











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Python/PyMC3/ArviZ贝叶斯统计实战(上)
2019年09月07日 由 sunlei 发表
281210
0
如果你认为贝叶斯定理是反直觉的,那么建立在贝叶斯定理基础上的贝叶斯统计就很难理解。在这一点上我和你的感受完全一致。
学习贝叶斯统计有无数的理由,尤其是贝叶斯统计正在成为表达和理解下一代深度神经网络的强大框架。
我相信,对于我们必须学习的东西,在我们能使用它们之前,我们通过使用它们来学习。生活中没有什么是如此艰难,通过我们采取的方式我们可以让它变得更容易。
所以,这是我简化它的方法:与其在开始时使用过多的理论或术语,不如让我们关注贝叶斯分析的机制,特别是如何使用PyMC3和ArviZ进行贝叶斯分析和可视化。在记忆无穷无尽的术语之前,我们将对解决方案进行编码并将结果可视化,并使用术语和理论解释模型。
PyMC3是一个用于概率编程的Python库,语法非常简单直观。ArviZ是一个与PyMC3携手工作的Python库,它可以帮助我们解释和可视化后验分布。
我们将把贝叶斯方法应用到一个实际问题中,展示一个端到端的贝叶斯分析,它从构建问题到建立模型到获得先验概率再到在Python中实现最终的后验分布。
在我们开始之前,让我们先得出一些基本的直觉:
贝叶斯模型也被称为概率模型,因为它们是用概率建立的。贝叶斯利用概率作为量化不确定性的工具。因此,我们得到的答案是分布而不是点估计。
步骤1:建立关于数据的信念,包括先验函数和似然函数。
步骤2:根据我们对数据的信念,使用数据和概率,更新我们的模型,检查我们的模型是否与原始数据一致。
步骤3:根据模型更新数据视图。
由于我对使用机器学习进行价格优化很感兴趣,所以我决定将贝叶斯方法应用到一个西班牙高铁票价数据集,该数据集可以在这里找到。感谢Gurus团队对数据集的搜集。

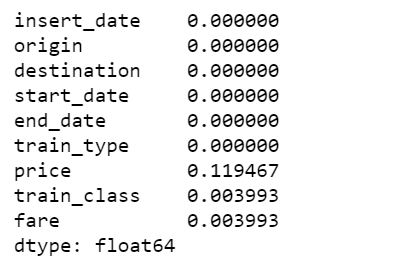
价格栏中有12%的值丢失了,我决定用相应票价类型的平均值来填充它们。还用最常见的值填充其他两个分类列。
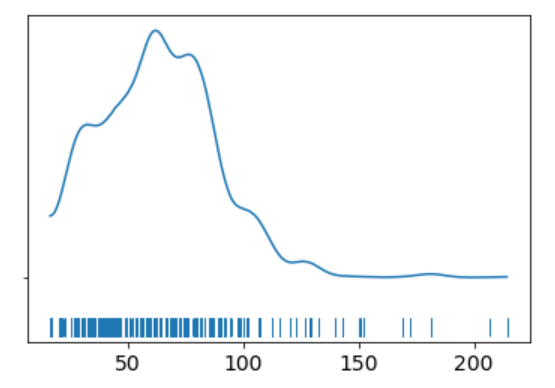
铁路票价的KDE图显示了高斯分布,除了几十个远离均值的数据点。
假设高斯分布是对火车票价格的恰当描述。由于我们不知道平均值或标准差,所以必须为这两个值设置优先级。因此,一个合理的模型可以是这样的。
我们将对票价数据进行高斯推断。这里有一些模型选择。
我们将在PyMC3中这样实例化模型:
先验选择:
票价似然函数的选择:
使用PyMC3,我们可以将模型写成:
y表示可能性。这就是我们告诉PyMC3我们要根据已知(数据)为未知条件设置条件的方式。
我们绘制高斯模型轨迹。这是运行在一个Theano图表下的引擎盖。
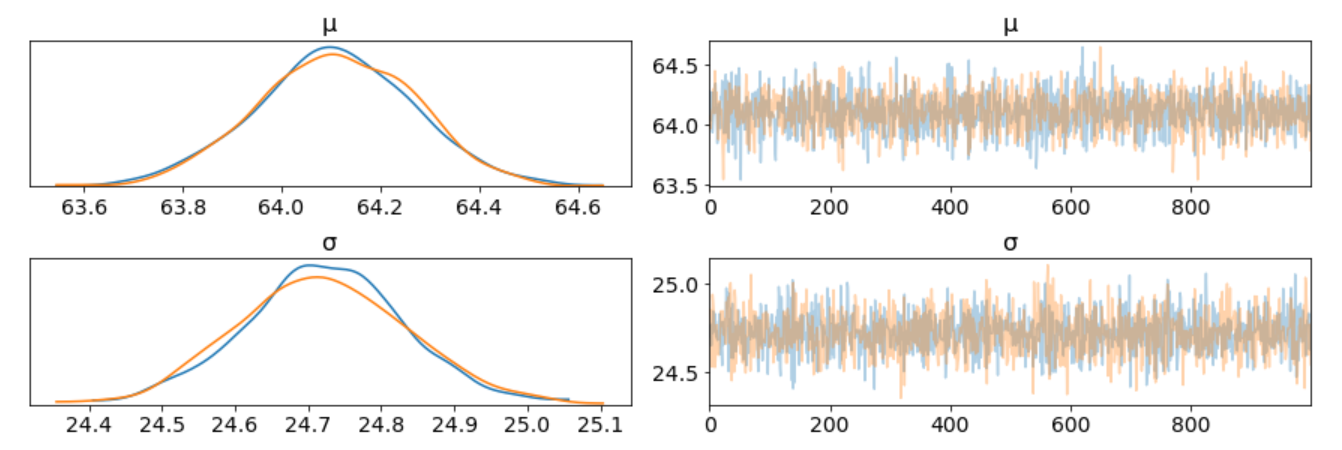
这里有几点需要注意:
我们可以绘制参数的联合分布。
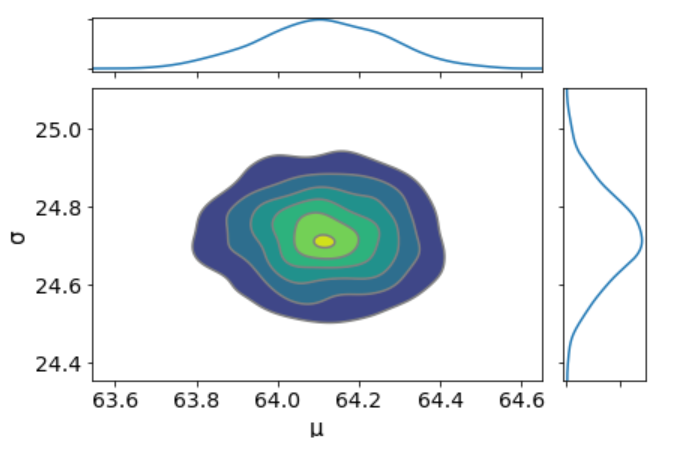
我看不出这两个参数之间有任何关联。这意味着模型中可能没有共线性。这是很好的。
我们还可以对每个参数的后验分布进行详细的总结。

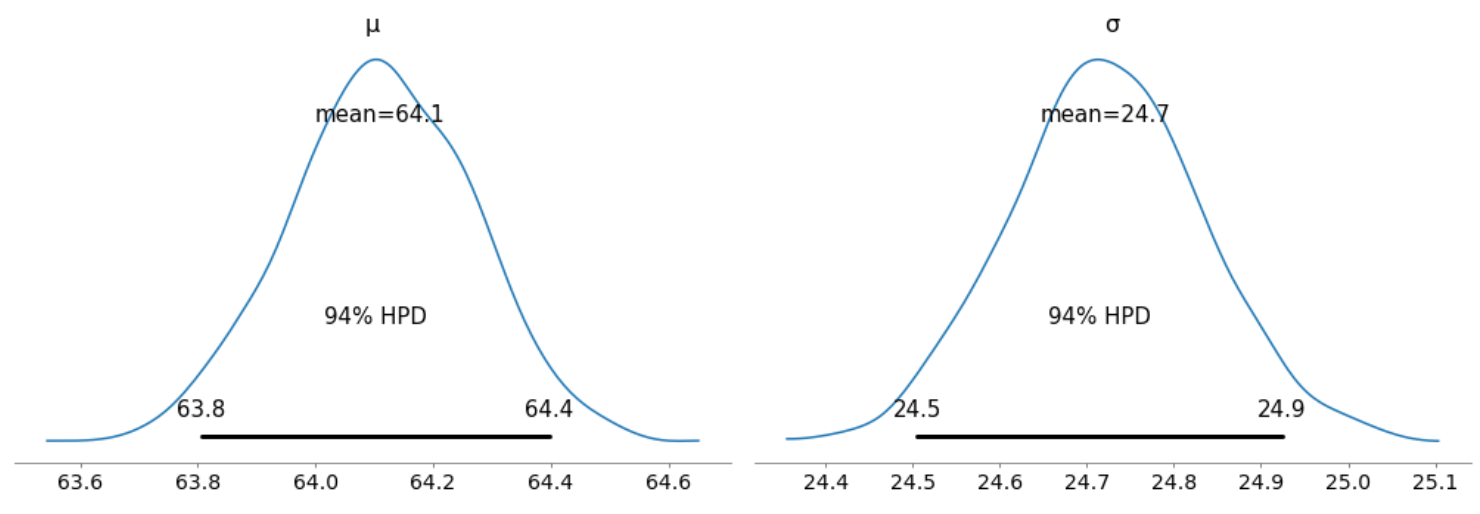
我们还可以通过生成一个分布的均值和最高后验密度(HPD)的图来直观地看到上述总结,并解释和报告贝叶斯推断的结果。
我们可以用Gelman Rubin检验来验证链的收敛性。接近1.0的值表示收敛。
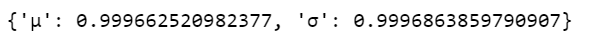
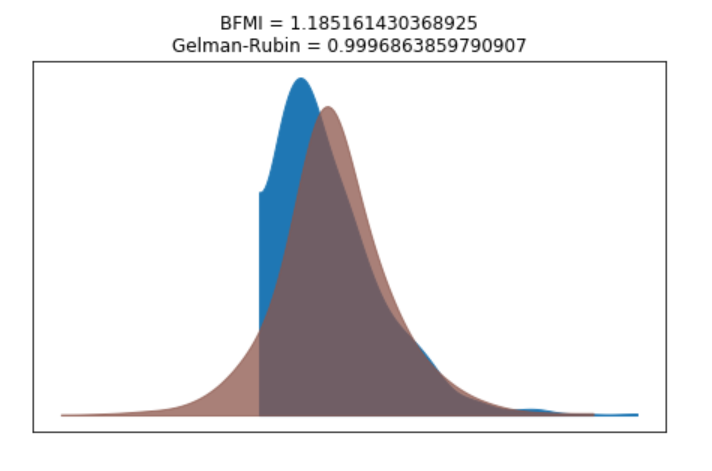
我们的模型收敛得很好,Gelman Rubin数据看起来也不错。
在今天的学习当中,我们了解了贝叶斯方法步骤和高斯推论,也将贝叶斯方法应用到一个实际问题中,展示一个端到端的贝叶斯分析,明天我会继续更新接下来的内容。
学习贝叶斯统计有无数的理由,尤其是贝叶斯统计正在成为表达和理解下一代深度神经网络的强大框架。
我相信,对于我们必须学习的东西,在我们能使用它们之前,我们通过使用它们来学习。生活中没有什么是如此艰难,通过我们采取的方式我们可以让它变得更容易。
所以,这是我简化它的方法:与其在开始时使用过多的理论或术语,不如让我们关注贝叶斯分析的机制,特别是如何使用PyMC3和ArviZ进行贝叶斯分析和可视化。在记忆无穷无尽的术语之前,我们将对解决方案进行编码并将结果可视化,并使用术语和理论解释模型。
PyMC3是一个用于概率编程的Python库,语法非常简单直观。ArviZ是一个与PyMC3携手工作的Python库,它可以帮助我们解释和可视化后验分布。
我们将把贝叶斯方法应用到一个实际问题中,展示一个端到端的贝叶斯分析,它从构建问题到建立模型到获得先验概率再到在Python中实现最终的后验分布。
在我们开始之前,让我们先得出一些基本的直觉:
贝叶斯模型也被称为概率模型,因为它们是用概率建立的。贝叶斯利用概率作为量化不确定性的工具。因此,我们得到的答案是分布而不是点估计。
贝叶斯方法步骤
步骤1:建立关于数据的信念,包括先验函数和似然函数。
步骤2:根据我们对数据的信念,使用数据和概率,更新我们的模型,检查我们的模型是否与原始数据一致。
步骤3:根据模型更新数据视图。
数据
由于我对使用机器学习进行价格优化很感兴趣,所以我决定将贝叶斯方法应用到一个西班牙高铁票价数据集,该数据集可以在这里找到。感谢Gurus团队对数据集的搜集。
from scipy import stats
import arviz as az
import numpy as np
import matplotlib.pyplot as plt
import pymc3 as pm
import seaborn as sns
import pandas as pd
from theano import shared
from sklearn import preprocessingprint('Running on PyMC3 v{}'.format(pm.__version__))data = pd.read_csv('renfe.csv')
data.drop('Unnamed: 0', axis = 1, inplace=True)
data = data.sample(frac=0.01, random_state=99)
data.head(3)
data.isnull().sum()/len(data)
价格栏中有12%的值丢失了,我决定用相应票价类型的平均值来填充它们。还用最常见的值填充其他两个分类列。
data['train_class'] = data['train_class'].fillna(data['train_class'].mode().iloc[0])
data['fare'] = data['fare'].fillna(data['fare'].mode().iloc[0])
data['price'] = data.groupby('fare').transform(lambda x:
x.fillna(x.mean()))
高斯推论
az.plot_kde(data['price'].values, rug=True)
plt.yticks([0], alpha=0);
铁路票价的KDE图显示了高斯分布,除了几十个远离均值的数据点。
假设高斯分布是对火车票价格的恰当描述。由于我们不知道平均值或标准差,所以必须为这两个值设置优先级。因此,一个合理的模型可以是这样的。
模型
我们将对票价数据进行高斯推断。这里有一些模型选择。
我们将在PyMC3中这样实例化模型:
- PyMC3中的模型规范封装在with语句中。
先验选择:
- μ,指人口。正态分布很广。我不知道μ的可能的值,我可以设置先验。根据经验,我知道火车票价格不能低于0或高于300,所以我将均匀分布的边界设为0和300。你可能有不同的经历,设定不同的界限。完全没问题。如果你有比我更可靠的信息,请使用它!
- σ,标准差的人口。只能是正的,因此使用半正态分布。再来一次,非常宽广。
票价似然函数的选择:
- y是一个观测变量,代表的数据来自正态分布的参数μ、σ。
- 使用螺母取样绘制1000个后验样本。
使用PyMC3,我们可以将模型写成:
with pm.Model() as model_g:
μ = pm.Uniform('μ', lower=0, upper=300)
σ = pm.HalfNormal('σ', sd=10)
y = pm.Normal('y', mu=μ, sd=σ, observed=data['price'].values)
trace_g = pm.sample(1000, tune=1000)
y表示可能性。这就是我们告诉PyMC3我们要根据已知(数据)为未知条件设置条件的方式。
我们绘制高斯模型轨迹。这是运行在一个Theano图表下的引擎盖。
az.plot_trace(trace_g);
- 在左边,我们有一个KDE图,对于x轴上的每个参数值我们在y轴上得到一个概率它告诉我们参数值的可能性有多大。
- 在右边,我们得到了采样过程中每个步骤的单独采样值。从轨迹图中,我们可以从后面直观地得到可信的值。
- 上面的图中每个参数都有一行。对于这个模型,后面是二维的,因此上图显示了每个参数的边缘分布。
这里有几点需要注意:
- 我们对单个参数的采样链(左)似乎很好地收敛和稳定(没有大的漂移或其他奇怪的模式)。
- 每个变量的最大后验估计(左侧分布的峰值)非常接近真实参数。
我们可以绘制参数的联合分布。
az.plot_joint(trace_g, kind='kde', fill_last=False);
我看不出这两个参数之间有任何关联。这意味着模型中可能没有共线性。这是很好的。
我们还可以对每个参数的后验分布进行详细的总结。
az.summary(trace_g)
我们还可以通过生成一个分布的均值和最高后验密度(HPD)的图来直观地看到上述总结,并解释和报告贝叶斯推断的结果。
az.plot_posterior(trace_g);
- 与频域推理不同,在贝叶斯推理中,我们得到了整个值的分布。
- 每次ArviZ计算和报告HPD时,默认情况下它将使用94%的值。
- 请注意,HPD间隔与confidence间隔不同。
- 在这里,我们可以这样解释,94%的概率,相信平均票价在8欧元到64.4欧元之间。
我们可以用Gelman Rubin检验来验证链的收敛性。接近1.0的值表示收敛。
pm.gelman_rubin(trace_g)
bfmi = pm.bfmi(trace_g)
max_gr = max(np.max(gr_stats) for gr_stats in pm.gelman_rubin(trace_g).values())
(pm.energyplot(trace_g, legend=False, figsize=(6, 4)).set_title("BFMI = {}\nGelman-Rubin = {}".format(bfmi, max_gr)));
我们的模型收敛得很好,Gelman Rubin数据看起来也不错。
在今天的学习当中,我们了解了贝叶斯方法步骤和高斯推论,也将贝叶斯方法应用到一个实际问题中,展示一个端到端的贝叶斯分析,明天我会继续更新接下来的内容。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消