谷歌新应用程序:可以对语音进行实时转录
2019年12月22日 由 KING 发表
361676
0
在过去的20年中,谷歌向公众提供了大量的信息,从文本、照片和视频到地图和其他内容。但是,世界上有许多信息是通过语音传达的。然而,即使我们使用录音设备来记录对话、访谈、演讲等内容中的重要信息,但要在以后的几个小时的记录中解析、识别和提取感兴趣的信息还是很困难的。
因此,谷歌创建了Recorder,这是一种新型音频记录应用程序,它利用机器学习的最新发展来转录对话,以检测和识别记录的音频类型(从音乐或语音等广泛的类别到特定的声音,例如掌声,笑声和吹口哨),并为录音编制索引,以便用户可以快速找到并提取感兴趣的片段。所有这些功能都完全在设备上运行,而无需互联网连接。
[video width="1280" height="720" mp4="https://www.atyun.com/uploadfile/2019/12/Introducing-a-New-Kind-of-Audio-Recorder.mp4"][/video]
转录
该应用程序使用自动语音识别模型实现转录语音,该模型可以准确转录长时间录音(几个小时),同时还可以通过将单词映射到语音识别模型计算出的时间戳来索引会话。这使用户可以单击转录中的一个单词,并从录音中的该点开始播放,或者搜索一个单词并跳到录音中所说的确切点。
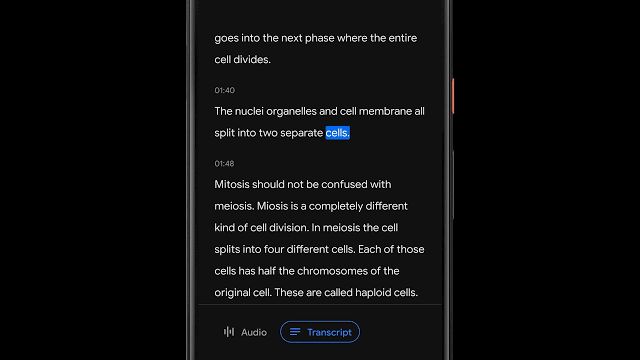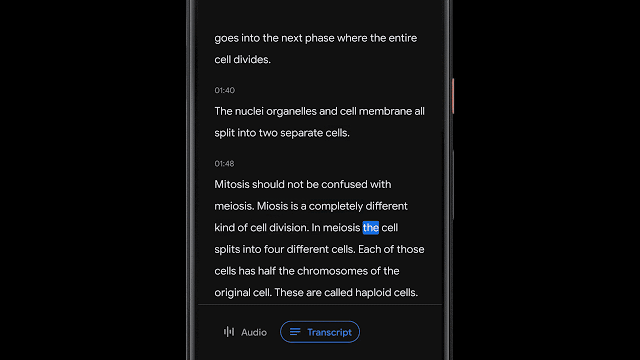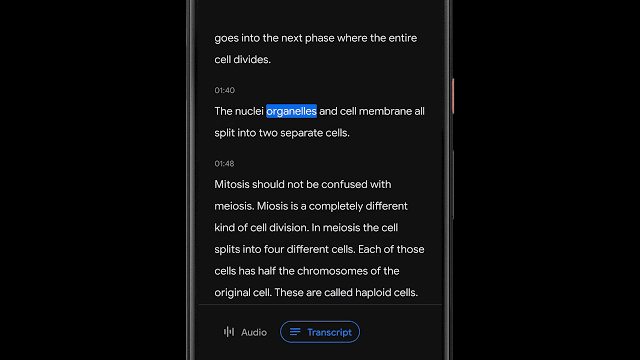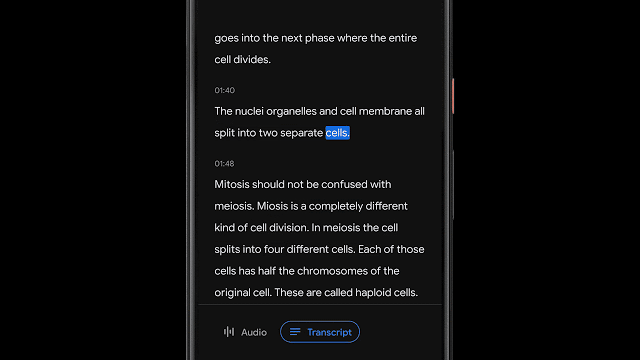
将声音分类
呈现记录是有用的,并且允许人们搜索特定的单词,有时根据特定的时间点或声音在视觉上搜索记录的各个部分更为有用。为了实现这一点,Recorder还将视听音频表示为彩色波形,其中每种颜色与不同的声音类别相关联。这是通过将研究与使用CNN来分类音频声音(例如,识别狗叫声或乐器演奏)和先前发布的数据集进行音频事件检测以对各个音频帧中的明显声音事件进行分类相结合来完成的。
当然,在大多数情况下,许多声音可以同时出现。为了以一种非常清晰的方式可视化音频,我们决定为每个波形条上色,以一种颜色表示代表给定时间段内最主要的声音(在我们的示例中为50ms条)。彩色波形使用户可以了解在特定记录中捕获了哪种类型的内容,并可以更轻松地浏览不断增长的音频库。这为用户带来了录音的可视化表示,并且还使他们能够搜索录音中的音频事件。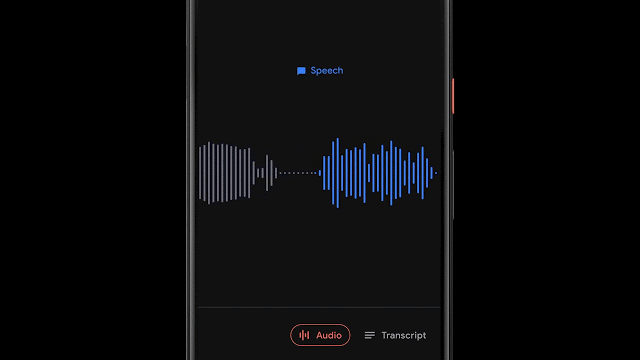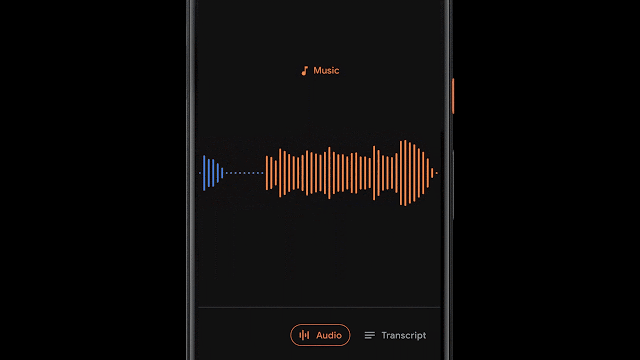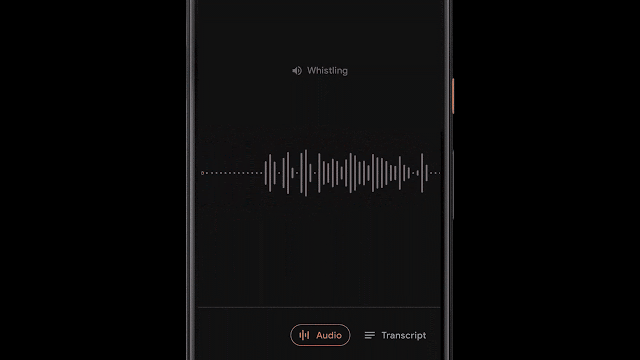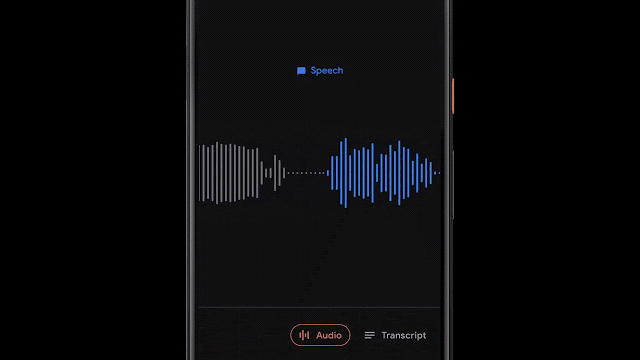
程序还支持滑动窗口功能,该功能以50ms的间隔处理部分重叠的960ms音频帧,并输出一个S型得分矢量,表示该帧中每个受支持的音频类别的概率。为了结合最大的系统精度并报告正确的声音分类,开发者对S形得分应用了线性化处理并结合了阈值处理机制。这种以较小的50ms偏移量分析960ms窗口内容的过程,可以以比单独分析连续的960ms大窗口切片更不容易出错的方式来精确确定开始时间和结束时间。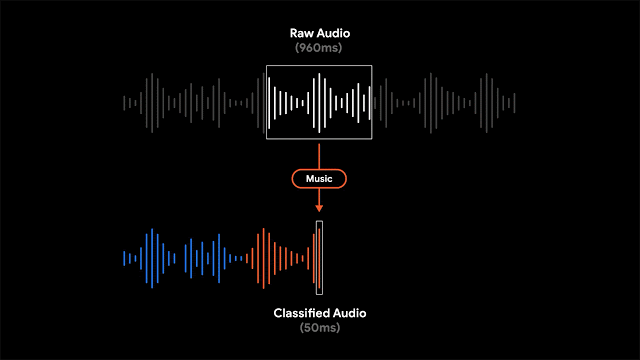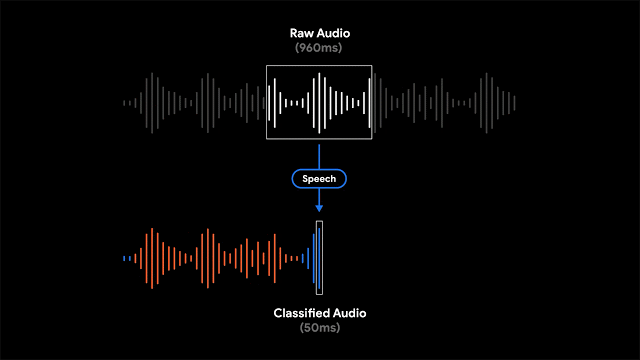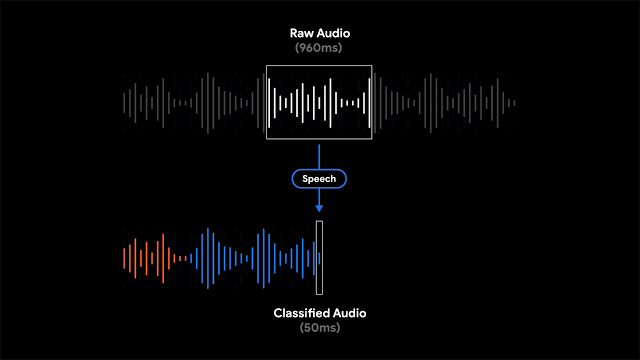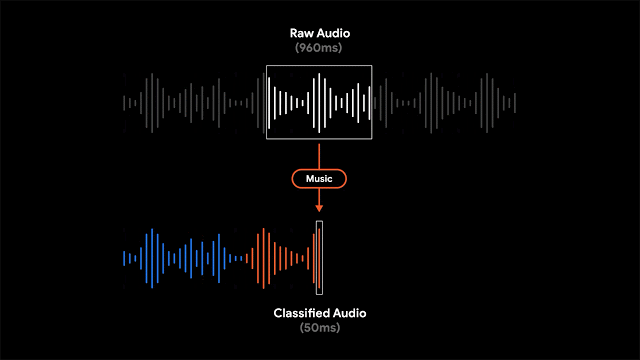
由于该模型独立地分析每个音频帧,因此在音频类别之间可能易于快速抖动。这可以通过将自适应大小的中值滤波技术应用于最新的模型音频类输出来解决,从而提供平滑的连续输出。该过程实时连续运行,要求它满足非常严格的功耗限制。
建立标签
录制完成后,Recorder会建议应用程序认为三个标签来代表最重要的内容,从而使用户能够快速撰写有意义的标题。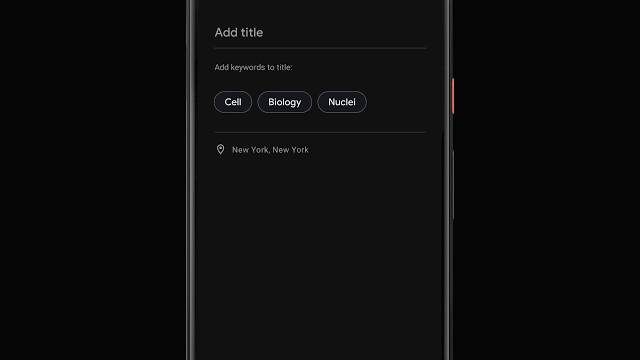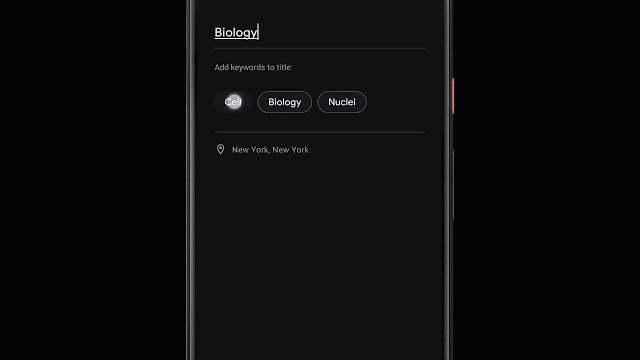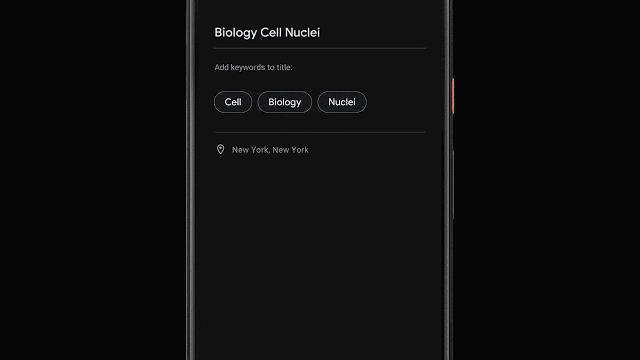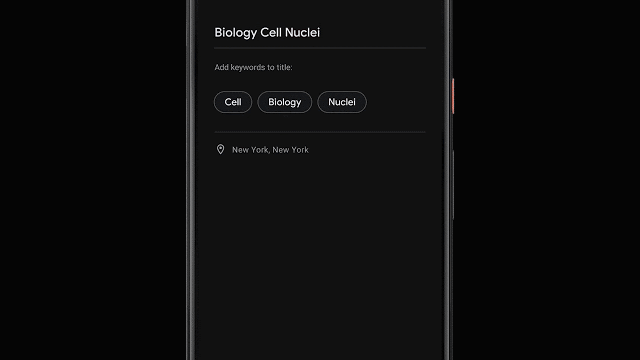
为了能够在录制结束时立即建立这些标签,Recorder在转录录制内容时会对其进行分析。首先,Recorder会计算单词出现的次数及其在句子中的语法作用。标识为实体的术语用大写字母表示。然后,我们使用设备上的词性标注器(一种根据句子的语法作用标记句子中每个单词的模型)来检测用户似乎更容易记住的普通名词和专有名词。记录器使用支持unigram和bigram的先验分数表术语提取。为了生成分数,我们使用会话数据训练了增强型决策树,并利用了文本特征(例如文档词的频率和特异性)。最后,对无意义的词和脏话进行过滤,并输出顶部标签。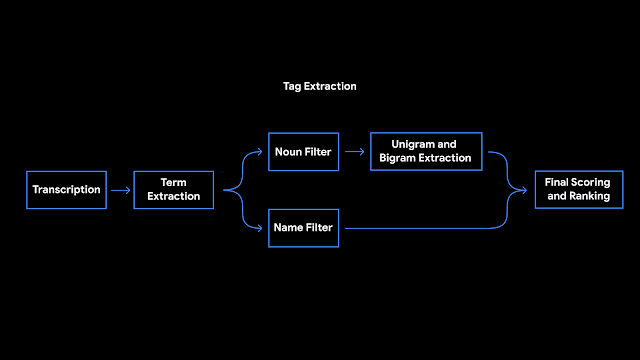 Recorder将我们最近在设备上进行的机器学习研究中的一些工作纳入了有用的功能,并在设备上运行模型以确保用户隐私。机器学习调查和用户需求之间的积极反馈循环揭示了使我们的软件变得更加有用的令人兴奋的机会。我们对未来的研究感到兴奋,它将使每个人的想法和对话更加容易访问和搜索。
Recorder将我们最近在设备上进行的机器学习研究中的一些工作纳入了有用的功能,并在设备上运行模型以确保用户隐私。机器学习调查和用户需求之间的积极反馈循环揭示了使我们的软件变得更加有用的令人兴奋的机会。我们对未来的研究感到兴奋,它将使每个人的想法和对话更加容易访问和搜索。





























