












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






使用空气质量数据预测英国的人口死亡率
2017年08月23日 由 yuxiangyu 发表
459084
0
我们又一次在Kaggle竞赛中超过了基准线。比赛的目标是使用哥白尼大气监测服务的空气质量数据预测英国的死亡率。特别是预测癌症和心血管疾病的死亡率。
这些数据包括英国九个地区数年的测量数据。我们的第一步是将训练集分为两部分进行验证,然后运行梯度提升并对预测进行评分。RMSE 0.29 - 优秀,这是排行榜上的最高分。击败的基准是线性回归得分小于0.33。
我们预感到不用立刻上传这些预测。这个预感很正确,因为验证在这场比赛中太大作用。我们从论坛上的一个帖子了解了这一点。通过浏览论坛,我们发现scikit- learn有助于构建时间序列的渐进式验证的功能。
然而,在“模型验证”部分中,检查模型选择模块的内容,我们发现了一个有趣的部分: 置换测试分数。
该函数随机排列标签,然后训练一个模型并预测得分。做完这些足够的时间后,建立样本并得到p值。
最初,我们发现排列标签不会改变验证分数。这表明这些特征是完全不提供信息。
事实是,这个实验是在ipython中一时冲动做的,没有保存代码。后来我们试图重现这个结果,但是失败了。毕竟,验证工作在训练集内。我们为permutation_test.py调整了文档中的示例,并运行了100个排列。
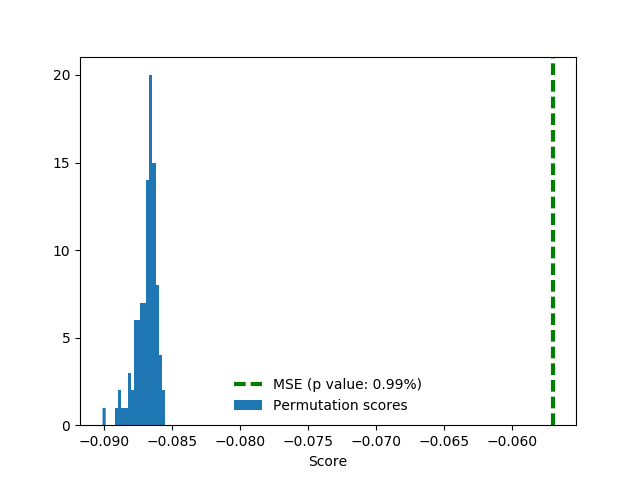
这里的分数为负的均方误差(负数是因为软件取最大值)。在均方根误差中随机排列约为0.29,训练中的真实标签显然更好(P值为0.0099),约为0.24。
请注意,我们在这里使用了交叉验证,这不利于练习时间序列。因此,我们用自己的拆分再次运行测试:
事实证明,以这种方式我们得分更好,约为0.21。值得注意的是随机排列得分一点也有了提高。
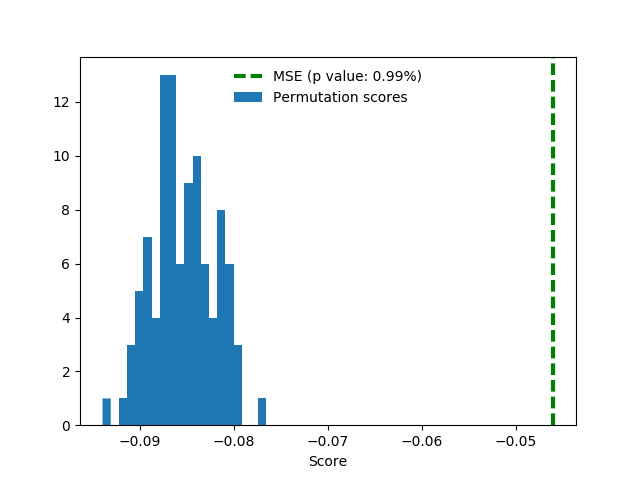
为了很好的测量,这里添加了独热区域特性相同的设置。这些特性没有多大帮助,但也不会耽误得分。
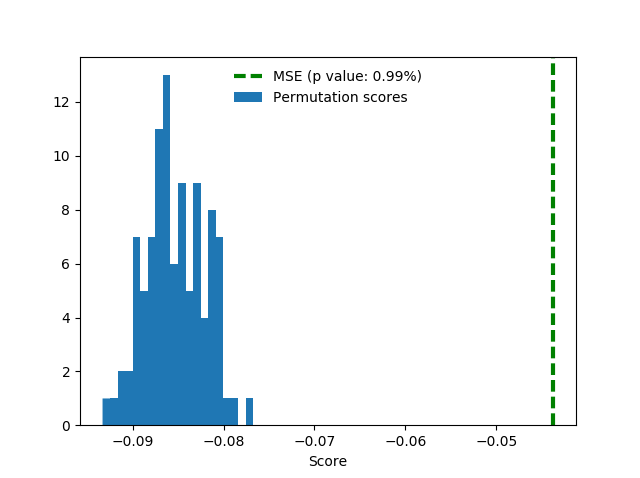
遗憾的是,验证的分数并没有转化成排行榜的得分。
经过了负的验证经验,我们怀疑空气质量特征可能不足以完成工作。毕竟,我们认为也许人们不会死,因为今天的烟雾比以前更多,这与多年来的曝光相反。这引导我们将目标预测为1 - d时间序列,没有额外的特征。我们使用Facebook的Prophet包。
它的工作原理如下:你给它一个适应包含数据(ds)和目标值(y)列的数据框架,以便将来预测一段时间的yhat。该快速启动提供更详细的过程说明。这个库内部采用两个Stan模型,这意味着你需要安装Stan。
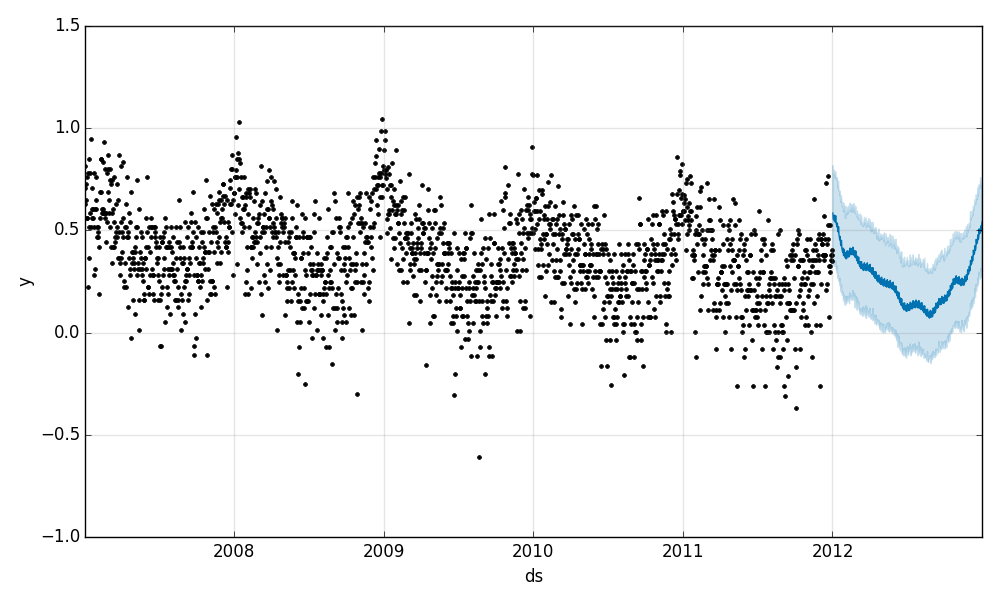
Prophet在训练中产生了收敛,良好的验证分数和好的平面图。不幸的是,如上所述,验证在这场比赛中并不奏效,所以我们留下了这些图。如你所见,预测图虽然不算精确,但看起来很合理:
组件图提供更好的信息 - 死亡率呈下降趋势,我们发现死亡率是周期性的。人们主要在冬季(大约在新年期间)并且集中在星期一和星期五死亡。
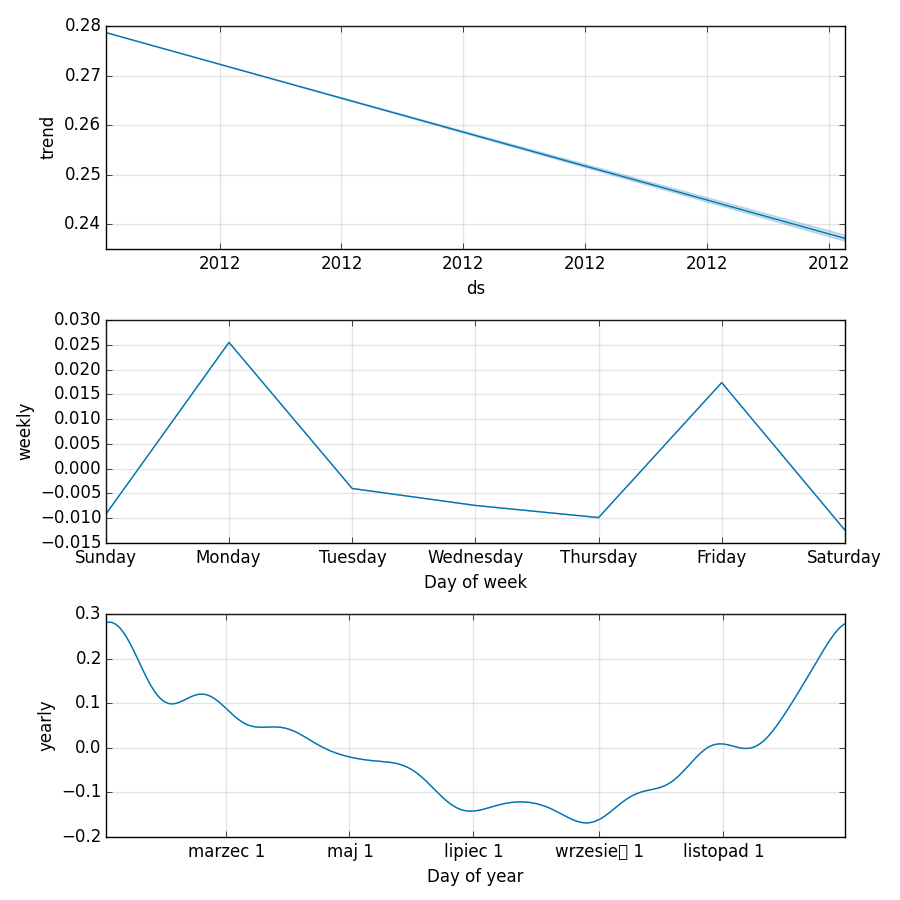
Prophet决定使用波兰语打印这几个月的名字,所以这是你学习:三月,七月,九月,十一月的机会。
这个宝贵的知识允许我们通过添加基于日期的特征:月份、日期和周几来改进线性基准。两者都是独热编码,总共12 + 7 = 19个新的二进制特征。
这次我们不再验证,只要进入排行榜前十就行。
当不使用tree-based的模型时,对列的缩放通常是有意义的。在这里,功特征能具有相似的最大值。T2M除外它更大一些。
使用scikit- learn的MinMaxScaler来扩展功能,可以提高0.00021的得分。我们选择这个标量除了它按原样脱离独热的列之外没什么特别的理由。在我们的经验中,不同标量之间的差异很小,我们发现零矩阵和二进制反码比转换和标准的值更美观。
让我们来检查一下特征权重:
看起来像星期和月份比其他特征更重要。有趣的是,每个组中的权重近乎相同。如果我们只使用月份和星期几的作为特性呢?
这个代码可在GitHub上找到。
由于我们正在缩放,所以现在我们可以把该年作为一项特征。除了缩放之外,我们可以从年值中减去出现在数据中的第一年,以便值能从零开始。第二种方法稍微好一点(排行榜上为0.33496 vs 0.33588),但对得分没有帮助。这有点奇怪,因为死亡率正在下降。也许只是不在测试集中。
当然,我们也尝试使用区域信息。有九个区域,所以独热编码很简单:
我们在训练集中有18k的数据点(删除了null之后是12k),总共只有二三十个功能。这个比例非常好,特别是线性模型。尽管如此,带区域特征的排行榜得分约为0.35 - 0.36,这意味着有过拟合现象。
正如我们可能已经提到的,似乎是其他参与者的经验:无论在验证中做什么,对排行榜得分都没有帮助。
数据有一个特殊性:对于前五个地区,训练集包含截至2012年底的数据。最后三个截止到2011年底。第六个是非常特别的,因为某些原因:它有数据上传到2012-05-27。
在训练集结尾紧接着测试集的开头:
这可以使我们能够使用前五个地区特征中的死亡率来预测四个后四个地区的2012年测试值。
这些数据包括英国九个地区数年的测量数据。我们的第一步是将训练集分为两部分进行验证,然后运行梯度提升并对预测进行评分。RMSE 0.29 - 优秀,这是排行榜上的最高分。击败的基准是线性回归得分小于0.33。
我们预感到不用立刻上传这些预测。这个预感很正确,因为验证在这场比赛中太大作用。我们从论坛上的一个帖子了解了这一点。通过浏览论坛,我们发现scikit- learn有助于构建时间序列的渐进式验证的功能。
然而,在“模型验证”部分中,检查模型选择模块的内容,我们发现了一个有趣的部分: 置换测试分数。
排列测试成绩
该函数随机排列标签,然后训练一个模型并预测得分。做完这些足够的时间后,建立样本并得到p值。
最初,我们发现排列标签不会改变验证分数。这表明这些特征是完全不提供信息。
事实是,这个实验是在ipython中一时冲动做的,没有保存代码。后来我们试图重现这个结果,但是失败了。毕竟,验证工作在训练集内。我们为permutation_test.py调整了文档中的示例,并运行了100个排列。
这里的分数为负的均方误差(负数是因为软件取最大值)。在均方根误差中随机排列约为0.29,训练中的真实标签显然更好(P值为0.0099),约为0.24。
请注意,我们在这里使用了交叉验证,这不利于练习时间序列。因此,我们用自己的拆分再次运行测试:
train_i = d.date.dt.year < 2012
test_i = d.date.dt.year == 2012
# ...
score, permutation_scores, pvalue = permutation_test_score(
clf, x, y, scoring = "neg_mean_squared_error",
cv = [[ train_i, test_i ]],
n_permutations = n_permutations )
事实证明,以这种方式我们得分更好,约为0.21。值得注意的是随机排列得分一点也有了提高。
为了很好的测量,这里添加了独热区域特性相同的设置。这些特性没有多大帮助,但也不会耽误得分。
遗憾的是,验证的分数并没有转化成排行榜的得分。
Prophet
经过了负的验证经验,我们怀疑空气质量特征可能不足以完成工作。毕竟,我们认为也许人们不会死,因为今天的烟雾比以前更多,这与多年来的曝光相反。这引导我们将目标预测为1 - d时间序列,没有额外的特征。我们使用Facebook的Prophet包。
它的工作原理如下:你给它一个适应包含数据(ds)和目标值(y)列的数据框架,以便将来预测一段时间的yhat。该快速启动提供更详细的过程说明。这个库内部采用两个Stan模型,这意味着你需要安装Stan。
Prophet在训练中产生了收敛,良好的验证分数和好的平面图。不幸的是,如上所述,验证在这场比赛中并不奏效,所以我们留下了这些图。如你所见,预测图虽然不算精确,但看起来很合理:
组件图提供更好的信息 - 死亡率呈下降趋势,我们发现死亡率是周期性的。人们主要在冬季(大约在新年期间)并且集中在星期一和星期五死亡。
Prophet决定使用波兰语打印这几个月的名字,所以这是你学习:三月,七月,九月,十一月的机会。
月和日的功能
这个宝贵的知识允许我们通过添加基于日期的特征:月份、日期和周几来改进线性基准。两者都是独热编码,总共12 + 7 = 19个新的二进制特征。
train['day_of_week'] = train.date.dt.dayofweek
train['month'] = train.date.dt.month
test['day_of_week'] = test.date.dt.dayofweek
test['month'] = test.date.dt.month
# assuming that train and test sets have identical sets of values of categorical features
train = pd.get_dummies( train, columns = [ 'day_of_week', 'month' ])
test = pd.get_dummies( test, columns = [ 'day_of_week', 'month' ])
这次我们不再验证,只要进入排行榜前十就行。
缩放列
当不使用tree-based的模型时,对列的缩放通常是有意义的。在这里,功特征能具有相似的最大值。T2M除外它更大一些。
O3 96.284
PM10 59.801
PM25 45.846
NO2 76.765
T2M 297.209
使用scikit- learn的MinMaxScaler来扩展功能,可以提高0.00021的得分。我们选择这个标量除了它按原样脱离独热的列之外没什么特别的理由。在我们的经验中,不同标量之间的差异很小,我们发现零矩阵和二进制反码比转换和标准的值更美观。
让我们来检查一下特征权重:
In [20]: paste
coefs = zip( x_train.columns, lr.coef_ )
for c, i in sorted( coefs, key = lambda _: _[1] ):
print "{:.1f} {}".format( i, c )
## -- End pasted text --
-1.4 NO2
-0.5 T2M
-0.3 O3
0.0 PM25
0.3 PM10
2421203389791.6 month_8
2421203389791.6 month_7
2421203389791.6 month_9
2421203389791.7 month_6
2421203389791.7 month_11
2421203389791.7 month_10
2421203389791.7 month_5
2421203389791.8 month_3
2421203389791.8 month_4
2421203389791.8 month_2
2421203389791.9 month_12
2421203389792.0 month_1
5373781166879.9 day_of_week_6
5373781166879.9 day_of_week_5
5373781166880.0 day_of_week_3
5373781166880.0 day_of_week_2
5373781166880.0 day_of_week_0
5373781166880.0 day_of_week_1
5373781166880.0 day_of_week_4
看起来像星期和月份比其他特征更重要。有趣的是,每个组中的权重近乎相同。如果我们只使用月份和星期几的作为特性呢?
这个代码可在GitHub上找到。
什么不起作用
由于我们正在缩放,所以现在我们可以把该年作为一项特征。除了缩放之外,我们可以从年值中减去出现在数据中的第一年,以便值能从零开始。第二种方法稍微好一点(排行榜上为0.33496 vs 0.33588),但对得分没有帮助。这有点奇怪,因为死亡率正在下降。也许只是不在测试集中。
当然,我们也尝试使用区域信息。有九个区域,所以独热编码很简单:
d = pd.get_dummies( d, columns = [ 'region' ])
我们在训练集中有18k的数据点(删除了null之后是12k),总共只有二三十个功能。这个比例非常好,特别是线性模型。尽管如此,带区域特征的排行榜得分约为0.35 - 0.36,这意味着有过拟合现象。
正如我们可能已经提到的,似乎是其他参与者的经验:无论在验证中做什么,对排行榜得分都没有帮助。
什么起作用
数据有一个特殊性:对于前五个地区,训练集包含截至2012年底的数据。最后三个截止到2011年底。第六个是非常特别的,因为某些原因:它有数据上传到2012-05-27。
In [16]: train.groupby( 'region' ).date.max().sort_index()
Out[16]:
region
E12000001 2012-12-31
E12000002 2012-12-31
E12000003 2012-12-31
E12000004 2012-12-31
E12000005 2012-12-31
E12000006 2012-05-27
E12000007 2011-12-31
E12000008 2011-12-31
E12000009 2011-12-31
在训练集结尾紧接着测试集的开头:
In [18]: test.groupby( 'region' ).date.min().sort_index()
Out[18]:
region
E12000001 2013-01-01
E12000002 2013-01-01
E12000003 2013-01-01
E12000004 2013-01-01
E12000005 2013-01-01
E12000006 2012-05-28
E12000007 2012-01-01
E12000008 2012-01-01
E12000009 2012-01-01
这可以使我们能够使用前五个地区特征中的死亡率来预测四个后四个地区的2012年测试值。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消