











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






深入探索Catboost模型可解释性(上)
2019年07月15日 由 sunlei 发表
68062
0

我曾经的文章中,写到了XGBoost、LightGBM和Catboost的对比研究。通过分析,我们可以得出结论,catboost在速度和准确度方面都优于其他两家公司。在今天这个部分中,我们将深入研究catboost,探索catboost为高效建模和理解超参数提供的新特性。
对于新读者来说,catboost是Yandex团队在2017年开发的一款开源梯度增强算法。它是一种机器学习算法,允许用户快速处理大数据集的分类特征,这与XGBoost和LightGBM不同。Catboost可以用来解决回归、分类和排序问题。
作为数据科学家,我们可以很容易地训练模型并做出预测,但是,我们往往无法理解这些花哨的算法中发生了什么。这也是我们看到模型性能在离线评估和最终生产之间存在巨大差异的原因之一。我们应该停止将ML作为一个“黑匣子”,在提高模型精度的同时重视模型解释。这也将帮助我们识别数据偏差。在这一部分中,我们将看到catboost如何通过以下功能帮助我们分析模型并提高可视性:
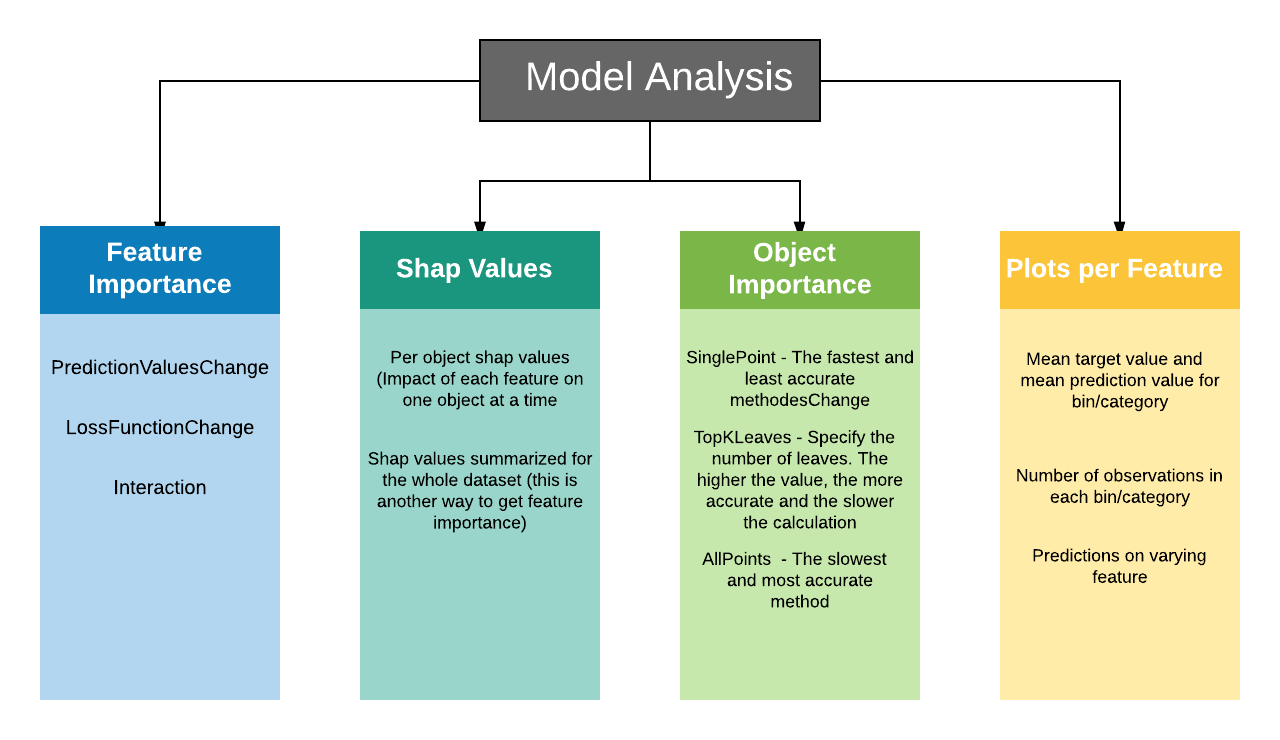
功能的重要性
你为什么要知道?
-删除不必要的功能,简化模型,减少训练/预测时间
-为你的目标价值获取最具影响力的功能,并对其进行操作,以获得商业收益(例如:医疗保健提供者想要确定是什么因素在驱动每个病人患某些疾病的风险,以便他们可以直接使用目标药物解决这些风险因素)
除了选择功能重要性的类型之外,我们还应该知道我们想要使用哪些数据来寻找特性重要性——训练、测试或完整数据集。选择一个特性比选择另一个特性有优缺点,但最终,您需要决定您是想知道模型在多大程度上依赖于每个特性来进行预测(使用训练数据),还是该特性对模型在未知数据(使用测试数据)上的性能有多大贡献。稍后我们将在这个文章中看到,只有一些方法可以用来发现不用于训练模型的数据的功能重要性。
如果您关心第二个,并且假设您拥有所有的时间和资源,那么找到特性重要性的最关键和最可靠的方法就是训练多个模型,一次只留下一个特性,并比较测试集的性能。如果性能相对于基线变化很大(使用所有特性时的性能),这意味着特性很重要。但由于我们生活在一个既需要优化精度又需要优化计算时间的现实世界中,这种方法是不必要的。以下是CatBoost让您为您的模型找到最佳功能的几种智能方法:
cb = CatBoostRegressor()
cb.get_feature_importance(type= "___")
"type" possible values:
- PredictionValuesChange
- LossFunctionChange
- FeatureImportance
PredictionValuesChange for non-ranking metrics and LossFunctionChange for ranking metrics
- ShapValues
Calculate SHAP Values for every object
- Interaction
Calculate pairwise score between every feature
预测值更改
对于每个功能,PredictionValuesChange显示如果功能值更改,预测平均会更改多少。重要性值越大,如果该特性发生变化,则预测值的变化平均越大。
优点:计算成本很低,因为您不必进行多次训练或测试,也不会存储任何额外的信息。您将得到作为输出的标准化值(所有导入项加起来将达100)。
缺点:它可能会给排名目标带来误导性的结果,它可能会把群体特征放在首位,即使它们对所产生的损失价值有一点影响。
失去功能改变
为了获得这一特性的重要性,CatBoost简单地利用了在正常情况下(当我们包括特性时)使用模型获得的度量(损失函数)与不使用该特性的模型(模型建立大约与此功能从所有的树在合奏)。差别越大,特征就越重要。在CatBoost文档中没有明确提到我们如何发现没有特性的模型。
优点和缺点:这对于大多数类型的问题都很有效,不像PredictionValuesChange那样,在对问题进行排序时可能会得到误导的结果,同时它的计算量很大。
Shap Values
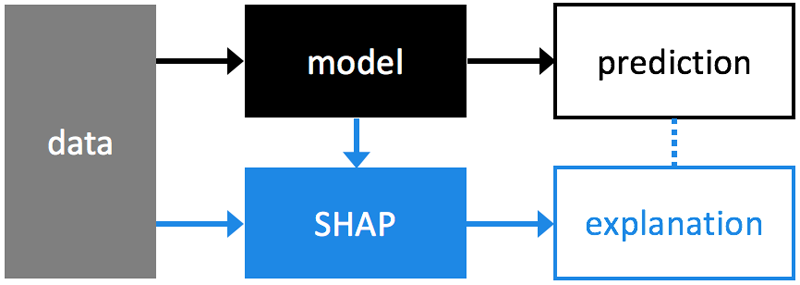
SHAP值将预测值分解为每个特性的贡献。它比较基线预测(训练数据集目标值的平均值)和特征对单个预测值的影响。
shap值的两个主要用例:
1. 特性的对象级贡献
shap_values = model.get_feature_importance(Pool(X_test, label=y_test,cat_features=categorical_features_indices),
type="ShapValues")
expected_value = shap_values[0,-1]
shap_values = shap_values[:,:-1]
shap.initjs()
shap.force_plot(expected_value, shap_values[3,:], X_test.iloc[3,:])

https://github.com/slundberg/shap
2. 整个数据集的摘要(总体特性重要性)
shap.summary_plot(shap_values, X_test)
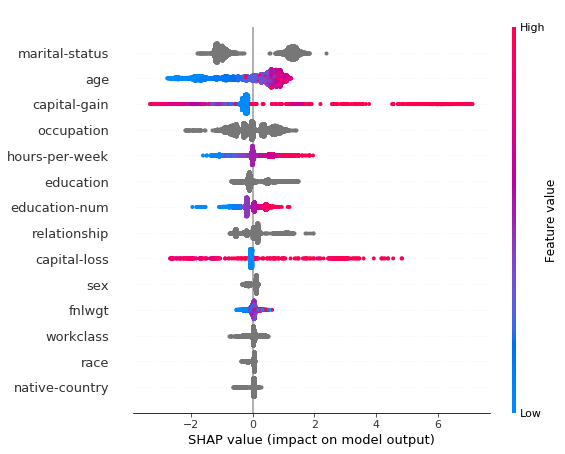
虽然我们可以通过shap获得精确的特性重要性,但是它们在计算上比catboost内置的特性重要性更昂贵。有关SHAP值的更多细节,请阅读这个核心要点。
奖金
另一个基于相同概念但实现不同的特性重要性是基于排列的特性重要性。虽然catboost没有使用这种方法,但它与模型无关,并且易于计算。
我们怎么选择呢?
虽然这两种方法都可以用于所有类型的度量,但是建议使用LossFunctionChangefor对度量进行排序。除了PredictionValuesChange之外,所有其他方法都可以使用测试数据,使用训练在列车数据上的模型来发现特征的重要性。
为了更好地理解这些差异,下面是我们讨论的所有方法的结果:
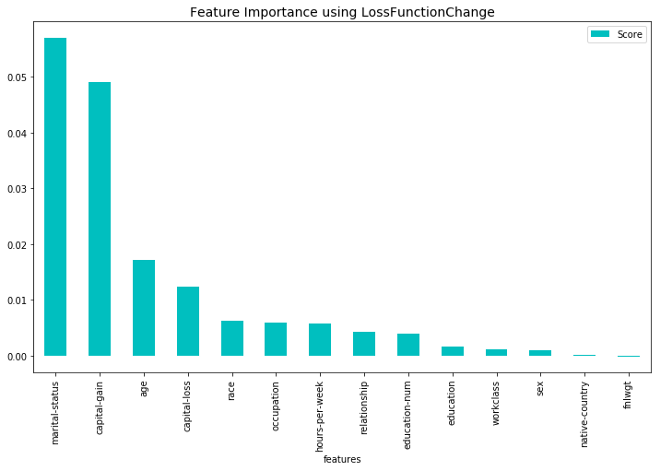
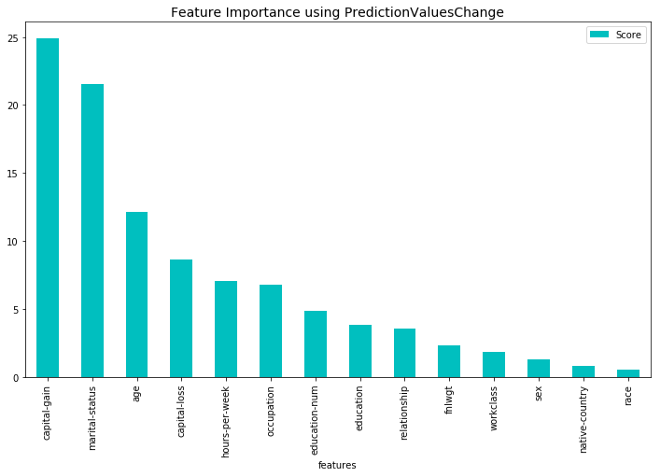
CatBoost功能IMP.的结果预测-报告来自经典“成人”人口普查数据集,人们是否会有超过5万美元的收入(使用日志丢失)。
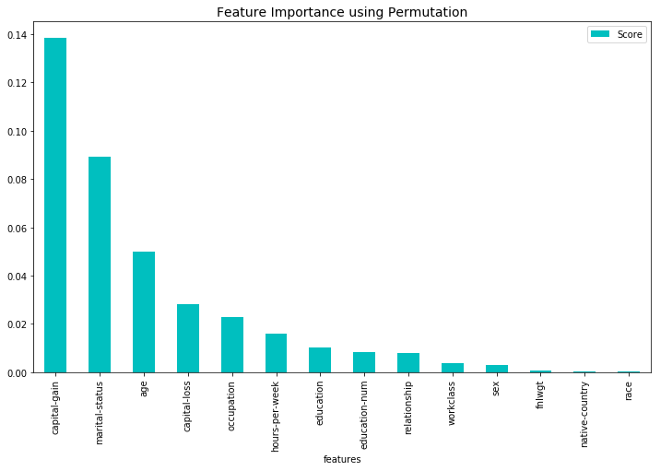
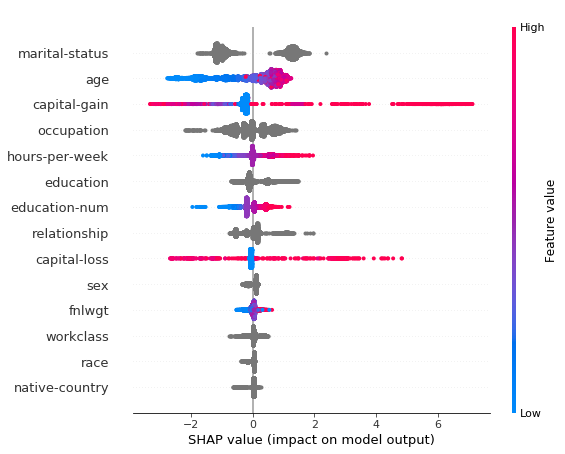
从上面的图中,我们可以看到,大多数方法在顶级特性上是一致的。看起来lossFunctionChange最接近shap(更可靠)。然而,直接比较这些方法是不公平的,因为预测值变化是基于列车数据,而其他所有方法都是基于试验数据。
我们还应该看到运行所有这些程序所需的时间:
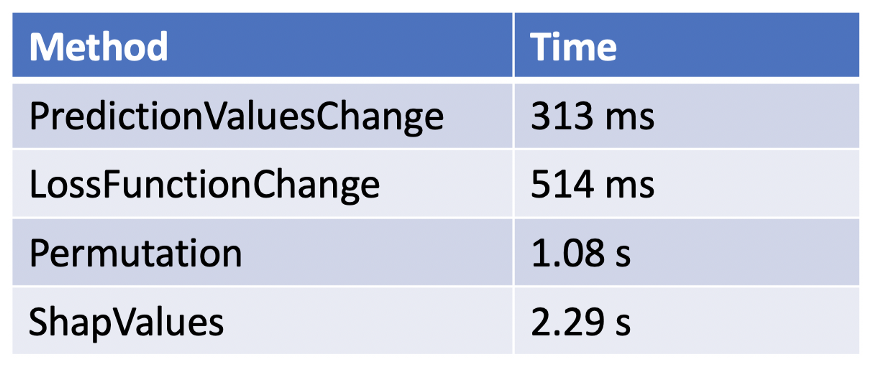
在今天的内容中,我们看到catboost如何通过以上功能帮助我们分析模型,明天我们将继续更新,希望能帮助你更好地使用这些工具去开发模型。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消