











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






CatBoost:一个自动处理分类数据的机器学习库
2017年08月16日 由 yining 发表
243030
0
在使用“sklearn”构建机器学习模型时,想必大家应该都遇到过下面这个错误吧:
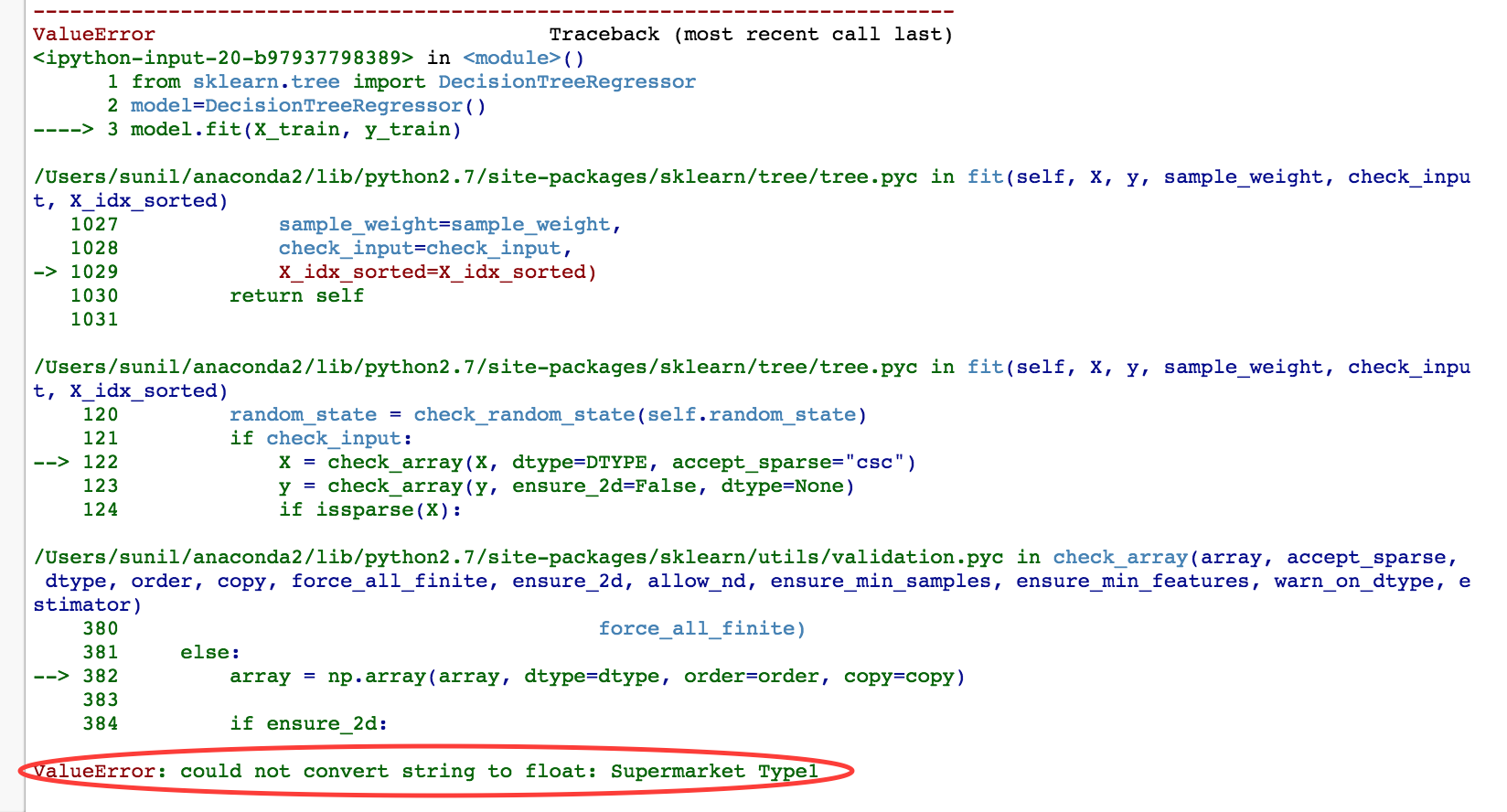
当处理分类(字符串)变量时,这个错误就发生了。在sklearn中,你需要在数值格式中转换这些分类。为了实现这种转换,我们使用了一些预处理方法,如“标签编码”、“独热编码”等。
在这篇文章中,我将讨论一个最近开源的梯度提升机器学习库“CatBoost”,由俄罗斯最大的搜索引擎Yandex开发和贡献。CatBoost可以直接使用分类功能,而且在本质上是可扩展的。
CatBoost一款最近开源的机器学习算法。它可以很容易地与像谷歌的TensorFlow和苹果的CoreML这样的深度学习框架集成在一起。同时,它也可以使用不同的数据类型来帮助企业解决各种各样的问题。最重要的是,它提供了最佳的精确度。
CatBoost在两方面尤其强大:
“CatBoost”这个名字来自两个词“Category”和“Boosting”。
如前所述,该库可以很好地处理各种类型的数据,如音频、文本、图像,包括历史数据。“Boost”来源于梯度提升机器学习算法,该算法基于梯度提升库。梯度提升是一种强大的机器学习算法,它被广泛应用于各种类型的商业挑战,如欺诈检测、推荐项目、预测等等。它还可以使用相对较少的数据得到非常好的结果,不像DL模型那样需要从大量数据中学习。

这里有一个关于CatBoost的视频:https://youtu.be/s8Q_orF4tcI
我们有多个提升库,比如XGBoost、H2O和LightGBM,所有这些库都能在各种问题上有着出色的表现。CatBoost的开发人员将其性能与标准ML数据集的竞争对手进行了比较:
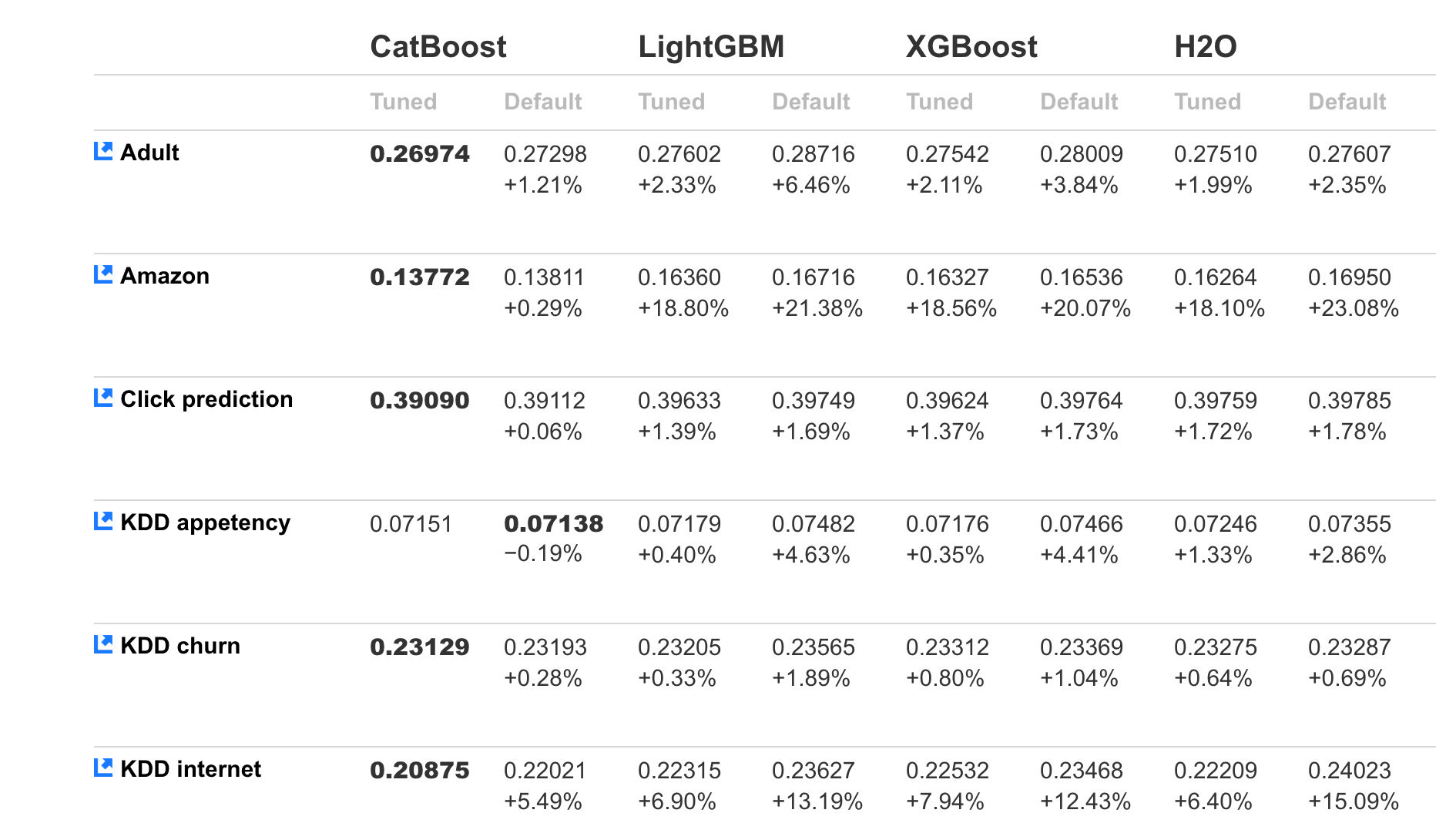
上面的比较显示了测试数据的对数损失(log-loss)值,在CatBoost的大多数情况下,它是最低的。图中清楚地表明了CatBoost对调优和默认模型的性能都更好。
此外,CatBoost不需要像XGBoost和LightGBM那样将数据集转换为任何特定格式。
对于Python和R语言,CatBoost很容易安装,你需要有64位版本的Python和R语言。
Python安装
R语言安装
CatBoost库可以用来解决分类和回归挑战。对于分类,你可以使用“CatBoostClassifier”,对于回归,使用“CatBoostRegressor”。
在这篇文章中,我用CatBoost解决了“Big Mart Sales”的实践问题。这是一个回归挑战,所以我们需要使用 CatBoostRegressor。
现在,你会发现我们只会识别分类变量。我们不会对分类变量执行任何预处理步骤:
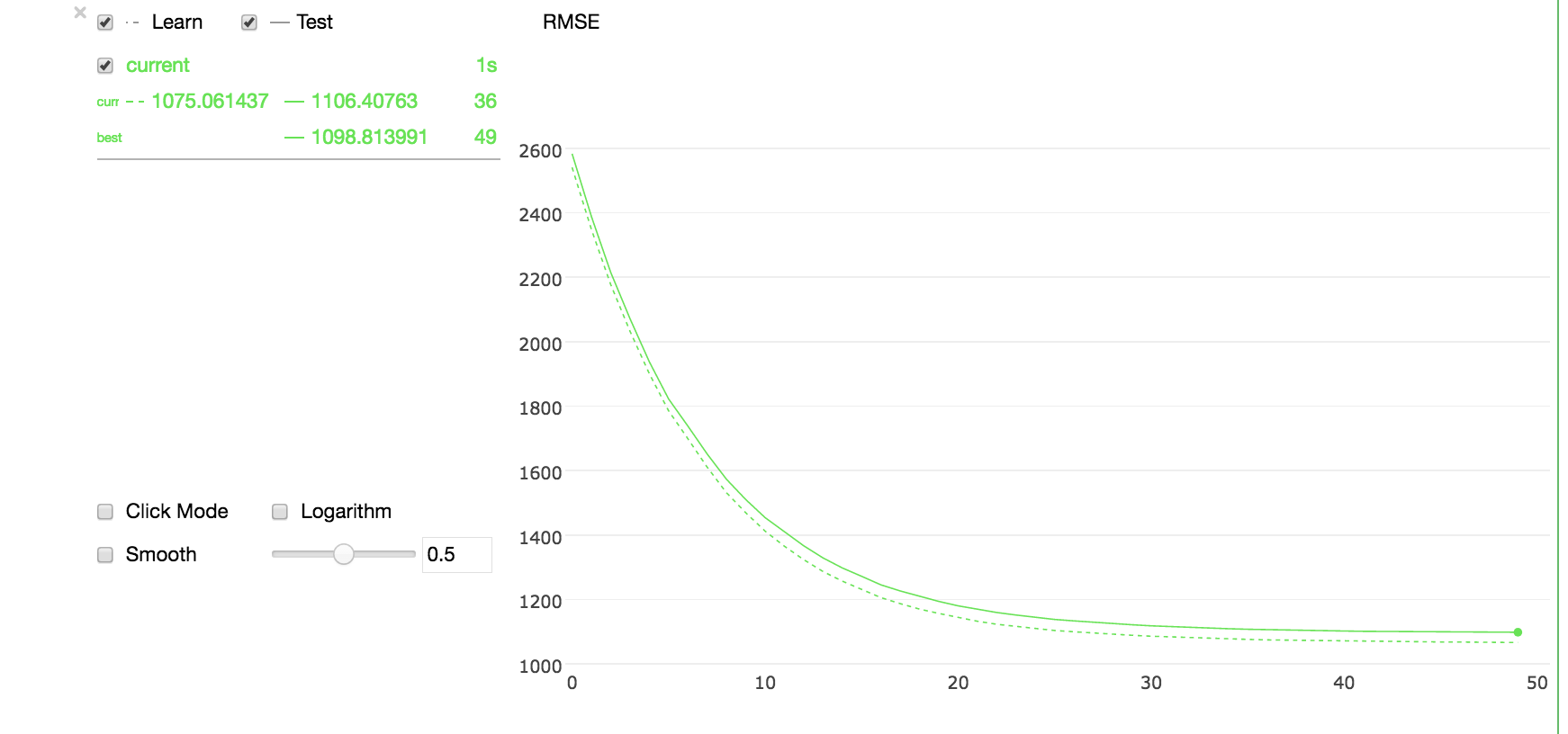
正如你所看到的,一个基本的模型给出了一个公平的解决方案,并且训练和测试错误是同步的。你可以优化模型参数和特性,以改进解决方案。
现在,下一个任务是预测测试数据集的结果。
就是这样!我们已经建立了第一个模型。
我们已经讨论了这个库的基本细节,并在本文中解决了回归挑战。我还建议你使用这个库来处理业务解决方案,并检查其它先进模型的性能。
当处理分类(字符串)变量时,这个错误就发生了。在sklearn中,你需要在数值格式中转换这些分类。为了实现这种转换,我们使用了一些预处理方法,如“标签编码”、“独热编码”等。
在这篇文章中,我将讨论一个最近开源的梯度提升机器学习库“CatBoost”,由俄罗斯最大的搜索引擎Yandex开发和贡献。CatBoost可以直接使用分类功能,而且在本质上是可扩展的。
内容
- CatBoost是什么?
- CatBoost库的优势
- 与其他提升(Boosting)算法相比,CatBoost怎么样?
- 安装CatBoost
- 使用CatBoost解决ML挑战
- 备注
CatBoost是什么?
CatBoost一款最近开源的机器学习算法。它可以很容易地与像谷歌的TensorFlow和苹果的CoreML这样的深度学习框架集成在一起。同时,它也可以使用不同的数据类型来帮助企业解决各种各样的问题。最重要的是,它提供了最佳的精确度。
CatBoost在两方面尤其强大:
- 它产生了最先进的结果,而且不需要进行广泛的数据训练(通常这些训练是其他机器学习方法所要求的)。
- 为更多的描述性数据格式提供了强大的“开箱即用”支持。
“CatBoost”这个名字来自两个词“Category”和“Boosting”。
如前所述,该库可以很好地处理各种类型的数据,如音频、文本、图像,包括历史数据。“Boost”来源于梯度提升机器学习算法,该算法基于梯度提升库。梯度提升是一种强大的机器学习算法,它被广泛应用于各种类型的商业挑战,如欺诈检测、推荐项目、预测等等。它还可以使用相对较少的数据得到非常好的结果,不像DL模型那样需要从大量数据中学习。
这里有一个关于CatBoost的视频:https://youtu.be/s8Q_orF4tcI
CatBoost库的优势
- 性能:CatBoost提供了一种先进效果,它在性能方面与任何领先的机器学习算法都可以抗衡。
- 自动处理分类特性:我们可以使用CatBoost,而不需要任何显式的预处理来将类别转换为数字。CatBoost使用在各种统计上的分类特征和数值特征的组合将分类值转换成数字。你可以在这里读到更多相关信息。
- 鲁棒性/强健性:它减少了对广泛的超参数调优的需求,并降低了过度拟合的机会,这也导致了模型变得更加具有通用性。虽然CatBoost有多个参数可以调优,但它还包含一些参数,比如树的数量、学习速率、正则化、树的深度等等。
你可以在这里阅读这些参数。 - 易于使用:你可以使用来自命令行的CatBoost,使用针对Python和R语言这样的易于使用的API。
与其他提升(Boosting)算法相比,CatBoost怎么样?
我们有多个提升库,比如XGBoost、H2O和LightGBM,所有这些库都能在各种问题上有着出色的表现。CatBoost的开发人员将其性能与标准ML数据集的竞争对手进行了比较:
上面的比较显示了测试数据的对数损失(log-loss)值,在CatBoost的大多数情况下,它是最低的。图中清楚地表明了CatBoost对调优和默认模型的性能都更好。
此外,CatBoost不需要像XGBoost和LightGBM那样将数据集转换为任何特定格式。
安装CatBoost
对于Python和R语言,CatBoost很容易安装,你需要有64位版本的Python和R语言。
Python安装
pip install catboost
R语言安装
install.packages('devtools')
devtools::install_github('catboost/catboost', subdir = 'catboost/R-package')使用CatBoost解决ML挑战
CatBoost库可以用来解决分类和回归挑战。对于分类,你可以使用“CatBoostClassifier”,对于回归,使用“CatBoostRegressor”。
在这篇文章中,我用CatBoost解决了“Big Mart Sales”的实践问题。这是一个回归挑战,所以我们需要使用 CatBoostRegressor。
import pandas as pd
import numpy as np
from catboost import CatBoostRegressor
#Read trainig and testing files
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")
#Identify the datatype of variables
train.dtypes

#Finding the missing values
train.isnull().sum()

#Imputing missing values for both train and test
train.fillna(-999, inplace=True)
test.fillna(-999,inplace=True)
#Creating a training set for modeling and validation set to check model performance
X = train.drop(['Item_Outlet_Sales'], axis=1)
y = train.Item_Outlet_Sales
from sklearn.model_selection import train_test_split
X_train, X_validation, y_train, y_validation = train_test_split(X, y, train_size=0.7, random_state=1234)
#Look at the data type of variables
X.dtypes
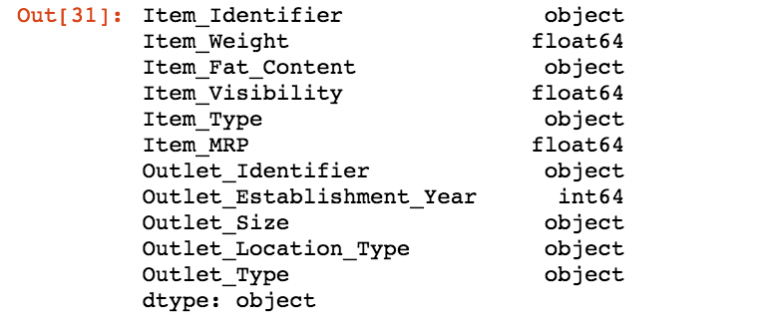
现在,你会发现我们只会识别分类变量。我们不会对分类变量执行任何预处理步骤:
categorical_features_indices = np.where(X.dtypes != np.float)[0]
#importing library and building model
from catboost import CatBoostRegressor
model=CatBoostRegressor(iterations=50, depth=3, learning_rate=0.1, loss_function='RMSE')
model.fit(X_train, y_train,cat_features=categorical_features_indices,eval_set=(X_validation, y_validation),plot=True)
正如你所看到的,一个基本的模型给出了一个公平的解决方案,并且训练和测试错误是同步的。你可以优化模型参数和特性,以改进解决方案。
现在,下一个任务是预测测试数据集的结果。
submission = pd.DataFrame()
submission['Item_Identifier'] = test['Item_Identifier']
submission['Outlet_Identifier'] = test['Outlet_Identifier']
submission['Item_Outlet_Sales'] = model.predict(test)
submission.to_csv("Submission.csv")
就是这样!我们已经建立了第一个模型。
备注
我们已经讨论了这个库的基本细节,并在本文中解决了回归挑战。我还建议你使用这个库来处理业务解决方案,并检查其它先进模型的性能。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消