












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






用 Swifter 大幅提高 Pandas 性能
2019年11月17日 由 sunlei 发表
679972
0
假如在此刻,您已经将数据全部加载到panda的数据框架中,准备好进行一些探索性分析,但首先,您需要创建一些附加功能。自然地,您将转向apply函数。Apply很好,因为它使在数据的所有行上使用函数变得很容易,你设置好一切,运行你的代码,然后…
事实证明,处理大型数据集的每一行可能需要一段时间。值得庆幸的是,有一个非常简单的解决方案可以为您节省大量时间。
Swifter是一个库,它“以最快的可用方式将任何函数应用到pandas数据帧或序列中”,以了解我们首先需要讨论的几个原则。
对于这个用例,我们将把矢量化定义为使用Numpy来表示整个数组而不是它们的元素上的计算。
例如,假设有两个数组:
你希望创建一个新的数组,这是两个数组的总和,结果如下:
在Python中,可以用for循环来对这些数组求和,但是这样做非常慢。相反,Numpy允许您直接对数组进行操作,这要快得多(特别是对于大型数组)
关键是尽可能使用向量化操作。
几乎所有的计算机都有多个处理器。这意味着您可以很容易地通过利用它们来提高代码的速度。因为apply只是将一个函数应用到数据帧的每一行,所以并行化很简单。您可以将数据帧分割成多个块,将每个块提供给它的处理器,然后在最后将这些块合并回单个数据帧。
[caption id="attachment_46938" align="aligncenter" width="388"]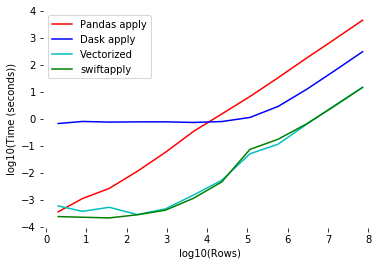 来源https://github.com/jmcarpenter2/swifter[/caption]
来源https://github.com/jmcarpenter2/swifter[/caption]
1、检查你的函数是否可以向量化,如果可以,就使用向量化计算。
2、如果无法进行矢量化,请检查使用Dask进行并行处理还是只使用vanilla pandas apply(仅使用单个核)最有意义。并行处理的开销会使小数据集的处理速度变慢。
这一切都很好地显示在上图中。可以看到,无论数据大小如何,使用向量化总是更好的。如果这是不可能的,你可以从vanilla panda那里得到最好的速度,直到你的数据足够大。一旦超过大小阈值,并行处理就最有意义。
您可以看到“SwiftApply”行是Swifter会做的,它会自动为您选择最佳选项。
也许你会问,你是如何利用这个魔法的?其实这是一件容易的事。
如上图所示,只要在应用之前添加一个快速调用,你就可以用一个单词来运行你的Pandas应用程序了。
现在,你可以花更少的时间盯着进度条,更多的时间做科学这改变了生活。不过,你可能没那么多时间玩游戏。

GitHub: https://github.com/jmcarpenter2/swifter
原文链接:https://towardsdatascience.com/one-word-of-code-to-stop-using-pandas-so-slowly-793e0a81343c
等待……
事实证明,处理大型数据集的每一行可能需要一段时间。值得庆幸的是,有一个非常简单的解决方案可以为您节省大量时间。
Swifter
Swifter是一个库,它“以最快的可用方式将任何函数应用到pandas数据帧或序列中”,以了解我们首先需要讨论的几个原则。
矢量化
对于这个用例,我们将把矢量化定义为使用Numpy来表示整个数组而不是它们的元素上的计算。
例如,假设有两个数组:
array_1 = np.array([1,2,3,4,5])
array_2 = np.array([6,7,8,9,10])
你希望创建一个新的数组,这是两个数组的总和,结果如下:
result = [7,9,11,13,15]
在Python中,可以用for循环来对这些数组求和,但是这样做非常慢。相反,Numpy允许您直接对数组进行操作,这要快得多(特别是对于大型数组)
result = array_1 + array_2
关键是尽可能使用向量化操作。
并行处理
几乎所有的计算机都有多个处理器。这意味着您可以很容易地通过利用它们来提高代码的速度。因为apply只是将一个函数应用到数据帧的每一行,所以并行化很简单。您可以将数据帧分割成多个块,将每个块提供给它的处理器,然后在最后将这些块合并回单个数据帧。
The Magic
[caption id="attachment_46938" align="aligncenter" width="388"]
来源https://github.com/jmcarpenter2/swifter[/caption]Swifter的做法是
1、检查你的函数是否可以向量化,如果可以,就使用向量化计算。
2、如果无法进行矢量化,请检查使用Dask进行并行处理还是只使用vanilla pandas apply(仅使用单个核)最有意义。并行处理的开销会使小数据集的处理速度变慢。
这一切都很好地显示在上图中。可以看到,无论数据大小如何,使用向量化总是更好的。如果这是不可能的,你可以从vanilla panda那里得到最好的速度,直到你的数据足够大。一旦超过大小阈值,并行处理就最有意义。
您可以看到“SwiftApply”行是Swifter会做的,它会自动为您选择最佳选项。
也许你会问,你是如何利用这个魔法的?其实这是一件容易的事。
import pandas as pd
import swifter
df.swifter.apply(lambda x: x.sum() - x.min())
如上图所示,只要在应用之前添加一个快速调用,你就可以用一个单词来运行你的Pandas应用程序了。
现在,你可以花更少的时间盯着进度条,更多的时间做科学这改变了生活。不过,你可能没那么多时间玩游戏。
GitHub: https://github.com/jmcarpenter2/swifter
原文链接:https://towardsdatascience.com/one-word-of-code-to-stop-using-pandas-so-slowly-793e0a81343c

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消