











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






用深度学习预测Phish乐队接下来唱什么歌(上)
2019年11月30日 由 sunlei 发表
607962
0
[caption id="attachment_47383" align="aligncenter" width="2236"] Phish, Hampton 2018[/caption]
Phish, Hampton 2018[/caption]
Phish -一个标志性的现场摇滚乐队,和机器学习的世界…他们可能有什么共同之处?
与绝大多数音乐艺术家的现场表演不同,对Phish来说,大多数活动都是没有计划的。从乐队踏上舞台的那一刻起,没有预先确定的节目单、歌曲选择或演出时长。每一场演出,乐队和观众都开始了一段全新的旅程,充满了集体的能量和高超的即兴表演的能力。
我和我的朋友多年来一直在看Phish的演出,就像社区里的许多Phans一样,我们经常在每次演出前玩一个游戏,看看谁能猜出Phish的876首歌曲中哪首会在某个晚上演出。我们的游戏版本包括:每个人猜测节目的开场,在节目中播放三首歌曲,再唱一首歌曲。考虑到你(在技术上)有大约0.11%的成功几率,如果你的预测中有一个是正确的,那么这通常是一个非常美好的夜晚。
在业界做了几年的数据科学家之后,我开始发现Phish的歌曲选择中隐藏的统计模式,并建立一个模型来预测接下来的歌曲。
我决定以类似于神经语言模型的方式,把这个问题框定为一个连续的多类分类任务——即:
“我能准确地预测接下来演出的歌曲是什么吗?”
在本文的以下部分中,我将详细介绍我的数据收集/准备过程、建模练习、结果和改进计划—让我们开始深入了解细节。
对我来说幸运的是,在Phish.net上有一个很棒的团队,他们积极维护和更新一个全面的数据库和公共API,用于所有Phish相关的事情,包括:演出、设置列表、场地、歌曲等等。在编写了Python API包装器(与Mike Arango合作)之后,我能够检索所有1752个Phish显示的历史数据,这些数据可以追溯到1983年。
[caption id="attachment_47384" align="aligncenter" width="1898"]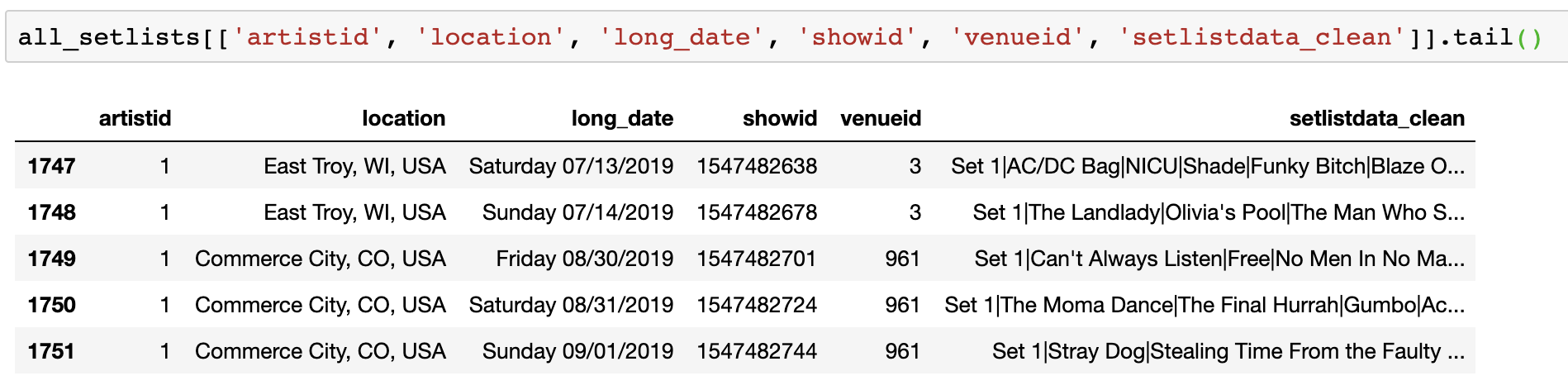 来自Phish.net API的最新5个示例,使用解析的setlist数据和分隔的管道[/caption]
来自Phish.net API的最新5个示例,使用解析的setlist数据和分隔的管道[/caption]
创建训练数据集
有了语言建模方法,我通过首先删除不完整的setlist,然后按时间顺序将每个setlist连接到一个长列表中,并将876首唯一歌曲中的每首歌的数据编码为整数,再加上所有setlist标识符来生成训练数据。在序列中维护setlist标识符(Set 1, Set 2, Encore,等等)提供了上下文,并将允许模型了解某些歌曲更有可能出现在第二个Set的开头与中间与Encore之间。
接下来,我创建了训练样本对——即序列(Y)中与下一首歌曲配对的歌曲列表(X)。我将单个连接列表切片为N个长度为L的样本,其中L成为用于建模的超参数。这个模型需要多长时间才能准确预测下一首歌曲?我测试了长度为25、50、100、150和250的序列,稍后将进行更多的测试。然后我在大约37000个样本上创建了一个80/20的训练/验证分离来评估我的模型。
[caption id="attachment_47385" align="aligncenter" width="766"] 一个样本训练对的示例[/caption]
一个样本训练对的示例[/caption]
虽然有许多机器学习模型可以应用到这个场景中,但我选择了实现一个深度学习方法,因为它在我的隐喻性语言建模任务中保持了最先进的性能。具体地说,我选择测试了具有嵌入层和LSTM(长短时记忆)细胞的顺序RNN(递归神经网络)的几种不同配置。RNN的周期性使得信息可以跨时间步长共享,使得学习到的知识可以作为“记忆”在网络中保持。因此,这种体系结构非常适合学习我们的setlist建模问题的顺序性质。我的模型的其他组件包括:
歌曲嵌入层-类似于NLP世界中的单词嵌入…我选择为876个类中的每一个嵌入一个N维向量,希望该模型能够了解每首歌曲的潜在因素,以提供更丰富的特征集,用于以后的预测层。此处的嵌入大小成为另一个可探索的超参数。稍后将对此进行更多分析。
LSTM细胞——典型的RNN非常擅长学习和联想短期依赖关系。如果我们的输入序列只有一个setlist(大约10-20首歌曲),这是可以的,但是因为我们需要监视和跟踪许多节目的长期依赖关系,所以我们的输入序列长度在50-250首歌曲之间。LSTM单元引入了一个称为“cell state”的学习参数,该参数为网络提供了一个选项,可以选择“记住”或“忘记”重要或不重要的长期依赖关系。
退出-在[相对]小数据集上应用神经网络的一个常见问题是过度拟合的诅咒。我在这里提出的深度学习架构有>300,000个学习参数,这意味着模型很容易从它看到的训练数据“学习太多”,而不能很好地泛化到新数据。为了防止这种情况发生,我实施了dropout正则化,即在训练过程中随机“关闭”某些神经元的激活。这种故意阻碍模型学习的方法对于防止过拟合非常有效。
学习速率查找器——选择最优的学习速率对于神经网络的及时有效训练至关重要。学习速率过高,模型就会偏离;太低,你的模型将永远训练,损失几乎没有改善。我整合了这个了不起的LR Finder Keras回调函数,它为几个小批量运行绘制了学习速率与丢失的关系图,以帮助您可视化最佳学习速率。我还添加了一个平滑特性,它采用指数移动平均来帮助清理视觉上的障碍,以便于理解。最佳学习率对应于损失的最大降幅——如下图绿色所示。
[caption id="attachment_47386" align="aligncenter" width="1170"]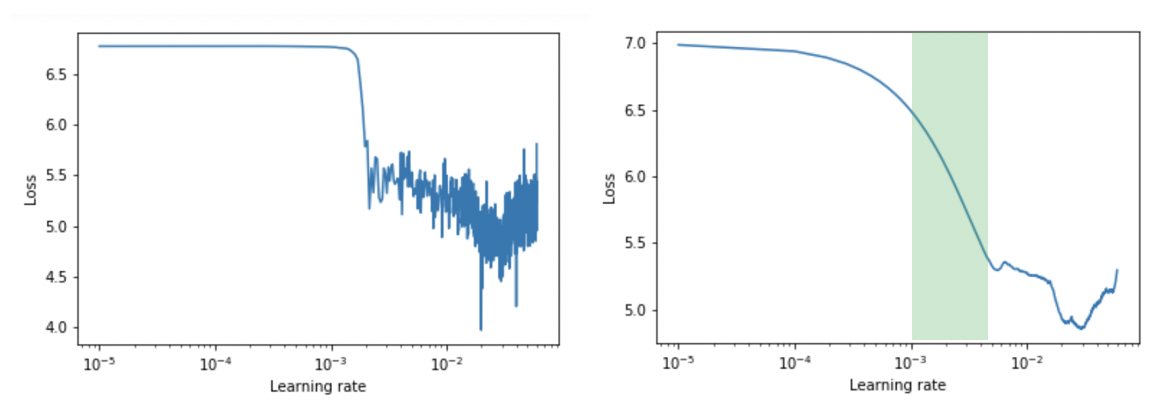 带有平滑图的学习速率查找器示例(右)[/caption]
带有平滑图的学习速率查找器示例(右)[/caption]
Adam Optimizer -Adam通过结合每个参数的学习速率(来自AdaGrad)和动量(来自RMSProp)的概念改进了基本随机梯度下降(SGD)。简而言之,这种增强的优化器使您的模型能够更快地学习,并且已经成为该领域的“入门”技术。
对于这些模型和优化器组件,以下是用于实验的两种体系结构变体:
模型结构1:
[caption id="attachment_47387" align="aligncenter" width="945"]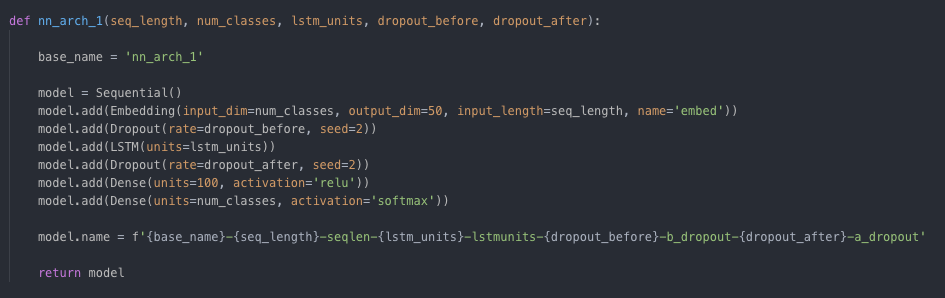 具有嵌入层,Dropout层,LSTM层,Dropout层,和一个密集层的序列模型[/caption]
具有嵌入层,Dropout层,LSTM层,Dropout层,和一个密集层的序列模型[/caption]
模型结构2:
[caption id="attachment_47388" align="aligncenter" width="937"]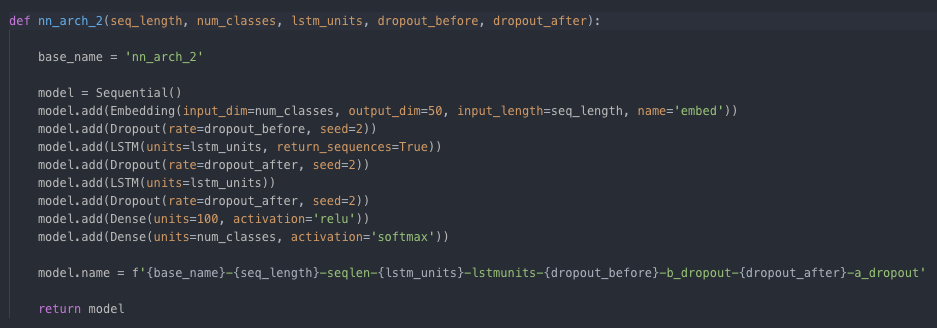 与上述模型相同,但两个堆叠的LSTM层用于附加学习参数[/caption]
与上述模型相同,但两个堆叠的LSTM层用于附加学习参数[/caption]
今天先学到这里,明天我们来进行一个小实验。
原文链接:https://towardsdatascience.com/predicting-what-song-phish-will-play-next-with-deep-learning-947ccce3824d
Phish, Hampton 2018[/caption]Phish -一个标志性的现场摇滚乐队,和机器学习的世界…他们可能有什么共同之处?
与绝大多数音乐艺术家的现场表演不同,对Phish来说,大多数活动都是没有计划的。从乐队踏上舞台的那一刻起,没有预先确定的节目单、歌曲选择或演出时长。每一场演出,乐队和观众都开始了一段全新的旅程,充满了集体的能量和高超的即兴表演的能力。
我和我的朋友多年来一直在看Phish的演出,就像社区里的许多Phans一样,我们经常在每次演出前玩一个游戏,看看谁能猜出Phish的876首歌曲中哪首会在某个晚上演出。我们的游戏版本包括:每个人猜测节目的开场,在节目中播放三首歌曲,再唱一首歌曲。考虑到你(在技术上)有大约0.11%的成功几率,如果你的预测中有一个是正确的,那么这通常是一个非常美好的夜晚。
在业界做了几年的数据科学家之后,我开始发现Phish的歌曲选择中隐藏的统计模式,并建立一个模型来预测接下来的歌曲。
方法
我决定以类似于神经语言模型的方式,把这个问题框定为一个连续的多类分类任务——即:
“我能准确地预测接下来演出的歌曲是什么吗?”
在本文的以下部分中,我将详细介绍我的数据收集/准备过程、建模练习、结果和改进计划—让我们开始深入了解细节。
数据
对我来说幸运的是,在Phish.net上有一个很棒的团队,他们积极维护和更新一个全面的数据库和公共API,用于所有Phish相关的事情,包括:演出、设置列表、场地、歌曲等等。在编写了Python API包装器(与Mike Arango合作)之后,我能够检索所有1752个Phish显示的历史数据,这些数据可以追溯到1983年。
[caption id="attachment_47384" align="aligncenter" width="1898"]
来自Phish.net API的最新5个示例,使用解析的setlist数据和分隔的管道[/caption]创建训练数据集
有了语言建模方法,我通过首先删除不完整的setlist,然后按时间顺序将每个setlist连接到一个长列表中,并将876首唯一歌曲中的每首歌的数据编码为整数,再加上所有setlist标识符来生成训练数据。在序列中维护setlist标识符(Set 1, Set 2, Encore,等等)提供了上下文,并将允许模型了解某些歌曲更有可能出现在第二个Set的开头与中间与Encore之间。
接下来,我创建了训练样本对——即序列(Y)中与下一首歌曲配对的歌曲列表(X)。我将单个连接列表切片为N个长度为L的样本,其中L成为用于建模的超参数。这个模型需要多长时间才能准确预测下一首歌曲?我测试了长度为25、50、100、150和250的序列,稍后将进行更多的测试。然后我在大约37000个样本上创建了一个80/20的训练/验证分离来评估我的模型。
[caption id="attachment_47385" align="aligncenter" width="766"]
一个样本训练对的示例[/caption]建模
虽然有许多机器学习模型可以应用到这个场景中,但我选择了实现一个深度学习方法,因为它在我的隐喻性语言建模任务中保持了最先进的性能。具体地说,我选择测试了具有嵌入层和LSTM(长短时记忆)细胞的顺序RNN(递归神经网络)的几种不同配置。RNN的周期性使得信息可以跨时间步长共享,使得学习到的知识可以作为“记忆”在网络中保持。因此,这种体系结构非常适合学习我们的setlist建模问题的顺序性质。我的模型的其他组件包括:
歌曲嵌入层-类似于NLP世界中的单词嵌入…我选择为876个类中的每一个嵌入一个N维向量,希望该模型能够了解每首歌曲的潜在因素,以提供更丰富的特征集,用于以后的预测层。此处的嵌入大小成为另一个可探索的超参数。稍后将对此进行更多分析。
LSTM细胞——典型的RNN非常擅长学习和联想短期依赖关系。如果我们的输入序列只有一个setlist(大约10-20首歌曲),这是可以的,但是因为我们需要监视和跟踪许多节目的长期依赖关系,所以我们的输入序列长度在50-250首歌曲之间。LSTM单元引入了一个称为“cell state”的学习参数,该参数为网络提供了一个选项,可以选择“记住”或“忘记”重要或不重要的长期依赖关系。
退出-在[相对]小数据集上应用神经网络的一个常见问题是过度拟合的诅咒。我在这里提出的深度学习架构有>300,000个学习参数,这意味着模型很容易从它看到的训练数据“学习太多”,而不能很好地泛化到新数据。为了防止这种情况发生,我实施了dropout正则化,即在训练过程中随机“关闭”某些神经元的激活。这种故意阻碍模型学习的方法对于防止过拟合非常有效。
学习速率查找器——选择最优的学习速率对于神经网络的及时有效训练至关重要。学习速率过高,模型就会偏离;太低,你的模型将永远训练,损失几乎没有改善。我整合了这个了不起的LR Finder Keras回调函数,它为几个小批量运行绘制了学习速率与丢失的关系图,以帮助您可视化最佳学习速率。我还添加了一个平滑特性,它采用指数移动平均来帮助清理视觉上的障碍,以便于理解。最佳学习率对应于损失的最大降幅——如下图绿色所示。
[caption id="attachment_47386" align="aligncenter" width="1170"]
带有平滑图的学习速率查找器示例(右)[/caption]Adam Optimizer -Adam通过结合每个参数的学习速率(来自AdaGrad)和动量(来自RMSProp)的概念改进了基本随机梯度下降(SGD)。简而言之,这种增强的优化器使您的模型能够更快地学习,并且已经成为该领域的“入门”技术。
对于这些模型和优化器组件,以下是用于实验的两种体系结构变体:
模型结构1:
[caption id="attachment_47387" align="aligncenter" width="945"]
具有嵌入层,Dropout层,LSTM层,Dropout层,和一个密集层的序列模型[/caption]模型结构2:
[caption id="attachment_47388" align="aligncenter" width="937"]
与上述模型相同,但两个堆叠的LSTM层用于附加学习参数[/caption]今天先学到这里,明天我们来进行一个小实验。
原文链接:https://towardsdatascience.com/predicting-what-song-phish-will-play-next-with-deep-learning-947ccce3824d

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消