












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






伯克利人工智能研究项目:为图像自动添加准确的说明
2017年08月09日 由 yining 发表
172470
0
人类可以很容易地推断出给定图像中最突出的物体,并能描述出场景内容,如物体所处于的环境或是物体特征。而且,重要的是,物体与物体之间如何在同一个场景中互动。视觉描述的任务是开发视觉系统来生成图像中物体的上下文描述。视觉描述是具有挑战性的,因为它不仅需要识别对象目标,还有其他视觉元素,如行动和属性,然后构建一个流利的句子去描述图像中的对象,其属性及行动(如:棕熊站森林里的一颗石头上)。


当前的视觉描述或图像文字说明模型工作得很好,但它们只能描述现有图像的文字说明训练数据集所看到的对象,而且需要大量训练样本才能生成良好的说明。为了学习如何描述像“豺狼”或“食蚁兽”这样的物体,大多数描述模型都需要许多带有相应描述的豺狼或食蚁兽的图片。但是,当前的视觉描述数据集,比如:MSCOCO,不包含对所有对象的描述。相比之下,最近通过卷积神经网络(CNNs)的对象识别工作可以识别出数百种对象类型。虽然对象识别模型可以识别出豺狼和食蚁兽,但描述模型不能在上下文环境中正确地描述这些动物。在我们的工作中,我们通过建立视觉描述系统来克服这个问题,这个系统可以描述新的物体,而不需要对这些物体的图像和句子进行描述。
在这里,我们更正式地定义我们的任务。给定一个数据集,包括一对图像和描述(配对的图像-句子数据,例如:MSCOCO),以及带有对象标签的图像,但是没有描述(没有配对的图像数据,如:ImageNet),我们希望学习如何描述在配对的图像-句子数据中看不见的对象。要做到这一点,我们必须建立一个能够识别不同视觉成分的模型(例如: 杰克,布朗,站立,和田野)以新颖的方式组合词汇,形成一个连贯的描述。
下面将介绍我们描述模型的核心组件:
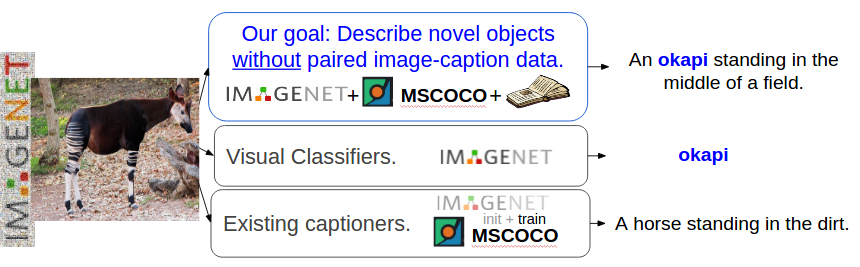
我们的目标是描述不同的物体,这些物体没有训练图片的说明。
为了在图像的说明训练数据之外生成不同类别的对象的描述,我们利用了外部数据源。具体来说,我们使用对象标签的ImageNet图像作为未配对的图像数据源,和来自未加注解的文本库的句子,例如,维基百科(Wikipedia)作为我们的文本数据源。它们分别用于训练视觉识别CNN和语言模型。

我们希望能够描述从未见过的对象(例如,来自ImageNet),这些对象与在成对的图像-句子训练数据中看到的对象相似。为了达到这个目标,我们使用了密集的词嵌入。词嵌入是一种密集的高维度词汇描述,在嵌入空间中有类似含义的词会相互接近。
在我们之前的工作中,称为“深度组合说明(DCC)”,我们首先在MSCOCO配对图像说明数据集上训练一个说明模型。然后,为了描述新的对象,对于每一个新的对象,比如,“霍加狓”(长颈鹿科的一种),我们使用词嵌入来识别在与MSCOCO数据集的对象中最相似的对象(在这个例子中是斑马)。然后,我们将模型从所看到的对象(复制)的参数转移到未看到的对象(即在网络中将与斑马对应和与霍加狓对应的权值复制)。
当DCC模型能够描述几个从未见过的对象类别时,将参数从一个对象复制到另一个对象可以创建具有语法工件的句子。例: 对于物体“球拍”,模型复制了“网球”的权值,组成句子的话是“一个人在球场上打“球拍”。在我们最近的工作中,我们直接把词汇嵌入在我们的语言模型中。具体地说,我们在语言模型的输入和输出中使用了GloVe嵌入。它可以含蓄地使模型在描述未见过的对象时捕获相似的语义。这使得我们的模型能够产生一些句子,例如“一个网球运动员在一个球上摆动球拍”。此外,在网络中直接整合嵌入式系统可以使我们的模型可进行端对端训练。
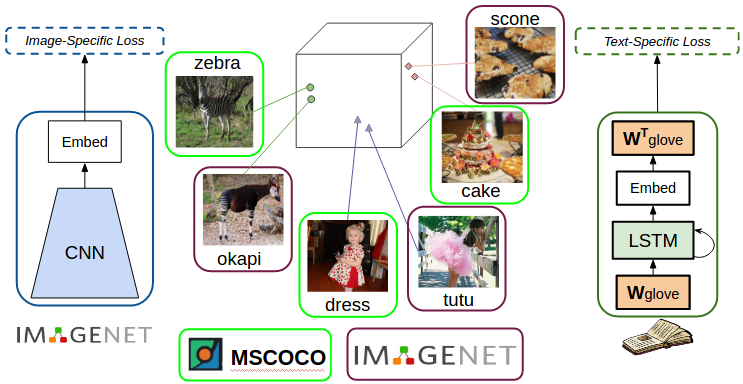
在语言模型中加入密集的词嵌入,以捕获相似的语义。
我们将可视网络和语言模型的输出结合到说明模型中。这个模型类似于现有的说明模型,这些模型也在ImageNet上预先训练过。然而,我们注意到,尽管这个模型是在ImageNet上预先训练的,当模型被训练/调到COCO图像-标题数据集时,它往往会忘记它之前看到的物体。
蒙特利尔的研究人员和其他一些研究人员也观察到了在神经网络中遗忘的问题。
在我们的工作中,我们使用联合训练策略解决了模型“遗忘”的问题。
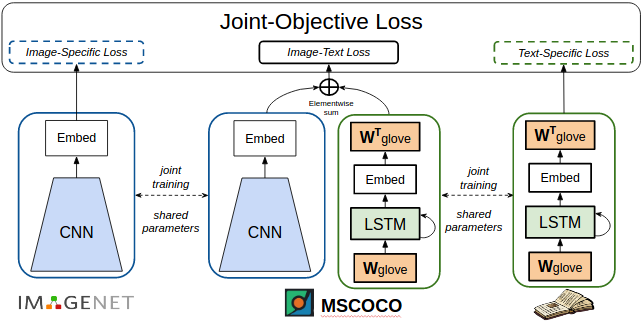
具体来说,我们的网络有三个组成部分:一个可视识别网络、一个说明模型和一个语言模型。这三个组件都共享参数,并进行了联合训练。在训练过程中,每一批输入都包含有标签的图片,不同的图片和说明,以及一些简单的句子。这三个输入训练网络的不同组成部分。由于这些参数是在三个组件之间共享的,因此网络被联合训练来识别图像中的对象、说明图像和生成句子。这种联合训练可以帮助网络克服遗忘的问题,并使模型能够为许多新的对象类别生成描述。
在我们的模型中,最常见的错误之一是没有识别对象,而减少这一点的一种方法是使用更好的可视特性。另一个常见的错误是产生不通顺的句子(例:一只猫和一只猫在床上)。
在这项工作中,我们建议将联合训练作为一种克服遗忘问题的策略,但在许多不同的任务和数据集上进行训练并不总是可行的。解决这个问题的另一种方法是构建一个模型,该模型可以根据可视信息和对象标签来编写描述。这样的模型也应该能够在动态中集成对象,也就是说,当前我们在一组特定的对象上预先训练模型,我们也应该考虑如何在新的数据上增量地训练我们的模型。解决这些问题可以帮助我们开发出更好的可视化描述模型。
[更多例子]
[训练模型和代码]

这篇文章的内容基于以下的研究论文:
[1] L. A. Hendricks, S. Venugopalan, M. Rohrbach, R. Mooney, K. Saenko, and T. Darrell. Deep compositional captioning: Describing novel object categories without paired training data. In CVPR, 2016.
[2] S. Venugopalan, L. A. Hendricks, M. Rohrbach, R. Mooney, K. Saenko, and T. Darrell. Captioning images with diverse objects. In CVPR, 2017.
视觉描述现状
LRCN [Donahue et al. ‘15]: 一头黑熊站在草地上。
MS CaptionBot [Tran et al. ‘16]: 一头熊在吃草。
LRCN [Donahue et al. ‘15]: 一头棕熊站在茂盛的绿色田野上。
MS CaptionBot [Tran et al. ‘16]: 一头大棕熊在森林里散步。
在两个图像上,由现有的说明文字生成描述。左边是在训练数据中出现的对象(熊)的图像。右边是模型在训练中没有见过的对象(食蚁兽)。
当前的视觉描述或图像文字说明模型工作得很好,但它们只能描述现有图像的文字说明训练数据集所看到的对象,而且需要大量训练样本才能生成良好的说明。为了学习如何描述像“豺狼”或“食蚁兽”这样的物体,大多数描述模型都需要许多带有相应描述的豺狼或食蚁兽的图片。但是,当前的视觉描述数据集,比如:MSCOCO,不包含对所有对象的描述。相比之下,最近通过卷积神经网络(CNNs)的对象识别工作可以识别出数百种对象类型。虽然对象识别模型可以识别出豺狼和食蚁兽,但描述模型不能在上下文环境中正确地描述这些动物。在我们的工作中,我们通过建立视觉描述系统来克服这个问题,这个系统可以描述新的物体,而不需要对这些物体的图像和句子进行描述。
任务:描述新对象
在这里,我们更正式地定义我们的任务。给定一个数据集,包括一对图像和描述(配对的图像-句子数据,例如:MSCOCO),以及带有对象标签的图像,但是没有描述(没有配对的图像数据,如:ImageNet),我们希望学习如何描述在配对的图像-句子数据中看不见的对象。要做到这一点,我们必须建立一个能够识别不同视觉成分的模型(例如: 杰克,布朗,站立,和田野)以新颖的方式组合词汇,形成一个连贯的描述。
下面将介绍我们描述模型的核心组件:
我们的目标是描述不同的物体,这些物体没有训练图片的说明。
使用外部数据来源
为了在图像的说明训练数据之外生成不同类别的对象的描述,我们利用了外部数据源。具体来说,我们使用对象标签的ImageNet图像作为未配对的图像数据源,和来自未加注解的文本库的句子,例如,维基百科(Wikipedia)作为我们的文本数据源。它们分别用于训练视觉识别CNN和语言模型。
有效地训练外部资源
捕捉语义相似度
我们希望能够描述从未见过的对象(例如,来自ImageNet),这些对象与在成对的图像-句子训练数据中看到的对象相似。为了达到这个目标,我们使用了密集的词嵌入。词嵌入是一种密集的高维度词汇描述,在嵌入空间中有类似含义的词会相互接近。
在我们之前的工作中,称为“深度组合说明(DCC)”,我们首先在MSCOCO配对图像说明数据集上训练一个说明模型。然后,为了描述新的对象,对于每一个新的对象,比如,“霍加狓”(长颈鹿科的一种),我们使用词嵌入来识别在与MSCOCO数据集的对象中最相似的对象(在这个例子中是斑马)。然后,我们将模型从所看到的对象(复制)的参数转移到未看到的对象(即在网络中将与斑马对应和与霍加狓对应的权值复制)。
对象说明
当DCC模型能够描述几个从未见过的对象类别时,将参数从一个对象复制到另一个对象可以创建具有语法工件的句子。例: 对于物体“球拍”,模型复制了“网球”的权值,组成句子的话是“一个人在球场上打“球拍”。在我们最近的工作中,我们直接把词汇嵌入在我们的语言模型中。具体地说,我们在语言模型的输入和输出中使用了GloVe嵌入。它可以含蓄地使模型在描述未见过的对象时捕获相似的语义。这使得我们的模型能够产生一些句子,例如“一个网球运动员在一个球上摆动球拍”。此外,在网络中直接整合嵌入式系统可以使我们的模型可进行端对端训练。
在语言模型中加入密集的词嵌入,以捕获相似的语义。
在神经网络中说明模型和模型的遗忘
我们将可视网络和语言模型的输出结合到说明模型中。这个模型类似于现有的说明模型,这些模型也在ImageNet上预先训练过。然而,我们注意到,尽管这个模型是在ImageNet上预先训练的,当模型被训练/调到COCO图像-标题数据集时,它往往会忘记它之前看到的物体。
蒙特利尔的研究人员和其他一些研究人员也观察到了在神经网络中遗忘的问题。
在我们的工作中,我们使用联合训练策略解决了模型“遗忘”的问题。
共享参数,并在不同的数据/任务上进行联合训练来克服“遗忘”
具体来说,我们的网络有三个组成部分:一个可视识别网络、一个说明模型和一个语言模型。这三个组件都共享参数,并进行了联合训练。在训练过程中,每一批输入都包含有标签的图片,不同的图片和说明,以及一些简单的句子。这三个输入训练网络的不同组成部分。由于这些参数是在三个组件之间共享的,因此网络被联合训练来识别图像中的对象、说明图像和生成句子。这种联合训练可以帮助网络克服遗忘的问题,并使模型能够为许多新的对象类别生成描述。
接下来做什么?
在我们的模型中,最常见的错误之一是没有识别对象,而减少这一点的一种方法是使用更好的可视特性。另一个常见的错误是产生不通顺的句子(例:一只猫和一只猫在床上)。
在这项工作中,我们建议将联合训练作为一种克服遗忘问题的策略,但在许多不同的任务和数据集上进行训练并不总是可行的。解决这个问题的另一种方法是构建一个模型,该模型可以根据可视信息和对象标签来编写描述。这样的模型也应该能够在动态中集成对象,也就是说,当前我们在一组特定的对象上预先训练模型,我们也应该考虑如何在新的数据上增量地训练我们的模型。解决这些问题可以帮助我们开发出更好的可视化描述模型。
[更多例子]
[训练模型和代码]
例子
这篇文章的内容基于以下的研究论文:
[1] L. A. Hendricks, S. Venugopalan, M. Rohrbach, R. Mooney, K. Saenko, and T. Darrell. Deep compositional captioning: Describing novel object categories without paired training data. In CVPR, 2016.
[2] S. Venugopalan, L. A. Hendricks, M. Rohrbach, R. Mooney, K. Saenko, and T. Darrell. Captioning images with diverse objects. In CVPR, 2017.

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消