











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






可解释机器学习Python库
2019年08月17日 由 sunlei 发表
397400
0
随着对人工智能中偏见的担忧变得越来越突出,企业能够解释其模型所产生的预测以及模型本身如何工作,变得越来越重要。幸运的是,越来越多的python库正在开发来解决这个问题。在下面文章中,我将简要介绍四个最成熟的机器学习模型的解释和解释软件包。
以下库都是pip可安装的,带有良好的文档,并且强调可视化解释。
yellowbrick
这个库本质上是scikit-learn库的一个扩展,为机器学习模型提供了一些非常有用和漂亮的可视化。visualiser对象,即核心接口,是scikit-learn评估器,因此如果您习惯于使用scikit-learn,那么工作流程应该非常熟悉。
可以呈现的可视化包括模型选择、特征导入和模型性能分析。
让我们看几个简单的例子。
库可以通过pip安装。
pip install yellowbrick
为了说明一些特性,我将使用一个名为wine recognition set的scikit-learn数据集。这个数据集有13个特性和3个目标类,可以直接从scikit-learn库加载。在下面的代码中,我导入数据集并将其转换为数据帧。数据可以在分类器中使用,而不需要任何额外的预处理。
import pandas as pd
from sklearn import datasets
wine_data = datasets.load_wine()
df_wine =
pd.DataFrame(wine_data.data,columns=wine_data.feature_names)
df_wine['target'] = pd.Series(wine_data.target)
我还使用scikit-learn将数据集进一步分解为测试和训练。
from sklearn.model_selection import train_test_split
X = df_wine.drop(['target'], axis=1)
y = df_wine['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
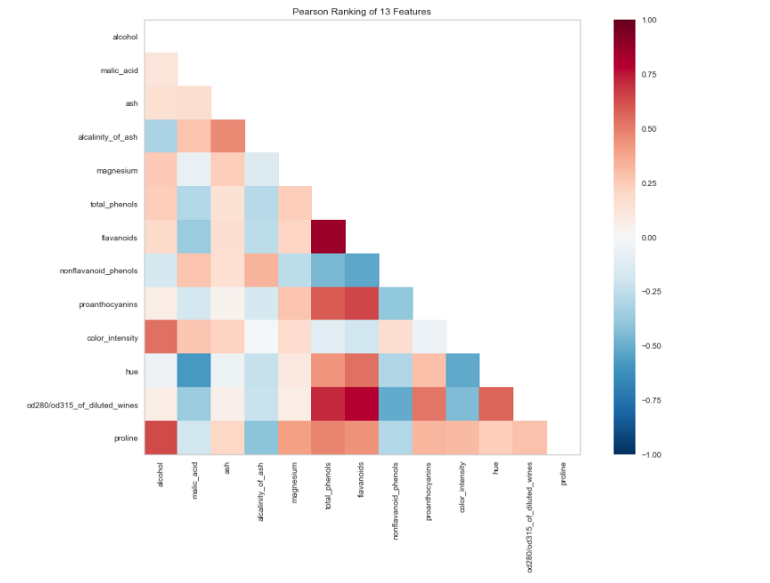
接下来,让我们使用Yellowbricks 可视化工具来查看数据集中各功能之间的相关性。
from yellowbrick.features import Rank2D
import matplotlib.pyplot as plt
visualizer = Rank2D(algorithm="pearson", size=(1080, 720))
visualizer.fit_transform(X_train)
visualizer.poof()
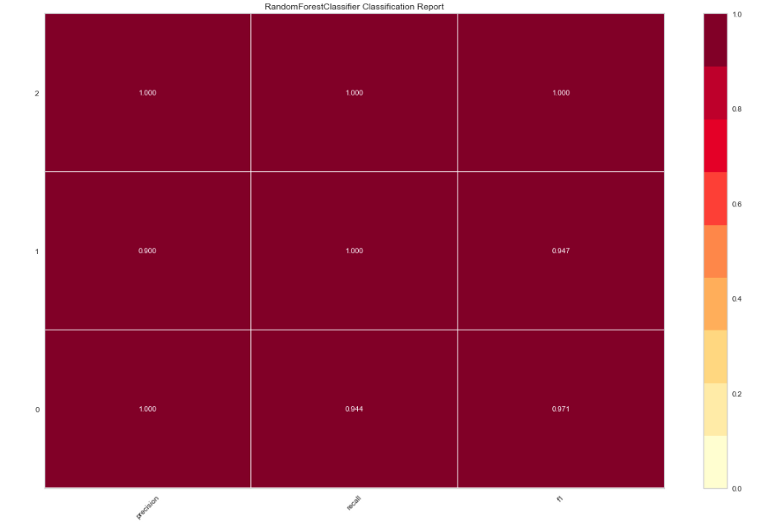
现在让我们安装一个随机森林分类器,并用另一个可视化器评估性能。
from yellowbrick.classifier import ClassificationReport
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
visualizer = ClassificationReport(model, size=(1080, 720))
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof()
ELI5
ELI5是另一个可视化库,用于调试机器学习模型并解释它们所生成的预测。它与最常见的python机器学习库一起工作,包括scikit-learn、XGBoost和Keras。
让我们使用ELI5来检查我们上面训练的模型的特性重要性。
import eli5
eli5.show_weights(model, feature_names = X.columns.tolist())
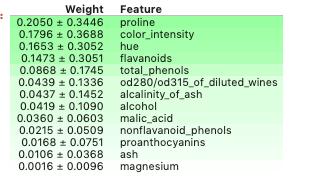
默认情况下,“显示权重”方法使用“增益”来计算权重,但可以通过添加“重要性”类型参数来指定其他类型。
您还可以使用Show_Prediction来检查单个预测的原因。
from eli5 import show_prediction
show_prediction(model, X_train.iloc[1], feature_names =
X.columns.tolist(),
show_feature_values=True)

LIME
LIME(与本地可解释模型无关的解释)是一个用来解释机器学习算法做出的预测的软件包。Lime支持从广泛的分类器中解释单个预测,并且内置了对scikit-learn的支持。
让我们使用Lime来解释我们之前训练的模型中的一些预测。
Lime可以通过pip安装。
pip install lime
首先,我们构建解释器。这将训练数据集作为一个数组、模型中使用的功能的名称以及目标变量中的类的名称。
import lime.lime_tabular
explainer = lime.lime_tabular.LimeTabularExplainer(X_train.values,
feature_names=X_train.columns.values.tolist(),
class_names=y_train.unique())
接下来,我们创建一个lambda函数,它使用模型对数据样本进行预测。这是借用了这个优秀的,更深入的Lime教程。
predict_fn = lambda x: model.predict_proba(x).astype(float)
然后,我们使用解释器对选定的示例解释预测。结果如下所示。Lime生成了一个可视化视图,显示了这些特性是如何对这个特定的预测做出贡献的。
exp = explainer.explain_instance(X_test.values[0], predict_fn,
num_features=6)
exp.show_in_notebook(show_all=False)

MLxtend
这个库包含许多机器学习的辅助函数。这包括叠加和投票分类器、模型评估、特征提取以及工程和绘图。除了文档之外,本文还提供了一个很好的资源,可以更详细地了解这个包。
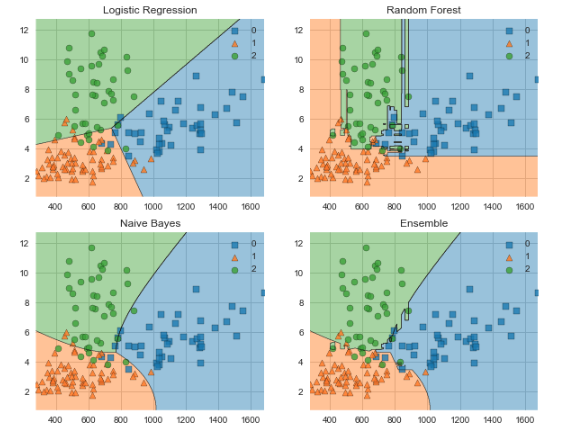
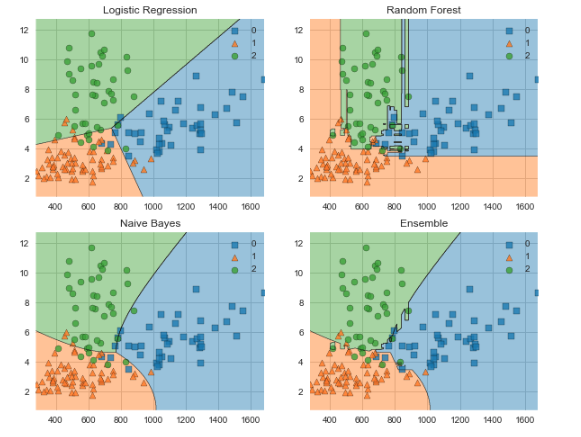
让我们使用MLxtend来比较投票分类器与其组成分类器的决策边界。
同样,它可以通过pip安装。
pip install mlxtend
我使用的导入如下所示。
from mlxtend.plotting import plot_decision_regions
from mlxtend.classifier import EnsembleVoteClassifier
import matplotlib.gridspec as gridspec
import itertoolsfrom sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
下面的可视化一次只能处理两个特性,因此我们首先创建一个包含特性proline和color_intensity的数组。我选择这些是因为它们在我们之前使用ELI5检查的所有特性中具有最高的权重。
X_train_ml = X_train[['proline', 'color_intensity']].values
y_train_ml = y_train.values
接下来,我们创建分类器,将它们与训练数据相匹配,并使用MLxtend可视化决策边界。输出如下代码所示。
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
eclf = EnsembleVoteClassifier(clfs=[clf1, clf2, clf3], weights=[1,1,1])
value=1.5
width=0.75
gs = gridspec.GridSpec(2,2)
fig = plt.figure(figsize=(10,8))
labels = ['Logistic Regression', 'Random Forest', 'Naive Bayes', 'Ensemble']
for clf, lab, grd in zip([clf1, clf2, clf3, eclf],
labels,
itertools.product([0, 1], repeat=2)):
clf.fit(X_train_ml, y_train_ml)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X_train_ml, y=y_train_ml, clf=clf)
plt.title(lab)
这绝不是一个用于解释、可视化和解释机器学习模型的库的详尽清单。但这同样也是一篇优秀的文章,因为它包含了一长串其他有用的库。感谢你的阅读!
原文链接:https://towardsdatascience.com/python-libraries-for-interpretable-machine-learning-c476a08ed2c7

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消