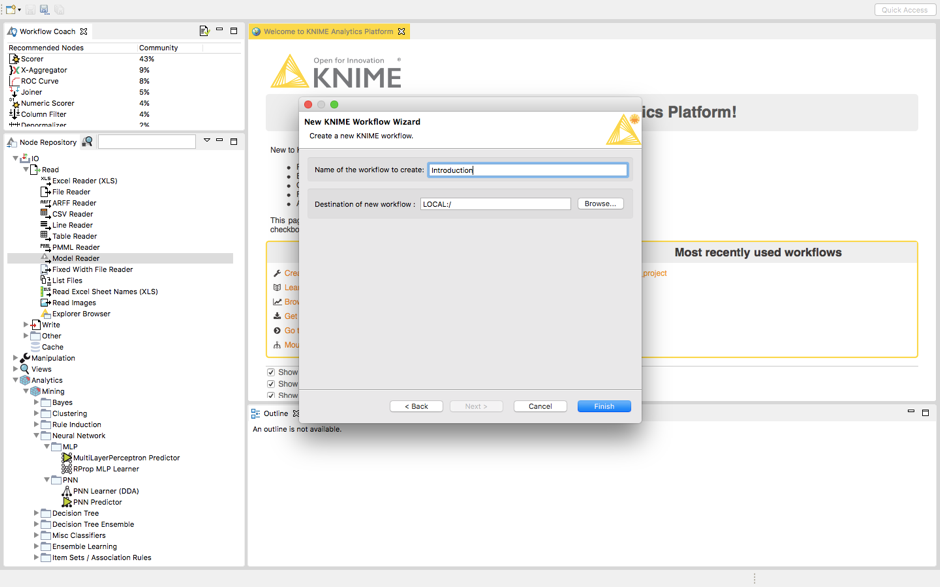
步骤3:当你点击Finish时,你应该已经成功地创建了你的第一个KNIME工作流。
这只是你在KNIME上的空白工作流。现在,你可以通过从repository中拖拽任何节点到你的工作流中来探索和解决任何问题。
KNIME是一个平台,在今天的数据科学的边界上,它可以帮助我们解决任何我们可能想到的问题,从最基本的可视化或线性回归到高级深度学习的主题,KNIME可以做到这一切。
作为一个示例,我们在本教程中要解决的问题是在Datahack中可以访问的“Big Mart Sales(大商场销售)”实践问题。地址:https://datahack.analyticsvidhya.com/contest/practice-problem-big-mart-sales-iii/
问题陈述如下:
Big Mart的数据科学家收集了2013年在不同城市的10家商店的1559种产品的销售数据。此外,还定义了每个产品和商店的某些属性。其目的是建立一个预测模型,并找出每个产品在特定商店的销售情况。
使用这个模型,Big Mart将尝试了解产品和商店的属性,这些特性在增加销售中起着关键的作用。
2.1导入数据文件
让我们从第一步开始,导入我们的数据。
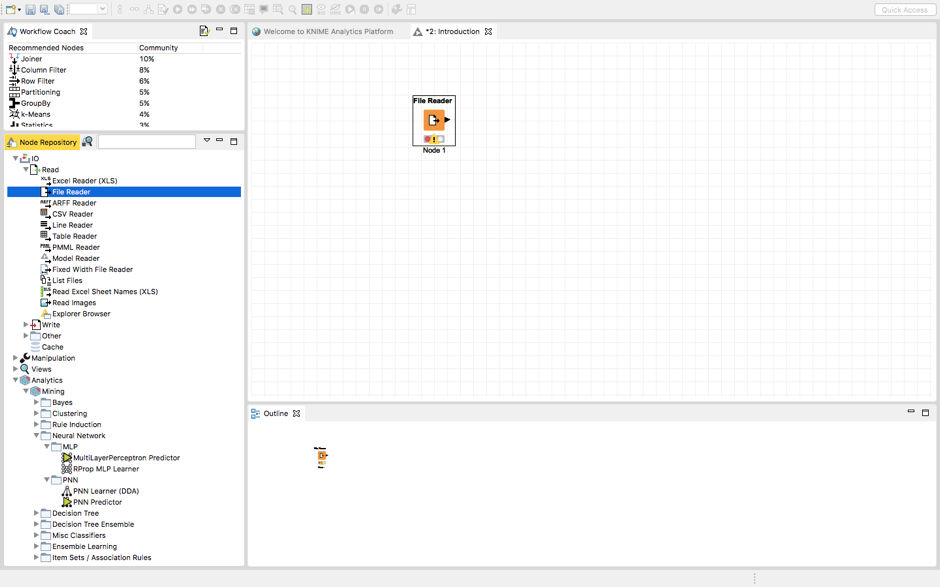
将“file reader”节点拖放到工作流中,并双击它。接下来,浏览需要导入到工作流程中的文件。
在这篇文章中,我们将学习如何解决“Big Mart Sales”的实践问题,我将从大商场的销售中导入训练数据集。
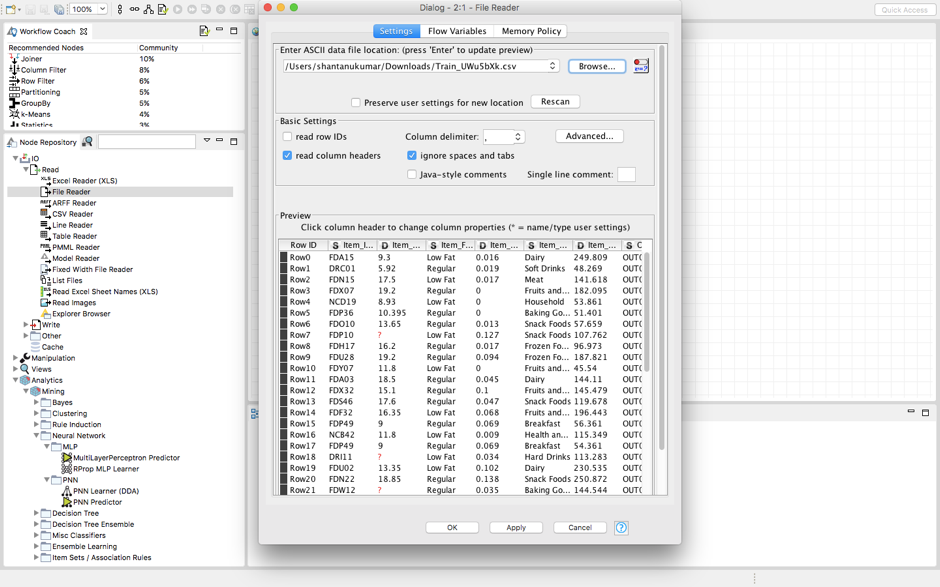
当你导入数据集时,这就是预览后的样子。
让我们将一些相关的列形象化,并找出它们之间的相关性(Correlation)。相关性帮助我们发现哪些列可能相互关联,并在最终的结果上具有更高的预测能力来帮助我们。
为了创建一个关联矩阵,我们在node repository中输入“Linear Correlation”,然后将其拖放到我们的工作流中。
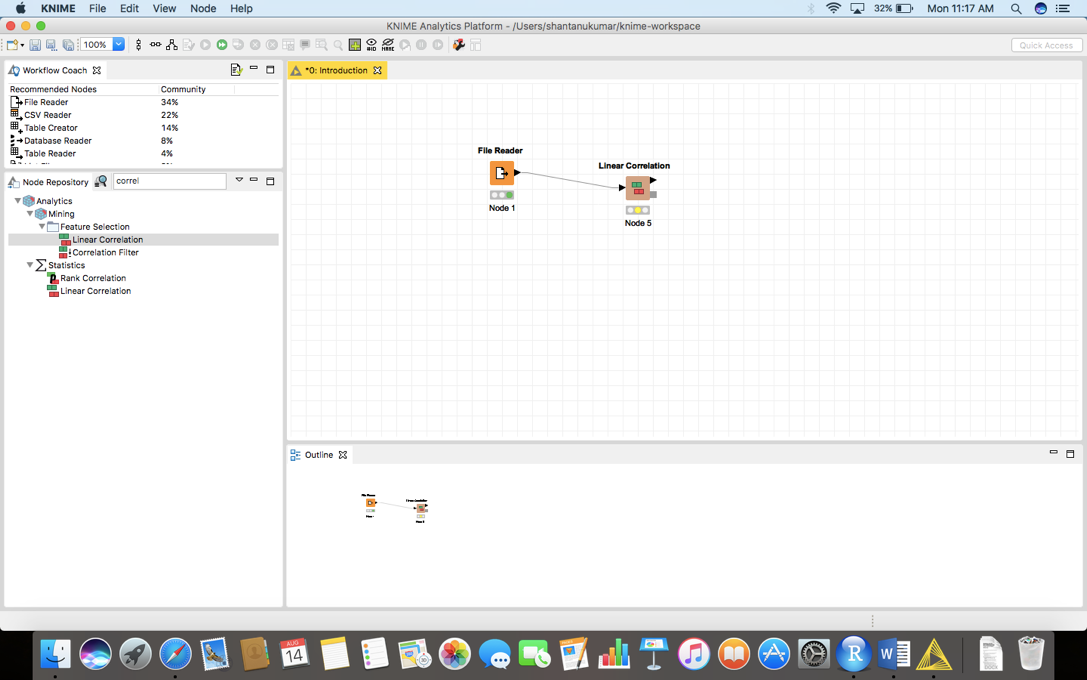
在像显示的那样拖放之后,我们将把文件阅读器的输出连接到节点的“Linear Correlation”的输入。点击顶部面板上的绿色按钮“Execute”。现在右键单击相关节点并选择“View: Correlation Matrix”来生成下图。
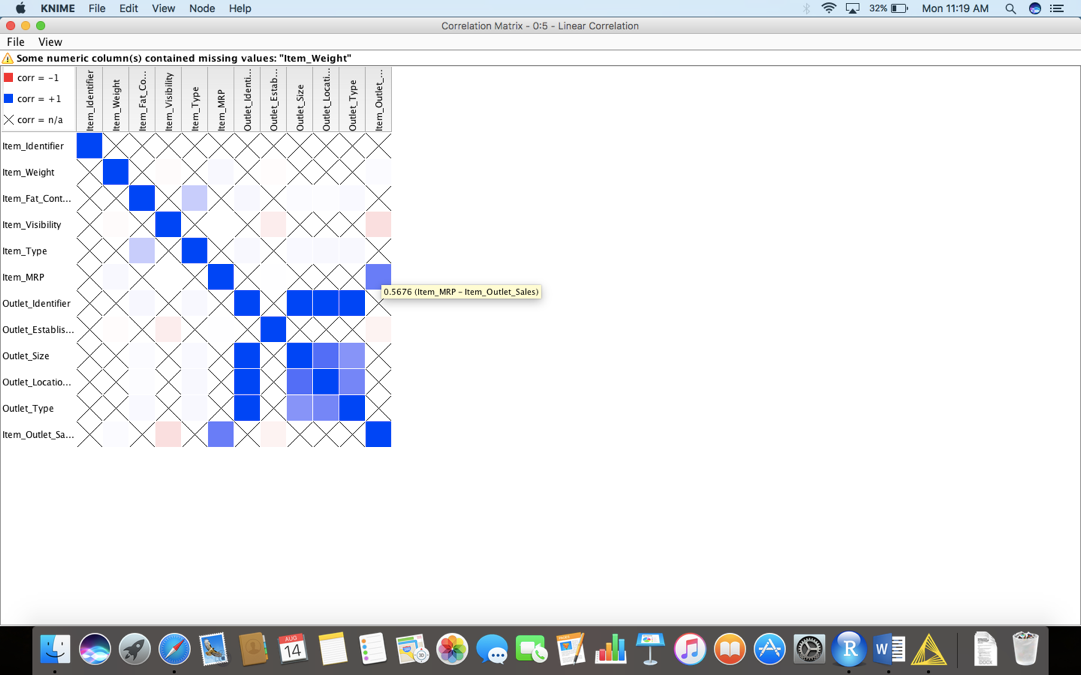
这将帮助你选择那些重要的特性,并通过在特定的储存格上悬停(hover)来获得更好的预测。接下来,我们将对数据集的范围和模式进行可视化,以便更好地理解它。
2.2可视化和分析
我们想从数据中了解到的最重要的事情之一是,哪些商品被卖得最多。有两种解释信息的方式:
1.Scatterplot(散点图)
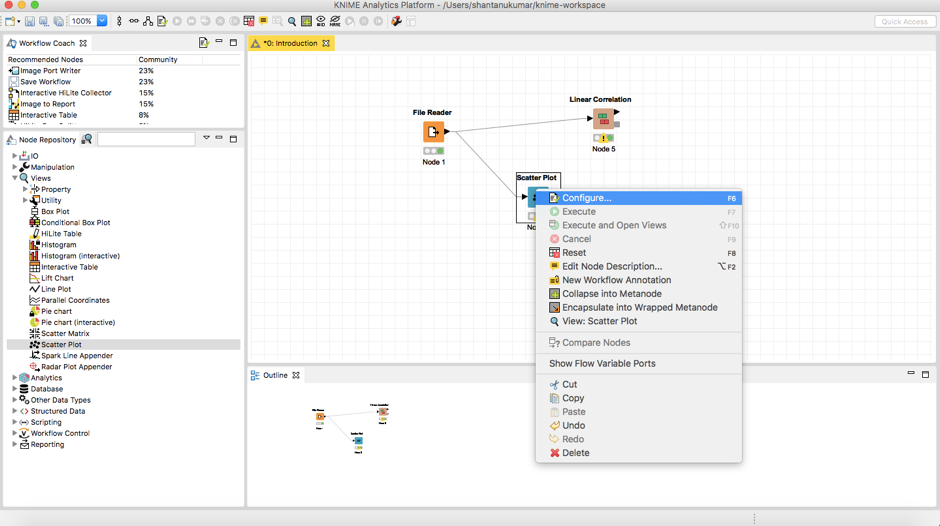
在我们的node repository的视图选项卡下搜索“Scatter Plot”。将其拖放到与你的工作流类似的方式中,并将文件阅读器的输出连接到该节点。接下来,配置你的节点来选择需要的数据的行数(我选择了3000),并希望可视化。
单击execute,然后View: Scatter Plot。
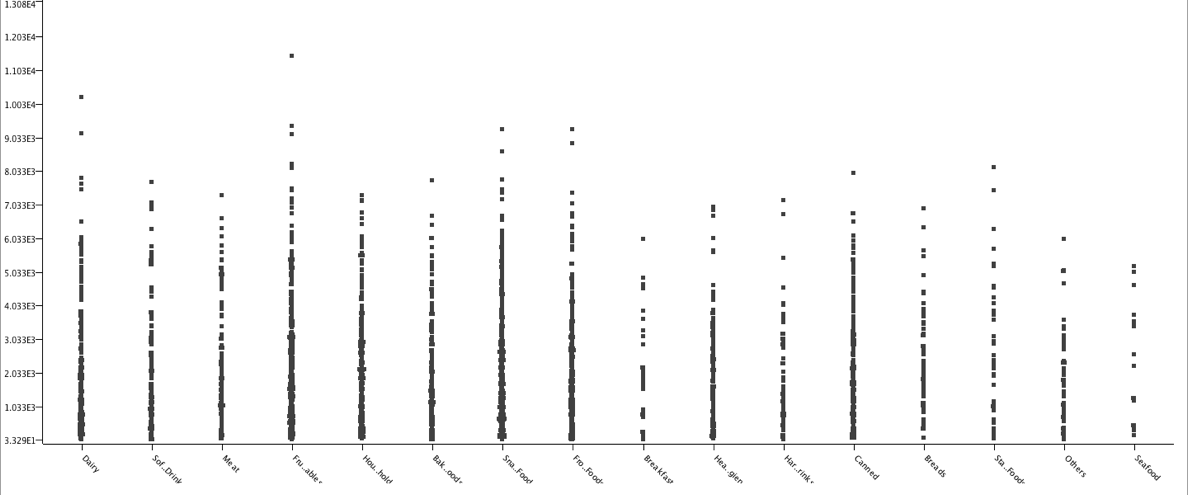
我选择了X轴为Item_Type,Y轴为Item_Outlet_Sales。
上面的图代表每一种商品类型的销售,可以看出水果和蔬菜的销售量是最高的。
2.Pie Chart(饼形图)
为了理解数据库中所有产品类型的平均销售估计,我们将使用饼形图。
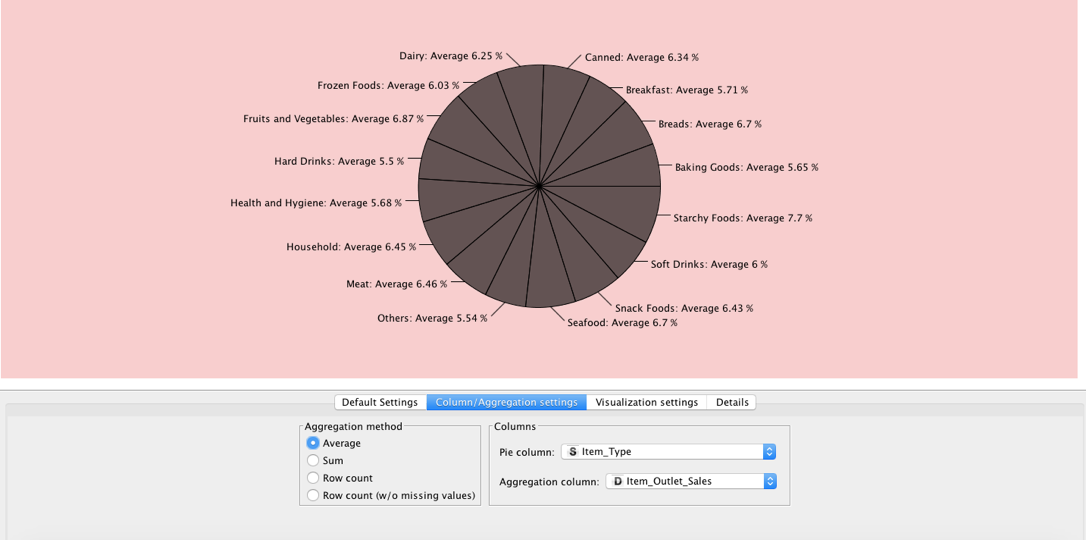
单击Views下的Pie Chart node并将其连接到你的文件阅读器。选择你需要的用于隔离的列,并选择你喜欢的聚合方法,然后应用。
这张图表显示的是销售在各种产品上的平均分配。“Starchy Foods(淀粉类食品)”的平均销售额达到了7.7%。
我只使用了两种类型的视觉效果,尽管你可以在浏览“Views”选项卡时,以多种形式浏览数据。你可以使用直方图、折线图等来更好地可视化你的数据。
在训练你的模型之前,你可以在你的方法中包括数据清洗和特征提取。在这里,我将介绍KNIME中数据清洗步骤的概述。
为了进一步理解,请遵循“数据探索和特性工程”这篇文章的内容。文章地址:https://www.analyticsvidhya.com/blog/2016/01/guide-data-exploration/
3.1寻找缺失值(Missing Values)
在我们虚拟估算值之前,我们需要知道哪些值是缺失的。
再次访问node repository,并找到节点“Missing Values”。拖放它,并将我们的文件阅读器的输出连接到节点。
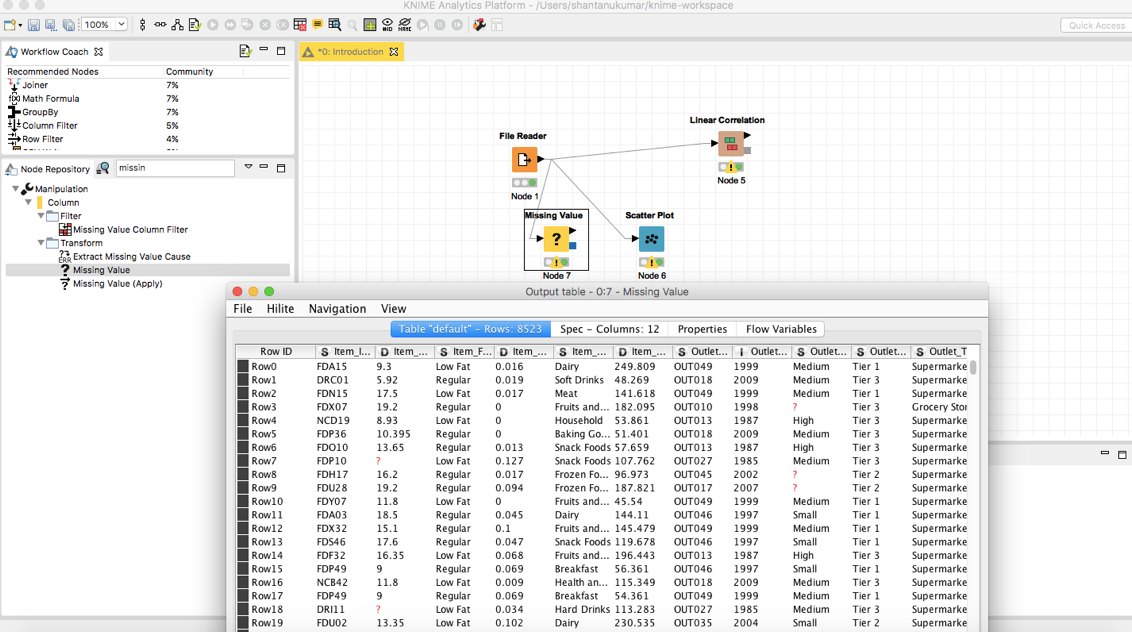
3.2虚拟估算值(Imputations)
要虚拟估算值时,选择节点Missing Values,然后单击configure。根据所需要的数据类型选择适当的数据,然后“Apply”。
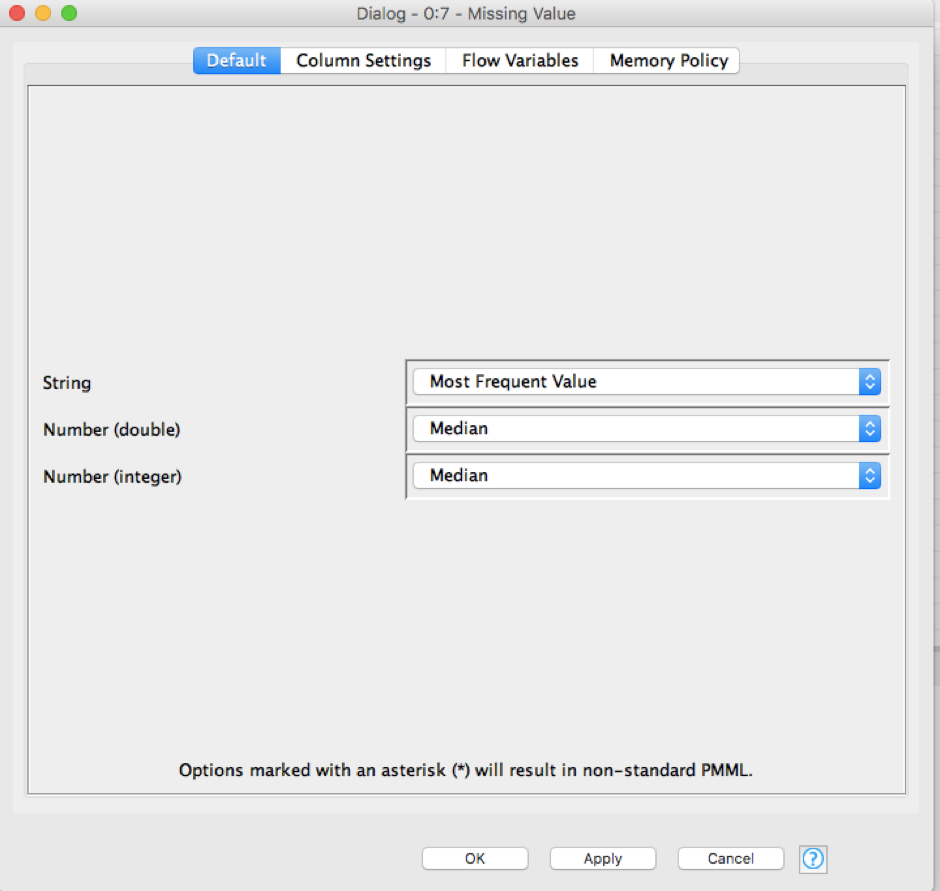
现在,当我们执行它时,带有估算值的完整数据集将在节点的输出端口“Missing Values”中准备好。在我的分析中,我选择了这些方法:
字符串(String):最常见的值
数字(双)(Number(Double)):中值
数字(整)(Number(Integer)):中值
你可以从各种各样的虚拟估值技巧中选择:
字符串:
数字(双和整):
让我们来看看如何在KNIME中构建一个机器学习模型。
4.1实现线性模型
首先,我们训练一个包含数据集所有特性的线性模型,以了解如何选择特性和构建模型。
访问你的node repository,并将“Linear Regression Learner”拖到你的工作流中。然后将在“Missing Value”节点的“Output Port(输出端口)”中收集的清洗数据连接起来。
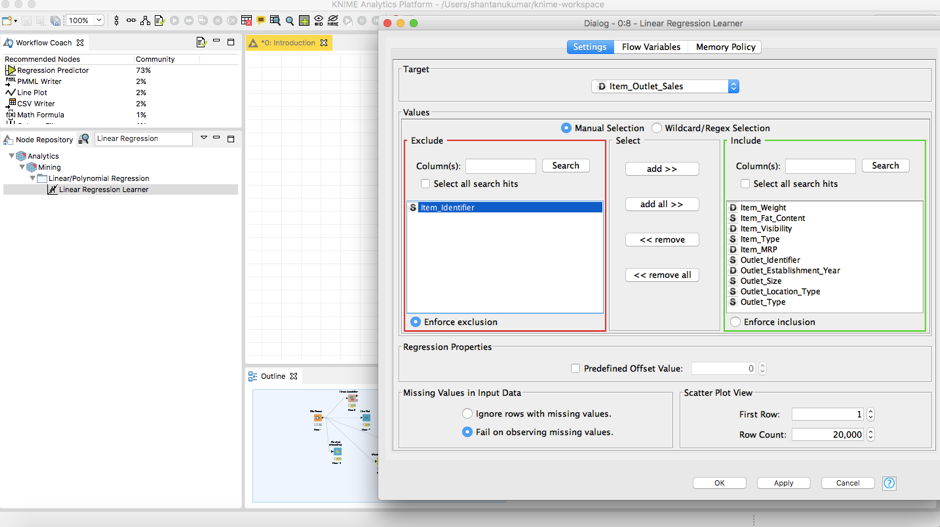
这应该是你现在的屏幕视觉。在configuration选项卡中,排除Item_Identifier,并在顶部选择目标变量。完成此任务后,需要导入Test data(测试数据)以运行你的模型。
将另一个文件阅读器拖放到你的工作流中,并从你的系统中选择测试数据。
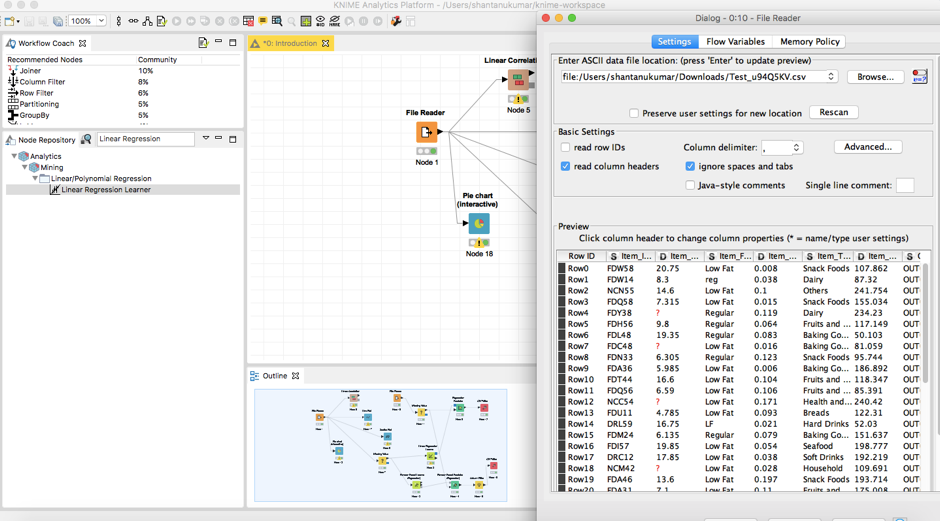
正如我们所看到的,测试数据也包含了缺失值。我们将以与训练数据相同的方式运行“Missing Value”节点。
在我们对测试数据进行清洗之后,我们将引入一个新的节点“Regression Predictor(回归预测器)”。
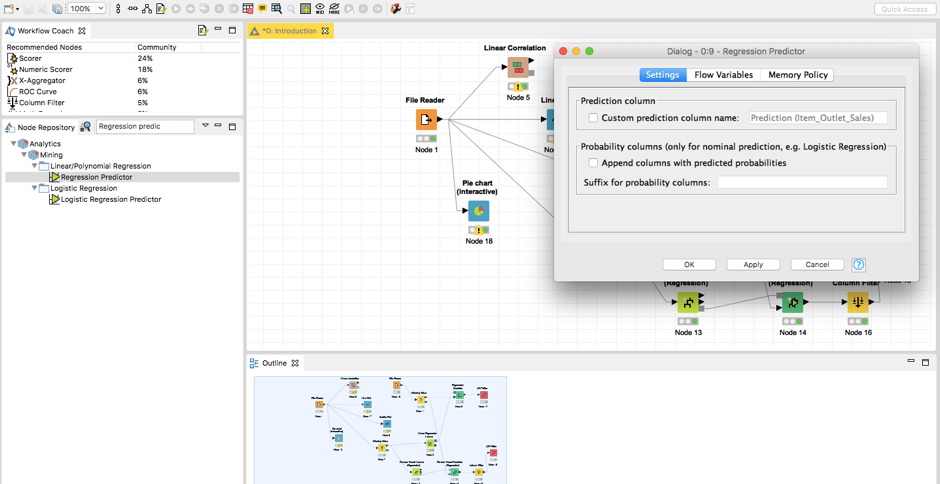
通过将learner的输出与预测器的输入连接起来,将模型加载到预测器中。在预测器的第二个输入中,加载你的测试数据。
预测器会根据你的learner自动调整预测栏,你也可以手动修改它。
KNIME有能力在“Analytics”标签下训练一些非常专业的模型。比如:
在你执行预测器之后,输出几乎已经准备好提交了。
在你的node repository中找到节点“Column Filter(列筛选)”,并将其拖到你的工作流中。将你的预测器的输出连接到列筛选中,并将其配置为你需要的过滤出的列。在这种情况下,你需要Item_Identifier, Outlet_Identifier和 Outlet_Sales的预测。
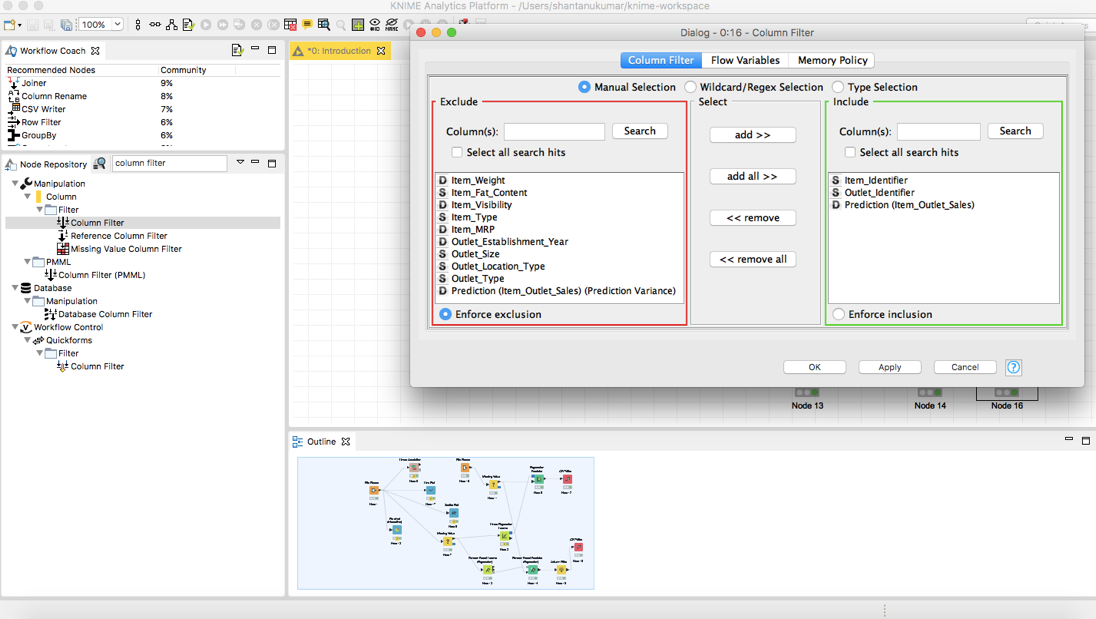
执行“Column Filter”,最后搜索节点“CSV Writer”,并记录下你的硬盘驱动器上的预测。
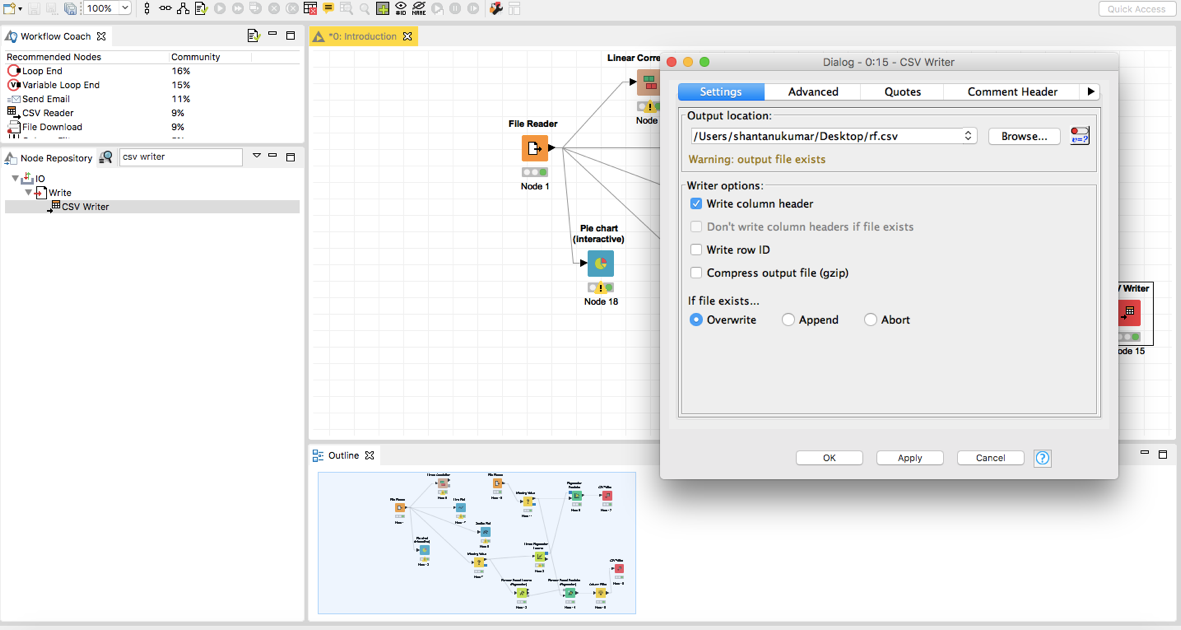
调整路径来设置你想要的.csv文件存储,并执行该节点。最后,打开.csv文件来纠正列名作为我们的解决根据。将.csv文件变为一个.zip(压缩)文件并提交你的解决方案!
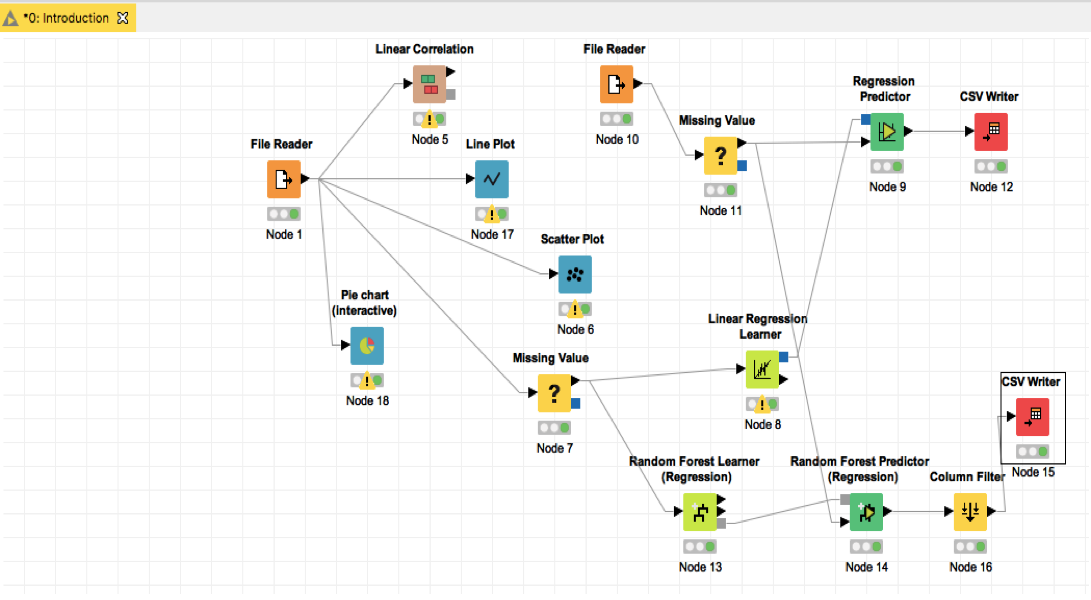
这是获得的最后一个工作流图。如果想导出一个KNIME工作流,你可以:点击File ->Export KNIME Workflow
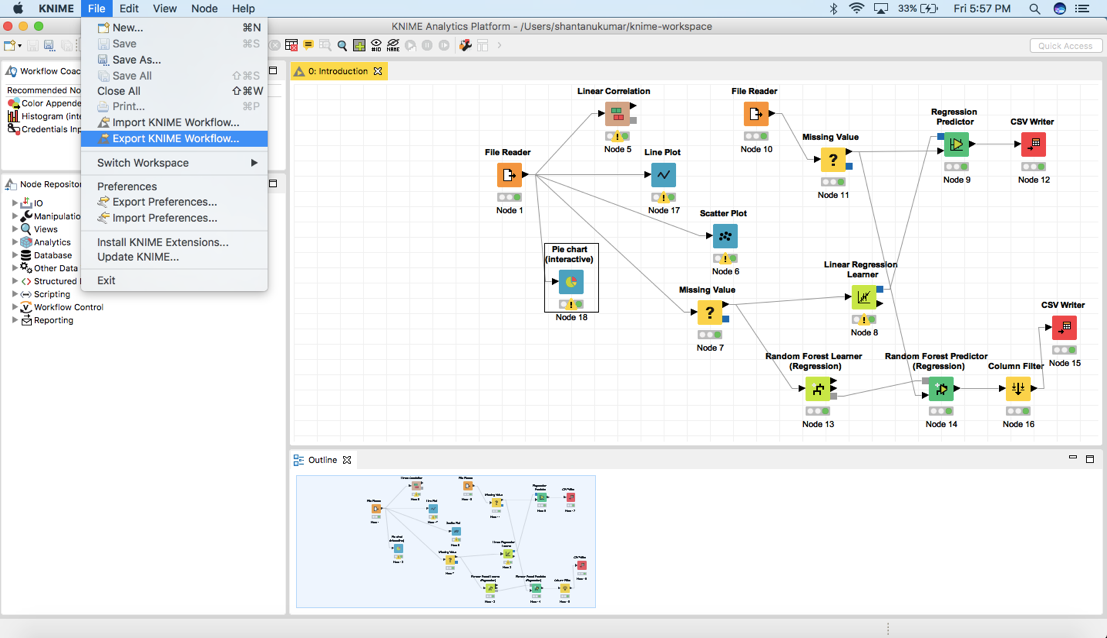
在此之后,选择需要导出的合适的工作流并单击Finish!
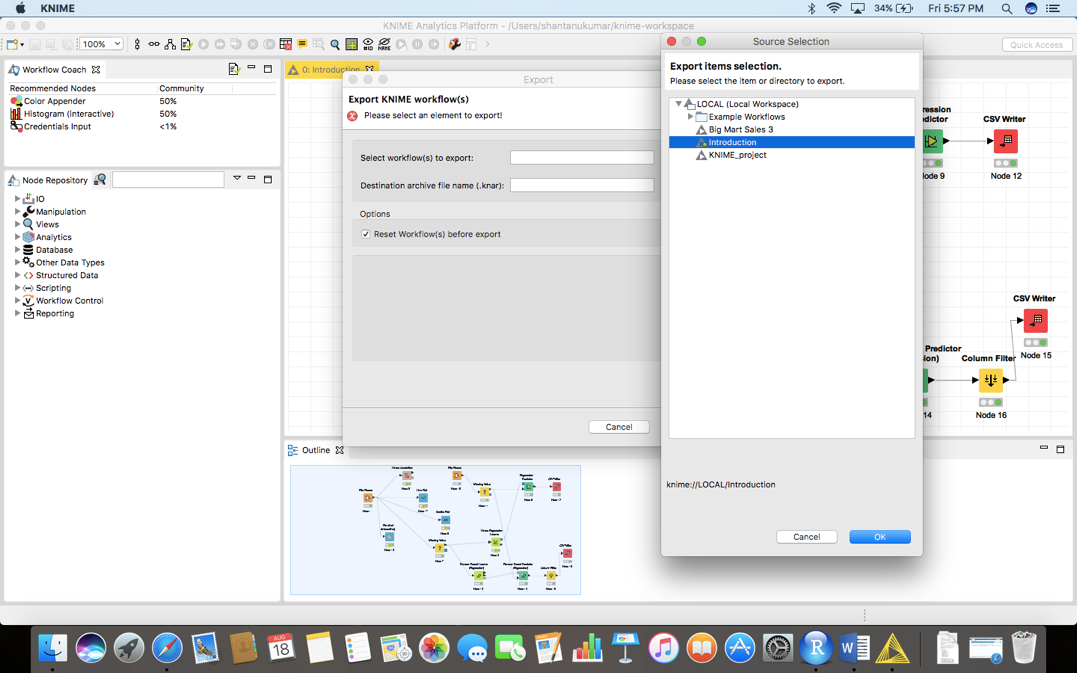
这将创建一个.knwf文件,你可以把它发送给任何人,只要点击一下就可以访问它了!
KNIME是一种非常强大的开源工具,但它有自己的局限性。主要包括:
为什么选择KNIME?
KNIME是一个基于GUI的工作流建立的强大的分析平台。这意味着,你不需要知道如何编写代码就可以使用KNIME,并获得深入的见解。你可以执行从基本的输入输出到数据操作、转换和数据挖掘等功能。它将整个流程的所有功能整合到一个单独的工作流中。
下面让我们开始吧!
1.设置系统
首先需要安装KNIME,并将它设置在你的PC上。
步骤1:访问 www.knime.com/downloads
步骤2:为你的PC确定正确的版本。
步骤3:安装该平台,并为KNIME设置工作目录以存储其文件。
这就是你的主屏幕在KNIME上的样子。
1.1创建你的第一个工作流
在我们深入了解KNIME的工作原理之前,让我们先定义几个关键术语来帮助我们理解,然后看看如何在KNIME中开创一个新的项目。
节点(Node):节点是任何数据操作的基本处理点。它可以根据你在工作流程中选择的内容进行多种操作。
工作流(Workflow):工作流是你在平台上完成特定任务的步骤或操作的序列。
左上角的Workflow Coach将向你展示KNIME社区中所推荐的特定节点的百分比。Node Repository(节点存储库)将显示特定工作流所拥有的所有节点,这取决于你的需求。一旦你创建了第一个工作流,你还可以去“Browse Example Workflows(浏览示例工作流)”查看更多的工作流。这是向任何问题构建解决方案的第一步。
要设置工作流,你可以遵循以下步骤。
步骤1:找到File菜单,点击New。
步骤2:在你的平台中创建一个新的KNIME工作流,并将其命名为“Introduction”。
步骤3:当你点击Finish时,你应该已经成功地创建了你的第一个KNIME工作流。
这只是你在KNIME上的空白工作流。现在,你可以通过从repository中拖拽任何节点到你的工作流中来探索和解决任何问题。
2.介绍KNIME
KNIME是一个平台,在今天的数据科学的边界上,它可以帮助我们解决任何我们可能想到的问题,从最基本的可视化或线性回归到高级深度学习的主题,KNIME可以做到这一切。
作为一个示例,我们在本教程中要解决的问题是在Datahack中可以访问的“Big Mart Sales(大商场销售)”实践问题。地址:https://datahack.analyticsvidhya.com/contest/practice-problem-big-mart-sales-iii/
问题陈述如下:
Big Mart的数据科学家收集了2013年在不同城市的10家商店的1559种产品的销售数据。此外,还定义了每个产品和商店的某些属性。其目的是建立一个预测模型,并找出每个产品在特定商店的销售情况。
使用这个模型,Big Mart将尝试了解产品和商店的属性,这些特性在增加销售中起着关键的作用。
2.1导入数据文件
让我们从第一步开始,导入我们的数据。
将“file reader”节点拖放到工作流中,并双击它。接下来,浏览需要导入到工作流程中的文件。
在这篇文章中,我们将学习如何解决“Big Mart Sales”的实践问题,我将从大商场的销售中导入训练数据集。
当你导入数据集时,这就是预览后的样子。
让我们将一些相关的列形象化,并找出它们之间的相关性(Correlation)。相关性帮助我们发现哪些列可能相互关联,并在最终的结果上具有更高的预测能力来帮助我们。
为了创建一个关联矩阵,我们在node repository中输入“Linear Correlation”,然后将其拖放到我们的工作流中。
在像显示的那样拖放之后,我们将把文件阅读器的输出连接到节点的“Linear Correlation”的输入。点击顶部面板上的绿色按钮“Execute”。现在右键单击相关节点并选择“View: Correlation Matrix”来生成下图。
这将帮助你选择那些重要的特性,并通过在特定的储存格上悬停(hover)来获得更好的预测。接下来,我们将对数据集的范围和模式进行可视化,以便更好地理解它。
2.2可视化和分析
我们想从数据中了解到的最重要的事情之一是,哪些商品被卖得最多。有两种解释信息的方式:
1.Scatterplot(散点图)
在我们的node repository的视图选项卡下搜索“Scatter Plot”。将其拖放到与你的工作流类似的方式中,并将文件阅读器的输出连接到该节点。接下来,配置你的节点来选择需要的数据的行数(我选择了3000),并希望可视化。
单击execute,然后View: Scatter Plot。
我选择了X轴为Item_Type,Y轴为Item_Outlet_Sales。
上面的图代表每一种商品类型的销售,可以看出水果和蔬菜的销售量是最高的。
2.Pie Chart(饼形图)
为了理解数据库中所有产品类型的平均销售估计,我们将使用饼形图。
单击Views下的Pie Chart node并将其连接到你的文件阅读器。选择你需要的用于隔离的列,并选择你喜欢的聚合方法,然后应用。
这张图表显示的是销售在各种产品上的平均分配。“Starchy Foods(淀粉类食品)”的平均销售额达到了7.7%。
我只使用了两种类型的视觉效果,尽管你可以在浏览“Views”选项卡时,以多种形式浏览数据。你可以使用直方图、折线图等来更好地可视化你的数据。
3.如何清洗你的数据?
在训练你的模型之前,你可以在你的方法中包括数据清洗和特征提取。在这里,我将介绍KNIME中数据清洗步骤的概述。
为了进一步理解,请遵循“数据探索和特性工程”这篇文章的内容。文章地址:https://www.analyticsvidhya.com/blog/2016/01/guide-data-exploration/
3.1寻找缺失值(Missing Values)
在我们虚拟估算值之前,我们需要知道哪些值是缺失的。
再次访问node repository,并找到节点“Missing Values”。拖放它,并将我们的文件阅读器的输出连接到节点。
3.2虚拟估算值(Imputations)
要虚拟估算值时,选择节点Missing Values,然后单击configure。根据所需要的数据类型选择适当的数据,然后“Apply”。
现在,当我们执行它时,带有估算值的完整数据集将在节点的输出端口“Missing Values”中准备好。在我的分析中,我选择了这些方法:
字符串(String):最常见的值
数字(双)(Number(Double)):中值
数字(整)(Number(Integer)):中值
你可以从各种各样的虚拟估值技巧中选择:
字符串:
- 下一个值(Next Value)
- 之前的值(Previous Value)
- 自定义值(Custom Value)
- 删除行(Remove Row)
数字(双和整):
- 平均值(Mean)
- 中值(Median)
- 之前的值(Previous Value)
- 下一个值(Next Value)
- 自定义值(Custom Value)
- 线性插值(Linear Interpolation)
- 移动平均线(Moving Average)
4.训练你的第一个模型
让我们来看看如何在KNIME中构建一个机器学习模型。
4.1实现线性模型
首先,我们训练一个包含数据集所有特性的线性模型,以了解如何选择特性和构建模型。
访问你的node repository,并将“Linear Regression Learner”拖到你的工作流中。然后将在“Missing Value”节点的“Output Port(输出端口)”中收集的清洗数据连接起来。
这应该是你现在的屏幕视觉。在configuration选项卡中,排除Item_Identifier,并在顶部选择目标变量。完成此任务后,需要导入Test data(测试数据)以运行你的模型。
将另一个文件阅读器拖放到你的工作流中,并从你的系统中选择测试数据。
正如我们所看到的,测试数据也包含了缺失值。我们将以与训练数据相同的方式运行“Missing Value”节点。
在我们对测试数据进行清洗之后,我们将引入一个新的节点“Regression Predictor(回归预测器)”。
通过将learner的输出与预测器的输入连接起来,将模型加载到预测器中。在预测器的第二个输入中,加载你的测试数据。
预测器会根据你的learner自动调整预测栏,你也可以手动修改它。
KNIME有能力在“Analytics”标签下训练一些非常专业的模型。比如:
- 聚类
- 神经网络
- 集成学习(Ensemble Learners)
- 朴素贝叶斯(Naïve Bayes)
5.提交你的解决方案
在你执行预测器之后,输出几乎已经准备好提交了。
在你的node repository中找到节点“Column Filter(列筛选)”,并将其拖到你的工作流中。将你的预测器的输出连接到列筛选中,并将其配置为你需要的过滤出的列。在这种情况下,你需要Item_Identifier, Outlet_Identifier和 Outlet_Sales的预测。
执行“Column Filter”,最后搜索节点“CSV Writer”,并记录下你的硬盘驱动器上的预测。
调整路径来设置你想要的.csv文件存储,并执行该节点。最后,打开.csv文件来纠正列名作为我们的解决根据。将.csv文件变为一个.zip(压缩)文件并提交你的解决方案!
这是获得的最后一个工作流图。如果想导出一个KNIME工作流,你可以:点击File ->Export KNIME Workflow
在此之后,选择需要导出的合适的工作流并单击Finish!
这将创建一个.knwf文件,你可以把它发送给任何人,只要点击一下就可以访问它了!
6.限制
KNIME是一种非常强大的开源工具,但它有自己的局限性。主要包括:
- 可视化技术并不像其他开源软件(例:RStudio)那样简洁和优雅。
- 版本更新不受支持,你将不得不重新安装软件。(例如:为了更新从版本2到版本3的KNIME,你需要一个全新的安装,而更新将无法工作)。
- 不像Python或CRAN论坛社区那么大,所以需要花很长时间才能对KNIME添加新的内容。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消