











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






国王-男人+女人=国王?
2019年08月04日 由 sunlei 发表
134822
0
一些最著名的例子用来解释著名的自然语言处理工具(如Word2Vec)的强大功能,但似乎只适用于一些作弊情况。
应用现代机器学习工具最重要的领域之一是自然语言处理,简称NLP。它是关于使用数字工具来分析、解释甚至生成人类(自然)语言。
可以说,最著名的算法是Word2Vec,几乎所有NLP领域的人都知道它(甚至许多对机器学习感兴趣但不从事NLP工作的人也知道)。Word2Vec已经通过几种方式实现,这使得它非常容易使用。在许多介绍性的机器学习/人工智能或NLP课程中,它经常作为一个例子被教授。
人们喜欢它的一个主要原因是它看起来很直观。最重要的是,它的名声源于一些引人注目的、建立直觉的例子,这些例子经常被用来证明Word2Vec的能力。简单解释一下Word2Vec的功能:
它会查看大量文本并计算哪些单词经常与其他单词同时出现。基于这些共现,Word2Vec为每个单词找到抽象表示,即所谓的单词嵌入。这是低维向量(想想一个包含200或300个数字的列表)。一旦你有了这些单词向量,你就可以用单词来做近乎神奇的数学运算了!如果你取King, Man, Woman的向量,你可以计算King - Man + Woman然后你会得到Queen的向量!
[caption id="attachment_42567" align="aligncenter" width="770"] 我非常推荐使用word vector !这很有趣,您可以找到大量预先训练好的网络,因此您可以立即开始使用。试试向量计算器这个词。如果你想自己做一些关于鸡尾酒书籍的培训,我强烈推荐戴夫·阿诺德(Dave Arnold)的《液体智能》(Liquid Intelligence) (在单词embeddings中可能是: cocktails — fuzz + linear_algebra)。由Florian Huber制作的卡通,由4.0版CC授权。(意思是:如果你不介意我有限的绘画技巧,可以随意分享或重复使用它)。[/caption]
我非常推荐使用word vector !这很有趣,您可以找到大量预先训练好的网络,因此您可以立即开始使用。试试向量计算器这个词。如果你想自己做一些关于鸡尾酒书籍的培训,我强烈推荐戴夫·阿诺德(Dave Arnold)的《液体智能》(Liquid Intelligence) (在单词embeddings中可能是: cocktails — fuzz + linear_algebra)。由Florian Huber制作的卡通,由4.0版CC授权。(意思是:如果你不介意我有限的绘画技巧,可以随意分享或重复使用它)。[/caption]
哇。国王-男人+女人=王后!
这太神奇了。因此,算法了解了这些词的含义。它有点理解他们。至少看起来是这样…
问题是,在我看来,将Word2Vec简化为这个最重要的示例是一个巨大的错误。对我(我也相信许多其他人)来说,这是非常误导人的。

需要说明的是:算法本身没有任何问题!它在概念上非常有趣,在很多情况下都非常有效。如果处理得当,它可以很好地表示单词的相似性或意义。但是“国王-男人+女人=王后”的例子远远夸大了算法的实际能力。
下面是我认为我们应该停止使用经典例子来介绍Word2Vec的一些原因:
1、事实证明,为了让这个例子在第一个地方起作用,你必须包括一些“欺骗”。实际的结果就是国王-男人+女人=国王。因此,得到的向量更像King而不是Queen。这个广为人知的例子之所以能够成功,是因为算法的实现会将原始向量排除在可能的结果之外!也就是说,向量表示国王-男人+女人与向量表示国王最接近。第二名是王后,这是常规选择。很令人失望,不是吗?
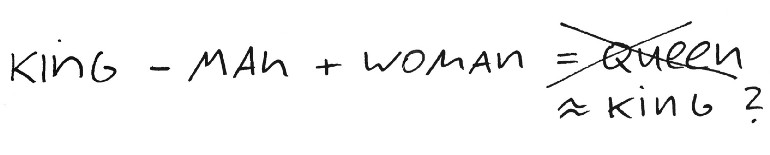
在我看过的许多课程和教程中,都没有提到这个问题。因此,我认为这仍然不是常识。实际上,只有在一个较好的在线NLP课程中,我才最终了解到这个令人失望的“技巧”(关于NLP的HSE课程,值得一看!)
最近,格罗宁根大学(University of Groningen)的三位研究人员对一些关键的Word2Vec出版物中给出的例子进行了测试。虽然有些示例确实如预期的那样工作,但令人沮丧的是,只有在使用不允许查询词本身的小“技巧”时,给定的示例才真正工作(参见:[Nissim 2019])。
[caption id="attachment_42570" align="aligncenter" width="770"]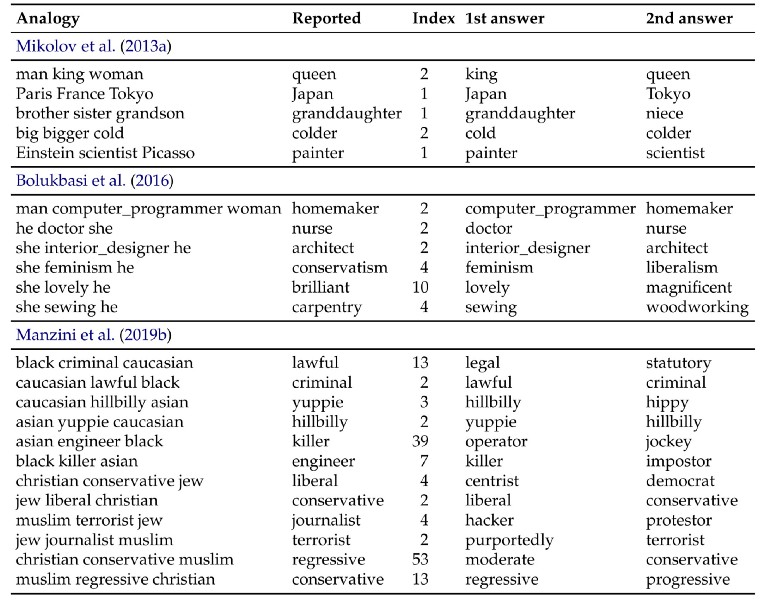 表取自Nissim (2019):https://arxiv.org/abs/1905.09866。作者使用Word2Vec测试了一些关键文章中的类比例子。他们对B执行了一个C类型的查询,就像A to X一样。“Index”表示报告的答案(“report”)实际表示的位置(通常不是“1”!)此外,算法给出的第一个和第二个答案显示在右边的两列中。[/caption]
表取自Nissim (2019):https://arxiv.org/abs/1905.09866。作者使用Word2Vec测试了一些关键文章中的类比例子。他们对B执行了一个C类型的查询,就像A to X一样。“Index”表示报告的答案(“report”)实际表示的位置(通常不是“1”!)此外,算法给出的第一个和第二个答案显示在右边的两列中。[/caption]
2、不幸的是,事情变得更糟了。
Finley等[2017]对男性-女性/国王-王后/男性-女性以外的类比进行了更深入的分析。他们对大量的句法和语义类比进行了评估,发现基于单词嵌入(即单词向量)的计算在某些类型的类比中表现得很好,但在其他类型的类比中却表现得很差。在“词汇语义”这一类别中,这些算法的表现似乎特别糟糕……有一个非常显著的例外:男性与女性的类比!因此,在某种程度上,这些典型的课堂或教程中的例子与其说是规则,不如说是例外(参见[Finley 2017])。
3、当谈到超越这一个闪亮的例子并比较生成嵌入词的不同方法时,人们通常会比较大文本语料库中的方法准确性。即使在这里,事情似乎也比通常所说的要复杂。一些有趣的研究(参见[Levy 等,2016])清楚地表明,在比较不同的算法时,我们需要非常谨慎。这包括Word2Vec。
通常,“新”方法会针对测试数据集进行优化,以便更好地执行。然后将其与“旧的”方法进行比较,这很好。只是这些针对各自数据集的优化程度要低得多。如果处理得当,结果往往不那么令人信服,而且在许多情况下表明,旧方法(处理得当)与新方法之间的差异非常小(参见[Levy 2016]、[Levy 2014])。
所有这些告诉我两件事:
在比较一个或几个特定数据集上使用基准测试的方法时要小心。这远远超出了这个Word2Vec示例!
停止将Word2Vec简化为“King - Man + Woman = Queen”的例子。它造成不切实际的高期望。事实上,如果不作弊的话,它甚至都不能工作。
→链接到HSE/Coursera NLP课程。
→链接到国王-男人-女人-王后示例课程的视频。
→链接到他们的GitHub库。
附注:在这篇文章中,我主要写的是Word2Vec(或非常相关的算法)。但是,考虑到上面列出的问题的严重性,我也希望许多其他流行词嵌入也能发现同样的问题。这当然值得一试。
应用现代机器学习工具最重要的领域之一是自然语言处理,简称NLP。它是关于使用数字工具来分析、解释甚至生成人类(自然)语言。
可以说,最著名的算法是Word2Vec,几乎所有NLP领域的人都知道它(甚至许多对机器学习感兴趣但不从事NLP工作的人也知道)。Word2Vec已经通过几种方式实现,这使得它非常容易使用。在许多介绍性的机器学习/人工智能或NLP课程中,它经常作为一个例子被教授。
人们喜欢它的一个主要原因是它看起来很直观。最重要的是,它的名声源于一些引人注目的、建立直觉的例子,这些例子经常被用来证明Word2Vec的能力。简单解释一下Word2Vec的功能:
它会查看大量文本并计算哪些单词经常与其他单词同时出现。基于这些共现,Word2Vec为每个单词找到抽象表示,即所谓的单词嵌入。这是低维向量(想想一个包含200或300个数字的列表)。一旦你有了这些单词向量,你就可以用单词来做近乎神奇的数学运算了!如果你取King, Man, Woman的向量,你可以计算King - Man + Woman然后你会得到Queen的向量!
[caption id="attachment_42567" align="aligncenter" width="770"]
我非常推荐使用word vector !这很有趣,您可以找到大量预先训练好的网络,因此您可以立即开始使用。试试向量计算器这个词。如果你想自己做一些关于鸡尾酒书籍的培训,我强烈推荐戴夫·阿诺德(Dave Arnold)的《液体智能》(Liquid Intelligence) (在单词embeddings中可能是: cocktails — fuzz + linear_algebra)。由Florian Huber制作的卡通,由4.0版CC授权。(意思是:如果你不介意我有限的绘画技巧,可以随意分享或重复使用它)。[/caption]哇。国王-男人+女人=王后!
这太神奇了。因此,算法了解了这些词的含义。它有点理解他们。至少看起来是这样…
问题是,在我看来,将Word2Vec简化为这个最重要的示例是一个巨大的错误。对我(我也相信许多其他人)来说,这是非常误导人的。
需要说明的是:算法本身没有任何问题!它在概念上非常有趣,在很多情况下都非常有效。如果处理得当,它可以很好地表示单词的相似性或意义。但是“国王-男人+女人=王后”的例子远远夸大了算法的实际能力。
下面是我认为我们应该停止使用经典例子来介绍Word2Vec的一些原因:
1、事实证明,为了让这个例子在第一个地方起作用,你必须包括一些“欺骗”。实际的结果就是国王-男人+女人=国王。因此,得到的向量更像King而不是Queen。这个广为人知的例子之所以能够成功,是因为算法的实现会将原始向量排除在可能的结果之外!也就是说,向量表示国王-男人+女人与向量表示国王最接近。第二名是王后,这是常规选择。很令人失望,不是吗?
在我看过的许多课程和教程中,都没有提到这个问题。因此,我认为这仍然不是常识。实际上,只有在一个较好的在线NLP课程中,我才最终了解到这个令人失望的“技巧”(关于NLP的HSE课程,值得一看!)
最近,格罗宁根大学(University of Groningen)的三位研究人员对一些关键的Word2Vec出版物中给出的例子进行了测试。虽然有些示例确实如预期的那样工作,但令人沮丧的是,只有在使用不允许查询词本身的小“技巧”时,给定的示例才真正工作(参见:[Nissim 2019])。
[caption id="attachment_42570" align="aligncenter" width="770"]
表取自Nissim (2019):https://arxiv.org/abs/1905.09866。作者使用Word2Vec测试了一些关键文章中的类比例子。他们对B执行了一个C类型的查询,就像A to X一样。“Index”表示报告的答案(“report”)实际表示的位置(通常不是“1”!)此外,算法给出的第一个和第二个答案显示在右边的两列中。[/caption]2、不幸的是,事情变得更糟了。
Finley等[2017]对男性-女性/国王-王后/男性-女性以外的类比进行了更深入的分析。他们对大量的句法和语义类比进行了评估,发现基于单词嵌入(即单词向量)的计算在某些类型的类比中表现得很好,但在其他类型的类比中却表现得很差。在“词汇语义”这一类别中,这些算法的表现似乎特别糟糕……有一个非常显著的例外:男性与女性的类比!因此,在某种程度上,这些典型的课堂或教程中的例子与其说是规则,不如说是例外(参见[Finley 2017])。
3、当谈到超越这一个闪亮的例子并比较生成嵌入词的不同方法时,人们通常会比较大文本语料库中的方法准确性。即使在这里,事情似乎也比通常所说的要复杂。一些有趣的研究(参见[Levy 等,2016])清楚地表明,在比较不同的算法时,我们需要非常谨慎。这包括Word2Vec。
通常,“新”方法会针对测试数据集进行优化,以便更好地执行。然后将其与“旧的”方法进行比较,这很好。只是这些针对各自数据集的优化程度要低得多。如果处理得当,结果往往不那么令人信服,而且在许多情况下表明,旧方法(处理得当)与新方法之间的差异非常小(参见[Levy 2016]、[Levy 2014])。
所有这些告诉我两件事:
在比较一个或几个特定数据集上使用基准测试的方法时要小心。这远远超出了这个Word2Vec示例!
停止将Word2Vec简化为“King - Man + Woman = Queen”的例子。它造成不切实际的高期望。事实上,如果不作弊的话,它甚至都不能工作。
资源:
- 1、关于NLP的非常好的免费在线课程由莫斯科的HSE完成,可以在Coursera上找到。这显然是我见过的更好的NLP课程之一,它也使Word2Vec非常清晰。
→链接到HSE/Coursera NLP课程。
→链接到国王-男人-女人-王后示例课程的视频。
→链接到他们的GitHub库。
- 2、想玩一些单词嵌入吗?有很多预先训练好的,随时可用的东西。例如,试试这个语义计算器。您可以在谷歌新闻、英语维基百科和其他网站上训练的不同模型中进行选择。玩起来很有趣,第一眼看到它能做什么和不能做什么也很好。
- 1)Nissim, van Noord, van der Goot (2019):公平胜过耸人听闻:男人之于医生,犹如女人之于医生
- 2)Levy, Goldberg, Dagan(2016):改进分布相似性从单词嵌入中学到的经验教训。
- 3)Levy和Goldberg(2014):神经词嵌入作为隐式矩阵分解。
- 4)Finley, Farmer, Pakhomov(2017):类比揭示了单词向量及其组成。
附注:在这篇文章中,我主要写的是Word2Vec(或非常相关的算法)。但是,考虑到上面列出的问题的严重性,我也希望许多其他流行词嵌入也能发现同样的问题。这当然值得一试。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消