












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






用Google Sheets搭建深度网络
2019年11月16日 由 sunlei 发表
716839
0
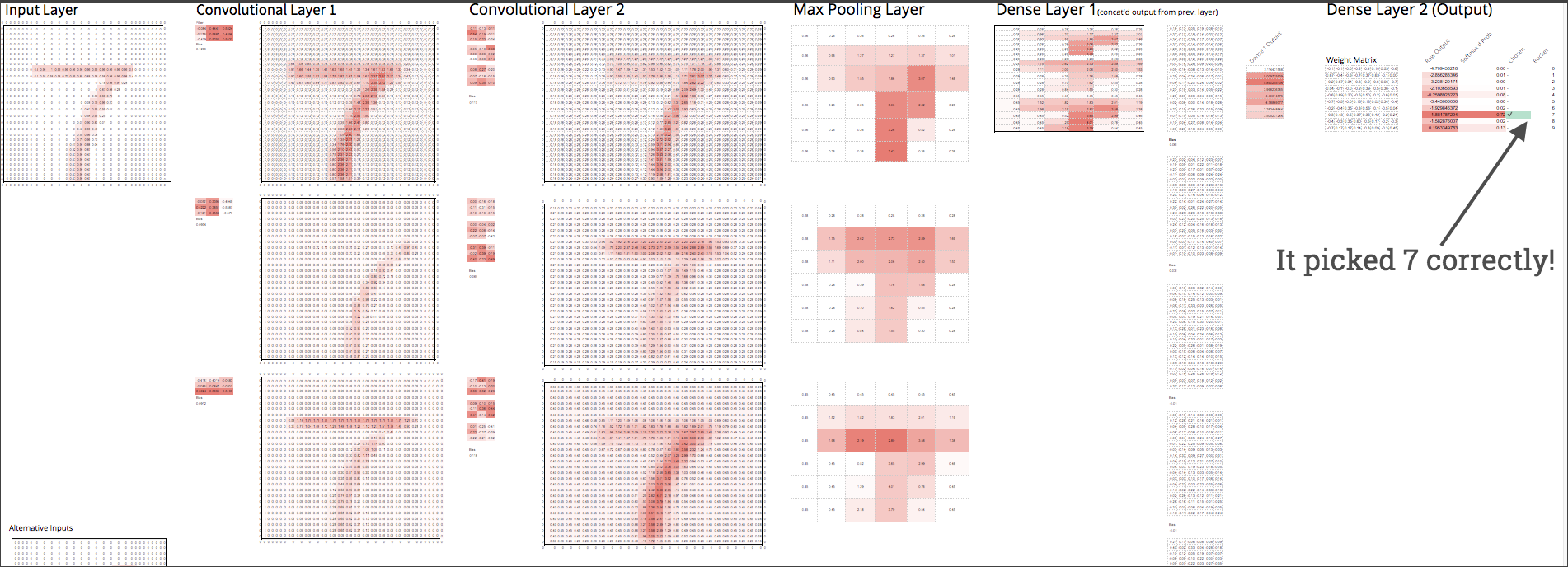
我想告诉你们,卷积神经网络并不像听起来那么可怕。我将通过展示我在google sheets中制作的一个实现来证明它。这里有一些可用的内容。复制它(使用左上角的file→make a copy选项),然后你可以尝试一下,看看不同的控制杆是如何影响模型的预测的。
本文的其余部分将是一个简短的介绍,以理解卷积神经网络(CNN)背后的高级直觉,然后是一些推荐的资源,以提供进一步的信息。
在继续之前,我想对FastAI大喊一声我最近完成了他们精彩的深度学习课程,所有的灵感和功劳都真正属于他们。优秀的讲师杰里米·霍华德和他的联合创始人雷切尔·托马斯向学生们展示了用Excel制作CNN的想法。但据我所知,电子表格无法在线使用,而且似乎也没有完全完成网络。我正在对他们的工作做一个小的扩展,并把它放在google sheets上,这样每个人都更容易使用。
我是怎么建造它的?
我在MNIST数据集上训练了一个(非常)简单的CNN,它是一堆手写数字的黑白图像。每张图片的分辨率为28x28像素。每个像素都表示为0(无墨水)到1(最大墨水)之间的数字。这是一个经典的数据集,因为它足够小,速度快,但真实到足以显示机器学习的复杂性。模型的任务是确定图像的编号。每个图像都是0-9中的一个数字。
[caption id="attachment_46898" align="aligncenter" width="283"]
 来自MNIST的示例图像。28x28像素。注意:我在工作表中添加了条件格式,这样“墨水”越多的像素显示越红。[/caption]
来自MNIST的示例图像。28x28像素。注意:我在工作表中添加了条件格式,这样“墨水”越多的像素显示越红。[/caption]我用一个叫做Keras的流行深度学习库来训练模型(见这里的代码),然后把从模型中训练出来的权重放在表格里。训练过的权重只是数字。把它放在纸上,这意味着从我的模型复制并粘贴一堆数字到纸上。最后一步是添加公式来复制模型的功能,这只是常规的乘法和加法。让我重申一下:复制深度学习模型预测的数学止于乘法和加法[1]。
模型的每一层都有权重(也就是“参数”)。权重由任何机器学习模型自动学习。这个模型大约有1000个权重。更复杂的模型很容易拥有数亿个您可以在下面看到该模型的所有1000个权重:
何时使用卷积神经网络?
你使用CNN来发现序列数据中的模式,你非常肯定这些模式的存在,但是你发现很难把这些模式用文字表达出来,或者通过简单的规则来提取它们。CNN假定的顺序很重要。
例如,对图片进行分类是CNN的一个主要用例,因为这些像素在逻辑上是连续的,而且任何人都清楚有大量的模式。然而,只要试着用语言准确地说出猫和吉娃娃的区别,你就会明白为什么CNN是有用的。
另一方面,如果你有两支棒球队之间的最新数据,并且你想预测胜利者,那么CNN将是一个奇怪的选择。你所掌握的数据(如胜负数或球队击球平均数)并非天生的连续性。这里的顺序无关紧要,我们已经提取了我们认为有用的模式。所以CNN不会有帮助的。
CNN背后的直觉
为了理解这些怪兽,让我们把Deep Convolutional Neural Net分解成“深”、“卷积”和“神经网络”的组成部分。
卷积
想象一下你是盲人。但你的工作是找出这张手写图像的数字。你可以和看到图像的人交谈,但他们不知道数字是什么。所以你只能问他们简单的问题。你会怎么做?
你可以采取的一种方法是问这样的事情,“它主要是直接在顶部吗?”、“从右向左对角线?””等。有足够多的这样的问题,你可以很好地猜出它是7,或者2,或者别的什么。
直观地说,这就是卷积的作用。计算机是盲目的,所以它会做它能做的,并问很多小的模式问题。
[caption id="attachment_46901" align="aligncenter" width="901"]
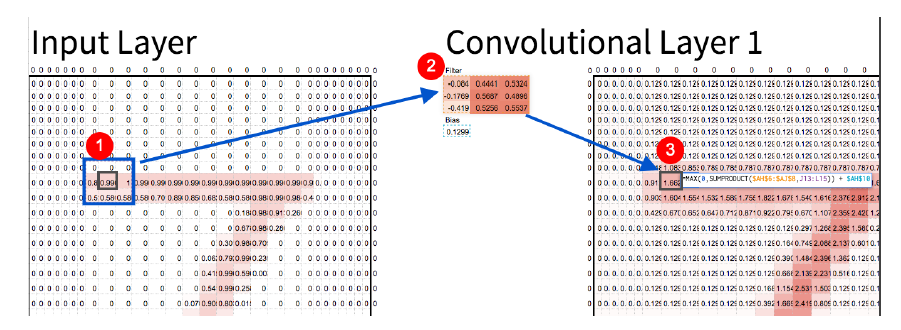 方框1乘以方框2。把结果加起来,就得到第3框。这是个复杂的问题。[/caption]
方框1乘以方框2。把结果加起来,就得到第3框。这是个复杂的问题。[/caption]为了提出这些问题,图像中的每个像素都要经过一个函数(也就是“卷积”)来产生相应的像素,这个函数回答了其中一个小模式问题卷积使用滤波器来寻找模式。例如,请注意上面的过滤器(屏幕截图中的第2个)在右边是红色的,而在左边是红色的。这个过滤器基本上会寻找左边缘。
它为什么会找到左边缘可能不是很明显,但是试着使用电子表格,你就会看到数学是如何计算出来的。过滤器会找到看起来像它们自己的东西。CNN通常会使用数百个过滤器,所以你会为每个像素获得许多小的“分数”,有点像左边缘分数、上边缘分数、对角线分数、角分数等等。
深
好吧,所以询问边缘是很酷的,但是更复杂的形状呢?“这就是“深层”的多重层次的东西。因为现在我们有了图像的“左边缘”、“上边缘”和其他简单的“过滤器”,我们可以添加另一层,并对之前的所有过滤器运行卷积,然后合并它们!因此,将50/50 A的左边缘和上边缘组合起来,可以得到一个圆角的左角。很酷吧?
[caption id="attachment_46902" align="aligncenter" width="848"]
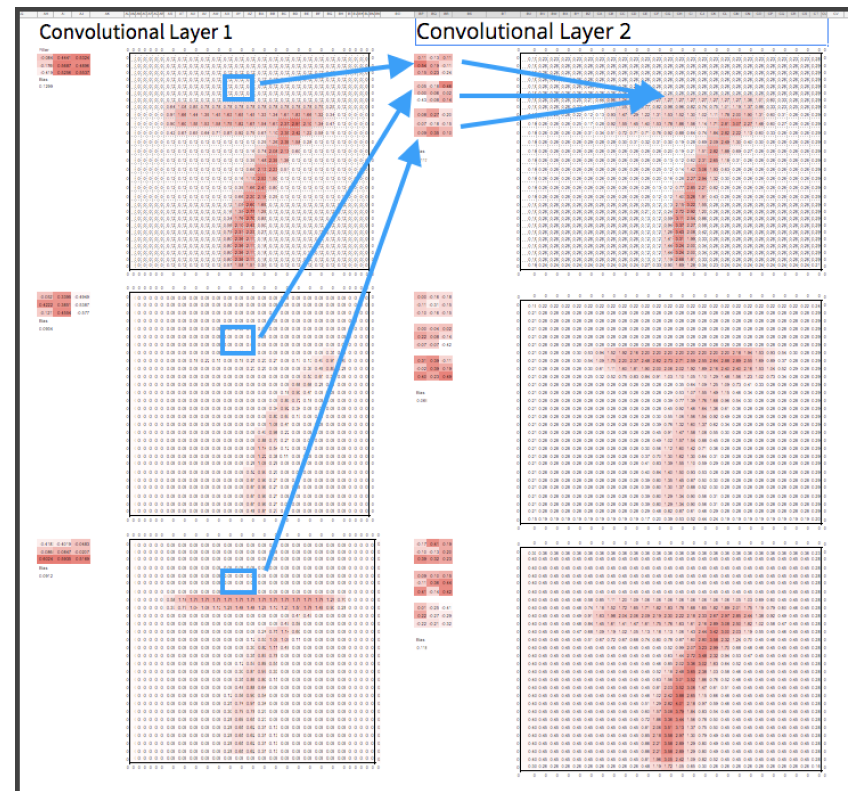 第二个卷积从上一个卷积层中提取相应的像素,并将每个像素乘以它自己的滤波器。和前面一样,我们对结果求和,这就为第二卷积层产生了一个新的对应像素。[/caption]
第二个卷积从上一个卷积层中提取相应的像素,并将每个像素乘以它自己的滤波器。和前面一样,我们对结果求和,这就为第二卷积层产生了一个新的对应像素。[/caption]严肃的CNN将有许多层,这使得模型可以建立越来越抽象和复杂的形状。即使只有4到5层,你的模型也可以开始寻找面孔、动物和各种有意义的形状。
神经网络
现在你可能会问自己,“那太好了,但是想出正确的过滤器听起来真的很乏味。”“最后呢我如何将这些过滤器中的所有答案组合成有用的东西?“。
首先,我们应该意识到,在高层次上,我们的CNN确实有两个“部分”。第一部分,卷积,为我们在图像数据中找到有用的特征。第二部分,电子表格末尾的“密集”层(之所以命名是因为每个神经元都有这么多的权重)为我们进行分类。一旦你有了这些特性,密集的图层和运行一系列线性回归并将它们组合成每个可能数字的分数并没有什么不同。最高分是模型的猜测。
[caption id="attachment_46905" align="aligncenter" width="884"]
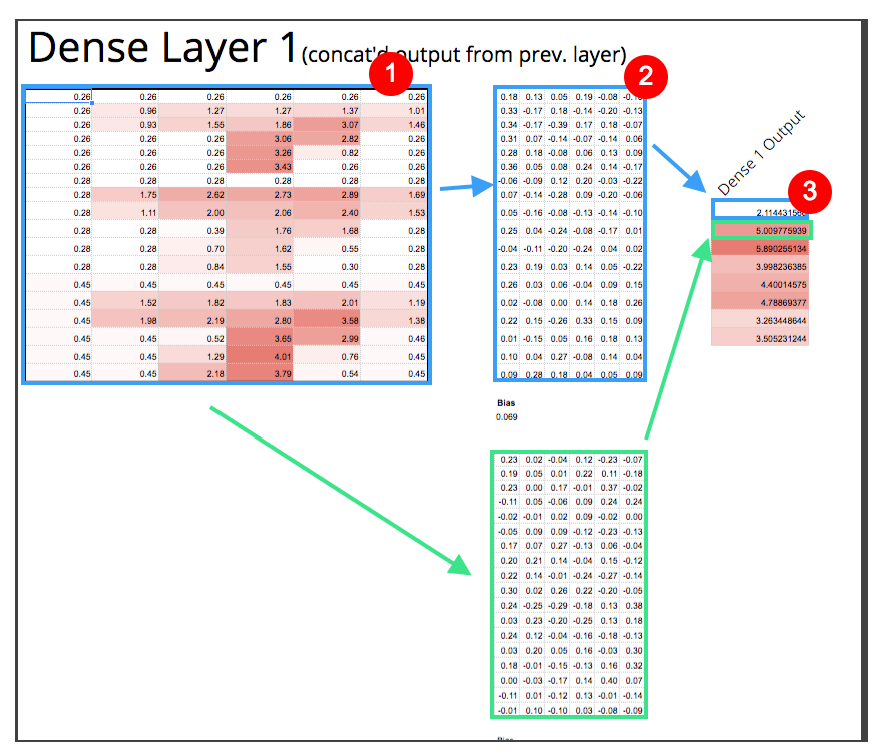 矩阵1是卷积的输出。然后将矩阵1中的每个像素乘以矩阵2中的相应数字它的和是3。对绿色的方框再次重复这个过程。你会得到8个输出,或者用深度学习术语来说就是“神经元”。[/caption]
矩阵1是卷积的输出。然后将矩阵1中的每个像素乘以矩阵2中的相应数字它的和是3。对绿色的方框再次重复这个过程。你会得到8个输出,或者用深度学习术语来说就是“神经元”。[/caption]为过滤器和最后的稠密层计算出所有合适的权重是非常烦人的。幸运的是,自动计算出这些权值是Neural Net的核心,所以我们不需要担心这个。但如果你好奇,你应该谷歌“反向传播”。
总结
每个CNN大概有两部分。卷积总是在开始时查找图像中有用的特征,而卷积的结尾通常被称为“密集层”,它根据这些特征对事物进行分类。
为了真正了解它们,我建议您使用spreadsheet。从头到尾跟踪一个像素。弄乱过滤器,看看会发生什么。我还在spreadsheet的注释中解释了更多的技术细节。
资源
要了解更多信息,我推荐以下资源:
交互式卷积-一个杀手交互式教程的卷积(即只是C部分,而不是NN部分),作者维克多鲍威尔。
对程序员的实际深入学习-从Fast.AI中学习的课程,我从中学到了很多,它是在线的,完全免费。
精彩的视频展示了CNN的基础知识——这是来自杰里米·霍华德(FastAI的创始人),这是一段20分钟的视频。这个非常棒的视频嵌入在那个页面中。从第21分钟开始看。
备注
[1]-训练CNN所需的数学包括微积分,因此它可以自动调整权重。但是一旦模型被训练,它实际上只需要乘法和加法来做预测在实践中,微积分是由你使用的任何深度学习库来处理的。
原文链接:https://medium.com/@bwest87/building-a-deep-neural-net-in-google-sheets-49cdaf466da0

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消