











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






OpenAI-人工反馈的深度学习
2017年08月21日 由 yuxiangyu 发表
776622
0
rl-teacher是“Deep Reinforcement Learning from Human Preferences”的实现。
这个系统允许你教一个强化学习行为的新行为,即:
训练模拟机器人做任何你想做的非常有趣!例如,在MuJoCo“Walker”环境中,agent通常会对向前移动进行奖励,但你可能希望教会它跳芭蕾舞:

想要看我们agent circus的其他技术,你可以使用rl-teacher自己训练一个agent。
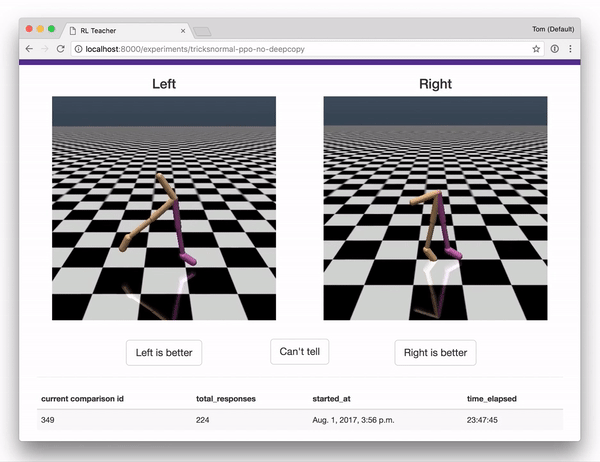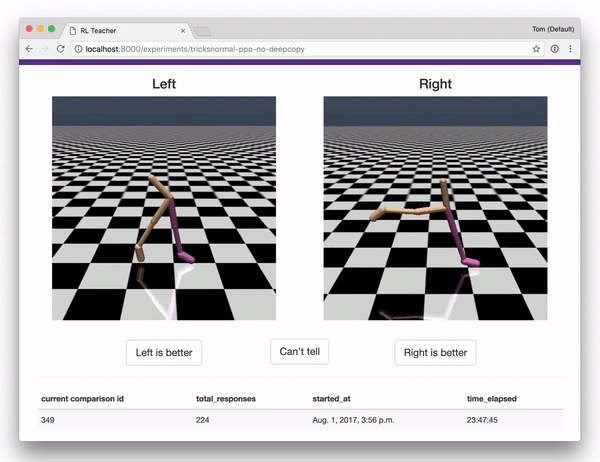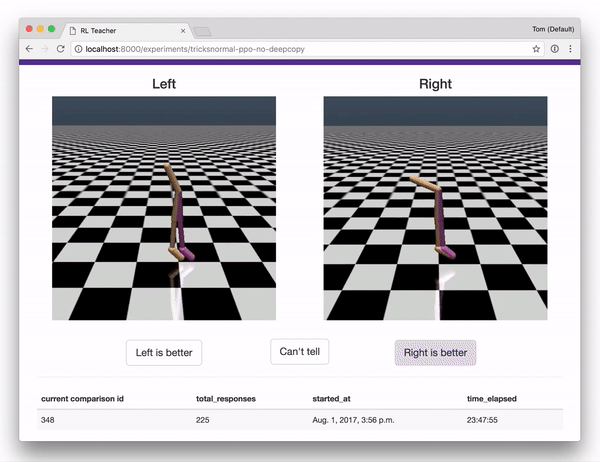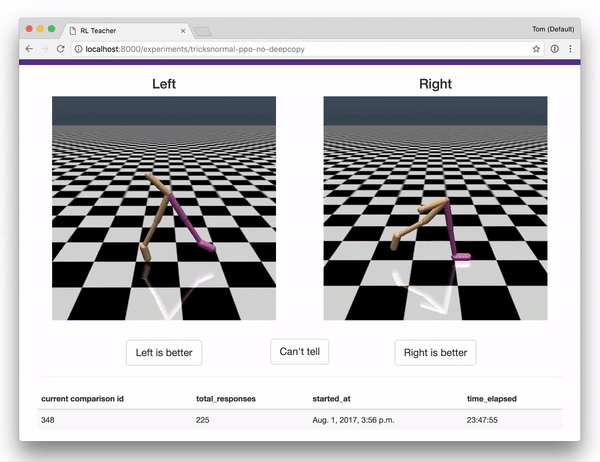
结合OpenAI gym的一组集合,这些组件实现了“ Deep RL from Human Preferences”完整的系统描述。

获取MuJoCo许可证,并在系统上安装二进制文件。为了MuJoCo能够安装良好的文档,以及获得一种测试MuJoCo正在处理系统的简单方法,建议你采用mujoco-py安装。
设置一个使用python 3.5 的conda环境。
复制rl-teacher到你想要的存储库。(例如:~/rl-teacher)。
然后执行以下操作将rl-teacher代码安装到你的环境中:
运行以下命令直接从hard-coded reward函数进行基线强化学习。这完全不需要人为反馈,但这是一个MuJoCo正在工作,RL-agent配置正确,可以自己成功学习的好的测试方法。
默认情况下,这将写入tensorboard文件~/tb/rl-teacher/base-rl。启用tensorboard如下:
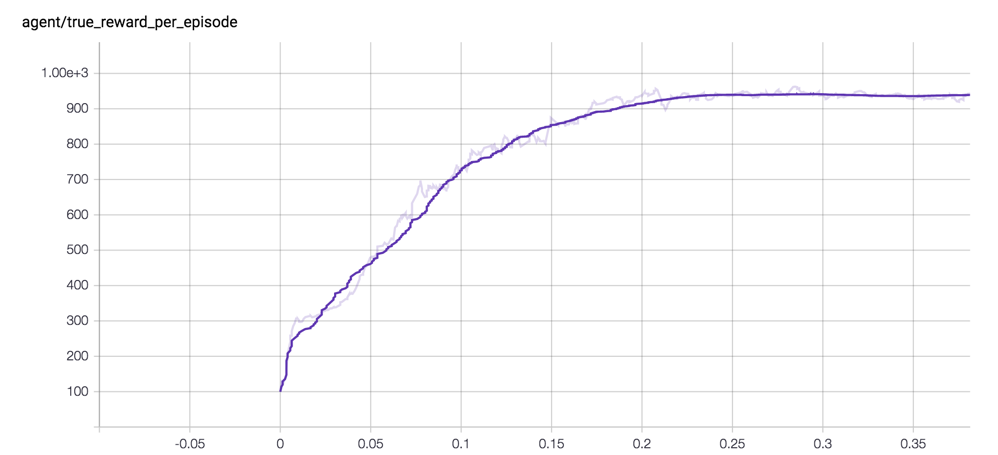
浏览浏览器中的http://0.0.0.0:6006查看你的学习曲线,如下所示:
接下来,我们将使用两部分的培训计划(训练单独的奖励预测,和使用RL进行奖励预测),然而,不同于收集真实的人的反馈,我们将从hard-coded的奖励函数中产生合成反馈环境。这为我们提供了从奖励预测和学习从真正的奖励另一种全面的检查和有用的比较。
我们指定-p synth使用合成预测变量,而不是上面的-p rl。我们将使用相同的环境(-e ShortHopper-v1),给这个运行一个新的名称(-n syn-1400),并请求1400个合计标记(-l 1400)。
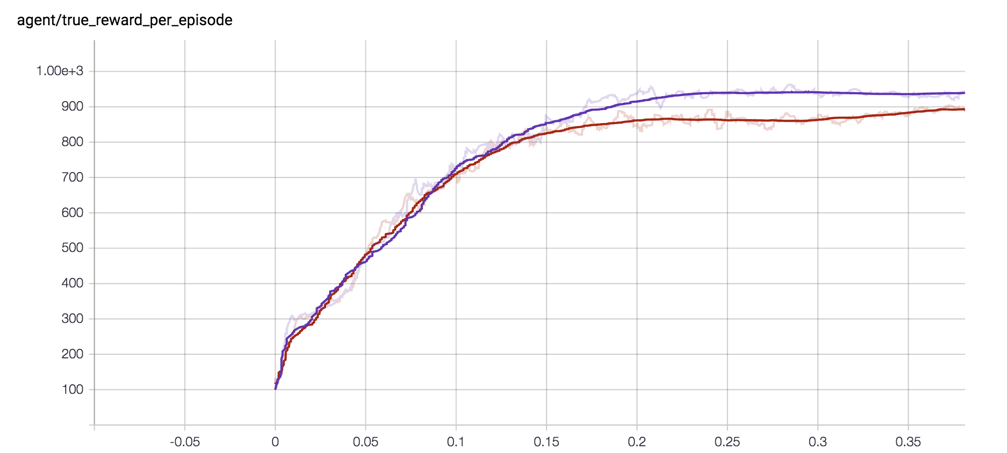
你的tensorboard曲线应如下所示(从棕色合成标记学习):
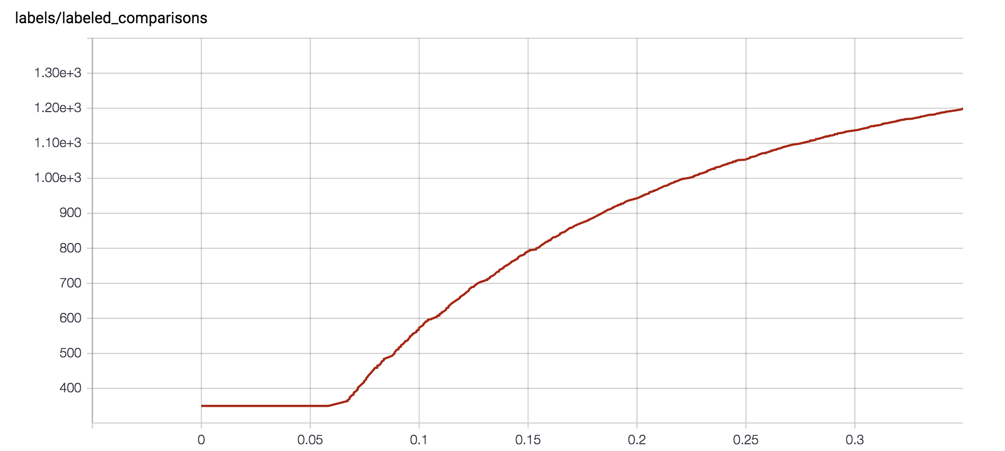
如果你想知道如何计算合成标记可以阅读SyntheticComparisonCollector中的代码。该系统使用指数递减的标记率,切线处理期望的的标记总数:
根据人的反馈来训练agent ,你将运行两个独立的进程:
首先你需要创建django。这将本地目录中创建一个db.sqlite3。
启动网络应用程序
你现在应该能够通过任何浏览器输入网址http://127.0.0.1:8000/来打开网络应用程序。那里什么都没有,但是当你运行你的agent,它将创建一个让你添加标记的实验。
训练过程会生成为你提供反馈的渲染轨迹片段。存储在Google云端存储(GCS)中,因此你需要设置GCS存储库。
如果你尚未设置GCS,请创建一个新的GCS帐户并设置一个新项目。然后,使用以下命令创建一个存储库来托管媒体,并将这个新的存储库设置为publicly-readable(可公开读取)。
现在我们准备用人的反馈训练一个agent。
运行以下命令启动agent的培训。agent开始在环境中采取随机行动,并生成示例轨迹段以供标记:
一旦训练过程生成了它想要你标注的轨迹的视频,就会把这些视频上传到GCS:
同时agent的培训将被暂停,等待你的反馈:
此时,你可以点击活动的实验进入标记界面。点击Active Experiment下的链接
一旦你在标记界面,你会看到很多对片段。指出每一对中哪一个显示更好的行为,无论你试图教agent做什么。(首先,你可以尝试教导助臂夹如何逆时针旋转,或者自己想要的其他任务!)

一旦你完成175项预训练比较的标记,我们就会在最初的比较上训练预测的收敛。之后,它将每隔几秒钟请求进行一次额外比较。
如果你看到空白屏幕,说明这个片段还没有准备好显示。过几分钟刷新一下页面。或点击“Can't tell”尝试别的片段。
你提供的反馈越多,你的agent就能越好地完成任务。
我们建议在具有多个CPU的服务器上运行agent,以便更快地进行培训。
如果你正在远程服务器上运行,则可能需要登录到你的gcloud帐户。
如果你在没有显示的Linux服务器上运行,则应遵循下面的说明。这不仅仅是为了可视化agent的进度 ,而是将各个部分呈现给人标记。
如果你在没有物理显示器的机器上运行,则需要安装XDummy。以下说明已在Ubuntu 14.04 LTS上进行了测试。
安装要求:
安装Xdummy:
开始Xdummy显示:
测试视频渲染工作衔接:
右边是经过培训的agent,根据人的反馈做特技; 在左边是传统的RL训练的。所有视频都是优选出的。猎豹训练使用了PPO,所有其他的agent使用了TRPO。
这个系统允许你教一个强化学习行为的新行为,即:
- 该行为没有预定义的回报函数
- 人类可以确认但不能证明的行为
训练模拟机器人做任何你想做的非常有趣!例如,在MuJoCo“Walker”环境中,agent通常会对向前移动进行奖励,但你可能希望教会它跳芭蕾舞:
想要看我们agent circus的其他技术,你可以使用rl-teacher自己训练一个agent。
这个存储库有什么?
- 一个可以插入任何agent的奖励预测器,并且他可以学习预测人类教师将会批准哪些动作。
- 通过奖励预测器指定的函数学习的几个agent的示例。
- 人可以用来提供反馈的web应用,提供用于训练的奖励预测数据。web应用界面如下。
结合OpenAI gym的一组集合,这些组件实现了“ Deep RL from Human Preferences”完整的系统描述。
安装
获取MuJoCo许可证,并在系统上安装二进制文件。为了MuJoCo能够安装良好的文档,以及获得一种测试MuJoCo正在处理系统的简单方法,建议你采用mujoco-py安装。
设置一个使用python 3.5 的conda环境。
复制rl-teacher到你想要的存储库。(例如:~/rl-teacher)。
然后执行以下操作将rl-teacher代码安装到你的环境中:
cd ~/rl-teacher
pip install -e .
pip install -e human-feedback-api
pip install -e agents/parallel-trpo[tf]
pip install -e agents/pposgd-mpi[tf]
用法
基线RL
运行以下命令直接从hard-coded reward函数进行基线强化学习。这完全不需要人为反馈,但这是一个MuJoCo正在工作,RL-agent配置正确,可以自己成功学习的好的测试方法。
python rl_teacher/teach.py -p rl -e ShortHopper-v1 -n base-rl
默认情况下,这将写入tensorboard文件~/tb/rl-teacher/base-rl。启用tensorboard如下:
$ tensorboard --logdir ~/tb/rl-teacher/ Starting TensorBoard b'47' at http://0.0.0.0:6006 (Press CTRL+C to quit)
浏览浏览器中的http://0.0.0.0:6006查看你的学习曲线,如下所示:
合成标记
接下来,我们将使用两部分的培训计划(训练单独的奖励预测,和使用RL进行奖励预测),然而,不同于收集真实的人的反馈,我们将从hard-coded的奖励函数中产生合成反馈环境。这为我们提供了从奖励预测和学习从真正的奖励另一种全面的检查和有用的比较。
我们指定-p synth使用合成预测变量,而不是上面的-p rl。我们将使用相同的环境(-e ShortHopper-v1),给这个运行一个新的名称(-n syn-1400),并请求1400个合计标记(-l 1400)。
python rl_teacher/teach.py -p synth -l 1400 -e ShortHopper-v1 -n syn-1400
你的tensorboard曲线应如下所示(从棕色合成标记学习):
如果你想知道如何计算合成标记可以阅读SyntheticComparisonCollector中的代码。该系统使用指数递减的标记率,切线处理期望的的标记总数:
人为标记
根据人的反馈来训练agent ,你将运行两个独立的进程:
- agent培训的进程。这与我们上面运行的命令非常相似。
- 一个web应用程序,这将向你展示短视频的剪辑轨迹,并询问你评估哪个剪辑更好。
配置human-feedback-api网络应用程序
首先你需要创建django。这将本地目录中创建一个db.sqlite3。
python human-feedback-api/manage.py migrate
python human-feedback-api/manage.py collectstatic
启动网络应用程序
python human-feedback-api/manage.py runserver 0.0.0.0:8000
你现在应该能够通过任何浏览器输入网址http://127.0.0.1:8000/来打开网络应用程序。那里什么都没有,但是当你运行你的agent,它将创建一个让你添加标记的实验。
创建一个GCS储存库渲染轨迹片段
训练过程会生成为你提供反馈的渲染轨迹片段。存储在Google云端存储(GCS)中,因此你需要设置GCS存储库。
如果你尚未设置GCS,请创建一个新的GCS帐户并设置一个新项目。然后,使用以下命令创建一个存储库来托管媒体,并将这个新的存储库设置为publicly-readable(可公开读取)。
export RL_TEACHER_GCS_BUCKET="gs://rl-teacher-"
gsutil mb $RL_TEACHER_GCS_BUCKET
gsutil defacl ch -u AllUsers:R $RL_TEACHER_GCS_BUCKET
运行你的agent
现在我们准备用人的反馈训练一个agent。
运行以下命令启动agent的培训。agent开始在环境中采取随机行动,并生成示例轨迹段以供标记:
$ python rl_teacher/teach.py -p human --pretrain_labels 175 -e Reacher-v1 -n human-175
Using TensorFlow backend.
No label limit given. We will request one label every few seconds
Starting random rollouts to generate pretraining segments. No learning will take place...
-------- Iteration 1 ----------
Average sum of true rewards per episode: -10.5385
Entropy: 2.8379
KL(old|new): 0.0000
Surrogate loss: 0.0000
Frames gathered: 392
Frames gathered/second: 213857
Time spent gathering rollouts: 0.00
Time spent updating weights: 0.32
Total time: 0.33
Collected 10/875 segments
Collected 20/875 segments
Collected 30/875 segments
...
一旦训练过程生成了它想要你标注的轨迹的视频,就会把这些视频上传到GCS:
... Copying media to gs://rl-teacher-catherio/d659f8b4-c701-4eab-8358-9bd532a1661b-right.mp4 in a background process Copying media to gs://rl-teacher-catherio/9ce75215-66e7-439d-98c9-39e636ebb8a4-left.mp4 in a background process ...
同时agent的培训将被暂停,等待你的反馈:
0/175 comparisons labeled. Please add labels w/ the human-feedback-api. Sleeping...
向agent提供反馈
此时,你可以点击活动的实验进入标记界面。点击Active Experiment下的链接
一旦你在标记界面,你会看到很多对片段。指出每一对中哪一个显示更好的行为,无论你试图教agent做什么。(首先,你可以尝试教导助臂夹如何逆时针旋转,或者自己想要的其他任务!)
一旦你完成175项预训练比较的标记,我们就会在最初的比较上训练预测的收敛。之后,它将每隔几秒钟请求进行一次额外比较。
如果你看到空白屏幕,说明这个片段还没有准备好显示。过几分钟刷新一下页面。或点击“Can't tell”尝试别的片段。
你提供的反馈越多,你的agent就能越好地完成任务。
使用远程服务器进行agent培训
我们建议在具有多个CPU的服务器上运行agent,以便更快地进行培训。
如果你正在远程服务器上运行,则可能需要登录到你的gcloud帐户。
如果你在没有显示的Linux服务器上运行,则应遵循下面的说明。这不仅仅是为了可视化agent的进度 ,而是将各个部分呈现给人标记。
在Xorg或XDummy的linux上去头视频的表现
如果你在没有物理显示器的机器上运行,则需要安装XDummy。以下说明已在Ubuntu 14.04 LTS上进行了测试。
安装要求:
sudo apt-get update && sudo apt-get install -y \
ffmpeg \
libav-tools \
libpq-dev \
libjpeg-dev \
cmake \
swig \
python-opengl \
libboost-all-dev \
libsdl2-dev \
xpra
安装Xdummy:
curl -o /usr/bin/Xdummy https://gist.githubusercontent.com/nottombrown/ffa457f020f1c53a0105ce13e8c37303/raw/ff2bc2dcf1a69af141accd7b337434f074205b23/Xdummy
chmod +x /usr/bin/Xdummy
开始Xdummy显示:
Xdummy
测试视频渲染工作衔接:
DISPLAY=:0 python rl_teacher/tests/video_render_test.py
agent马戏团
右边是经过培训的agent,根据人的反馈做特技; 在左边是传统的RL训练的。所有视频都是优选出的。猎豹训练使用了PPO,所有其他的agent使用了TRPO。
| 正常走路 | 芭蕾舞 |
|---|---|
 | |
| 正常的助臂夹 | 不正常的助臂夹 |
|---|---|
 |  |
| 正常的单腿跳 | 后空翻式单腿跳 |
|---|---|
 |  |
| 正常的猎豹 | 跳踢踏舞的猎豹 |
|---|---|
 |  |

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消