











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






自然语言处理:从基础到RNN和LSTM(下)
2019年07月11日 由 sunlei 发表
381554
0
昨天我们聊了一些自然语言处理的基本原理,比如“自然语言是什么”“计算机如何理解语言”“什么是自然语言处理”等等问题,在本文中我们将更深一步探讨自然语言处理取得了怎样的快速进展。
传送门:自然语言处理:从基础到RNN和LSTM(上)
对于一个算法来推导文本数据之间的关系,它需要以一种清晰的结构化格式来表示。
词袋是一种以表格格式表示数据的方法,其中列表示语料库的总词汇表,每一行表示单个观察。单元格(行和列的交集)表示在该特定观察中由列表示的单词数。
它有助于机器理解一个简单易懂的矩阵范例中的句子,从而使各种线性代数运算和其他算法能够应用到数据上,以建立预测模型。
以下是医学期刊文章样本的“词袋模型”示例
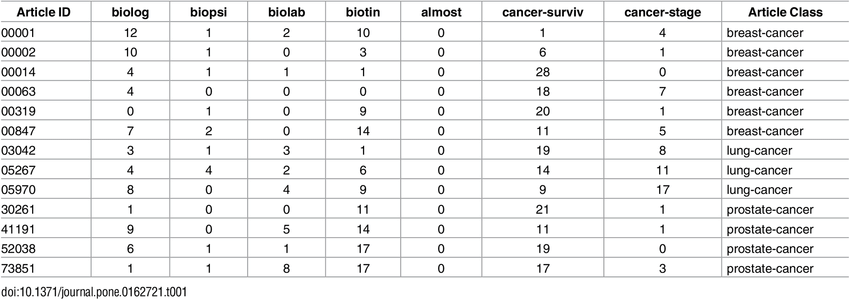
这种表示非常有效,并负责为一些最常用的机器学习任务(如垃圾邮件检测、情绪分类器和其他任务)生成模型。
然而,这种表述有两个主要缺点:
嵌入矩阵是一种表示词汇表中每个单词的嵌入的方法。行表示单词嵌入空间的维度,列表示词汇表中的单词。
为了将一个样本转换成它的嵌入形式,将其独热编码形式中的每个单词乘以嵌入矩阵,为样本提供单词嵌入。
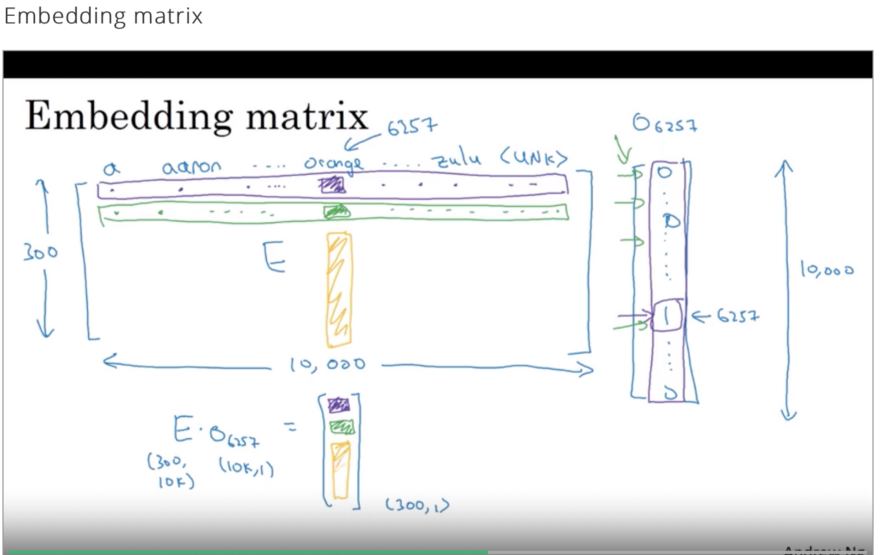
需要记住的一件事是,这里的One -hot编码仅仅是指在词汇表中单词位置处值为1的n维向量,其中n是词汇表的长度。这些热编码来自词汇表,而不是从一批观察结果中提取的。
递归神经网络简称RNN,是神经网络的重要变体,在自然语言处理中得到了广泛的应用。
从概念上讲,它们与标准神经网络不同,因为RNN中的标准输入是一个单词,而不是标准神经网络中的整个样本。这使得网络能够灵活地处理不同长度的句子,而标准的神经网络由于其固定的结构而无法做到这一点。它还提供了一个额外的优势,可以共享在不同文本位置学习到的特征,而这些特征在标准的神经网络中是无法获得的。
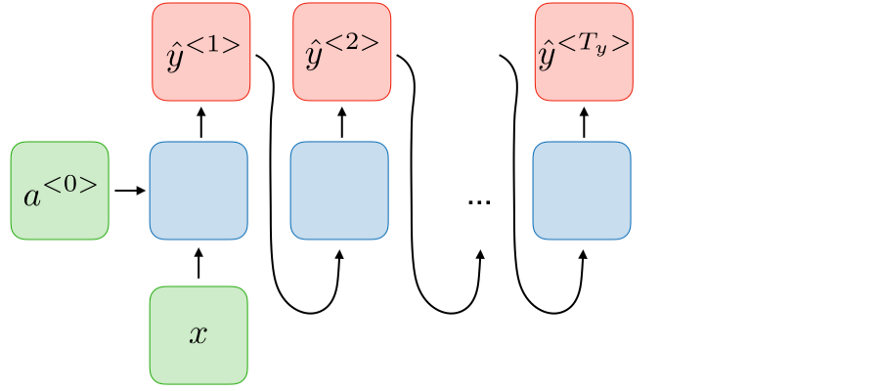
RNN将句子中的每个单词视为时间“t”发生的单独输入,并使用“t-1”处的激活值,作为时间“t”处输入之外的输入。下图显示了RNN体系结构的详细结构。
上面描述的架构也称为多对多架构(Tx = Ty),即输入的数量=输出的数量。这种结构在序列建模中非常有用。
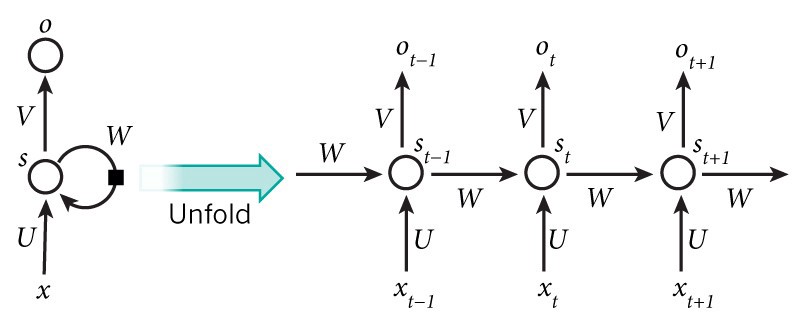
除了上述结构外,还有三种常用的RNN结构。
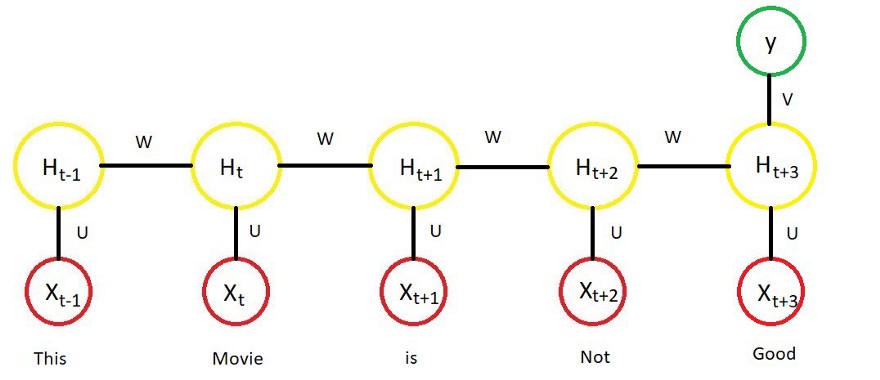
上图中,H代表激活功能的输出。
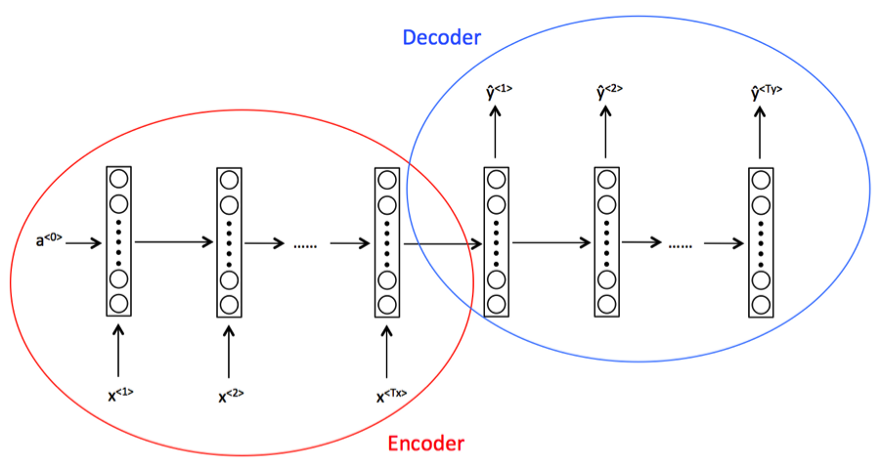
编码器是指网络中读取要翻译的句子的部分,解码器是网络中将句子翻译成所需语言的部分。
RNN除了有用之外,也有一定的局限性,主要有:
这两种限制导致了新型的RNN体系结构,下面将对此进行讨论。
它是对基本递归单元的一种改进,有助于捕获长期依赖关系,也有助于解决消失梯度问题。
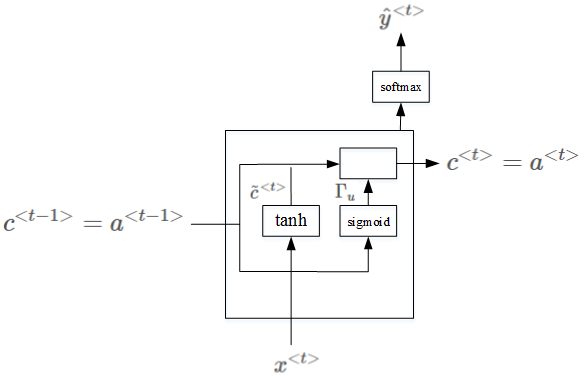
GRU由一个额外的内存单元组成,通常称为更新门或重置门。除了通常的具有sigmoid函数和softmax输出的神经单元外,它还包含一个额外的单元,其中tanh作为激活函数。使用TANH是因为它的输出可以是正的也可以是负的,因此可以用于向上和向下伸缩。然后,该单元的输出与激活输入相结合,以更新内存单元的值。
因此,在每个步骤中,隐藏单元和内存单元的值都会被更新。内存单元中的值在决定传递给下一个单元的激活值时起作用。
要获得更详细的解释,可以参考https://towardsdatascience.com/ing-gru-networks-2ef37df6c9be
在LSTM体系结构中,没有像GRU那样只有一个更新门,而是有一个更新门和一个忘记门。
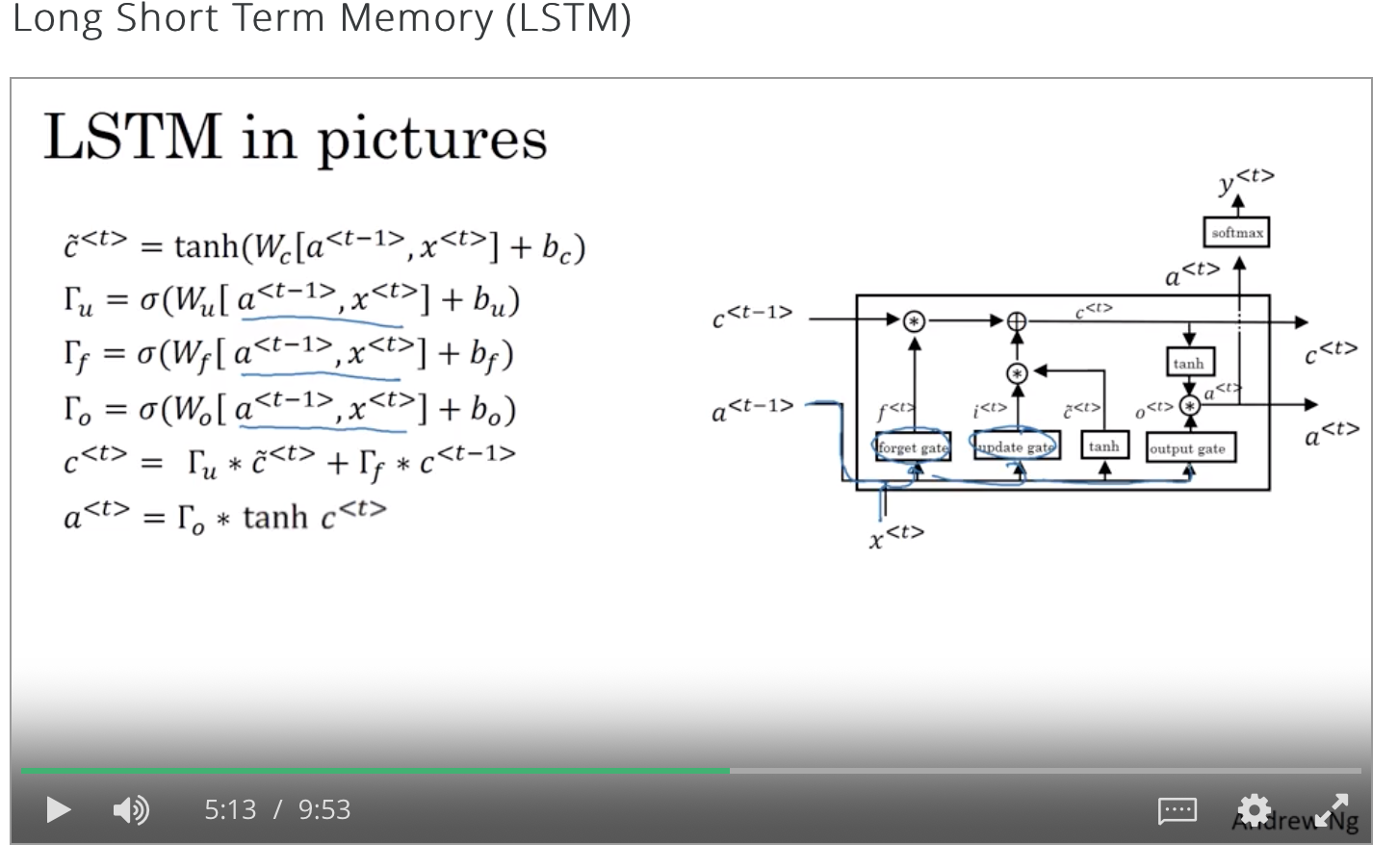
这种体系结构为内存单元提供了一个选项,可以保留t-1时刻的旧值,并将t时刻向其添加值。
关于LSTM的更详细的解释,请访问http://colah.github.io/posts/2015-08-explanation - lstms/
在上述RNN体系结构中,仅考虑以前时间戳出现的影响。在NLP的情况下,这意味着它考虑了只写在当前单词之前的单词的影响。但在语言结构中,情况并非如此,因此双向RNN出现起到了拯救作用。
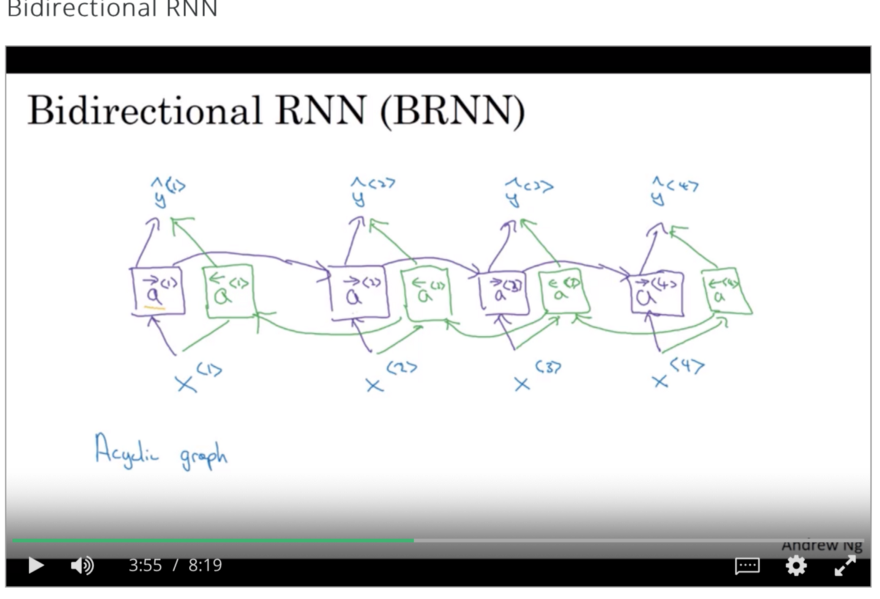
双向RNN由前向和后向递归神经网络组成,并结合两个网络在任意给定时间t的结果进行最终预测,如图所示。
在这篇文章中,我试图涵盖自然语言处理领域中普遍存在的所有相关实践和神经网络架构。对于那些对深入了解神经网络感兴趣的人,我强烈建议你们去上Andrew Ng Coursera的课程。
传送门:自然语言处理:从基础到RNN和LSTM(上)
表示方法
Bag of Words词袋
对于一个算法来推导文本数据之间的关系,它需要以一种清晰的结构化格式来表示。
词袋是一种以表格格式表示数据的方法,其中列表示语料库的总词汇表,每一行表示单个观察。单元格(行和列的交集)表示在该特定观察中由列表示的单词数。
它有助于机器理解一个简单易懂的矩阵范例中的句子,从而使各种线性代数运算和其他算法能够应用到数据上,以建立预测模型。
以下是医学期刊文章样本的“词袋模型”示例
这种表示非常有效,并负责为一些最常用的机器学习任务(如垃圾邮件检测、情绪分类器和其他任务)生成模型。
然而,这种表述有两个主要缺点:
- 它忽略了文本的顺序/语法,从而放松了使用单词的上下文。
- 由这种表示生成的矩阵非常稀疏,并且更偏向于最常见的单词。想想看,算法主要是计算单词的数量,而在语言中,单词的重要性实际上与出现的频率成反比。频率较高的词是比较普通的词,如the,is,an,它不会显著改变句子的意思。因此,适当地权衡单词以反映它们对一个句子的意义有足够的影响。
嵌入矩阵
嵌入矩阵是一种表示词汇表中每个单词的嵌入的方法。行表示单词嵌入空间的维度,列表示词汇表中的单词。
为了将一个样本转换成它的嵌入形式,将其独热编码形式中的每个单词乘以嵌入矩阵,为样本提供单词嵌入。
需要记住的一件事是,这里的One -hot编码仅仅是指在词汇表中单词位置处值为1的n维向量,其中n是词汇表的长度。这些热编码来自词汇表,而不是从一批观察结果中提取的。
循环神经网络(RNN)
递归神经网络简称RNN,是神经网络的重要变体,在自然语言处理中得到了广泛的应用。
从概念上讲,它们与标准神经网络不同,因为RNN中的标准输入是一个单词,而不是标准神经网络中的整个样本。这使得网络能够灵活地处理不同长度的句子,而标准的神经网络由于其固定的结构而无法做到这一点。它还提供了一个额外的优势,可以共享在不同文本位置学习到的特征,而这些特征在标准的神经网络中是无法获得的。
RNN将句子中的每个单词视为时间“t”发生的单独输入,并使用“t-1”处的激活值,作为时间“t”处输入之外的输入。下图显示了RNN体系结构的详细结构。
上面描述的架构也称为多对多架构(Tx = Ty),即输入的数量=输出的数量。这种结构在序列建模中非常有用。
除了上述结构外,还有三种常用的RNN结构。
- 多对一RNN:多对一体系结构是指使用多个输入(Tx)来给出一个输出(Ty)的RNN体系结构。使用这种体系结构的一个合适的例子是分类任务。
上图中,H代表激活功能的输出。
- 一对多RNN:一对多体系结构是指RNN基于单个输入值生成一系列输出值的情况。使用这种结构的一个主要例子是音乐生成任务,其中输入是一个jounre或第一个音符。
- 多对多体系结构(Tx不等于Ty):该体系结构指的是读取多个输入以产生多个输出,其中输入长度不等于输出长度。使用这种体系结构的一个主要示例是机器翻译任务。
编码器是指网络中读取要翻译的句子的部分,解码器是网络中将句子翻译成所需语言的部分。
RNN的局限性
RNN除了有用之外,也有一定的局限性,主要有:
- 上面所述的RNN体系结构示例只能够捕获语言的一个方向上的依赖关系。基本上在自然语言处理的情况下,它假设后面的单词对前面的单词没有影响。根据我们对语言的经验,我们知道这肯定不是真的。
- RNN也不能很好地捕捉长期依赖关系,梯度消失的问题在RNN中重新出现。
这两种限制导致了新型的RNN体系结构,下面将对此进行讨论。
GRU(Gated Recurrent Unit)
它是对基本递归单元的一种改进,有助于捕获长期依赖关系,也有助于解决消失梯度问题。
GRU由一个额外的内存单元组成,通常称为更新门或重置门。除了通常的具有sigmoid函数和softmax输出的神经单元外,它还包含一个额外的单元,其中tanh作为激活函数。使用TANH是因为它的输出可以是正的也可以是负的,因此可以用于向上和向下伸缩。然后,该单元的输出与激活输入相结合,以更新内存单元的值。
因此,在每个步骤中,隐藏单元和内存单元的值都会被更新。内存单元中的值在决定传递给下一个单元的激活值时起作用。
要获得更详细的解释,可以参考https://towardsdatascience.com/ing-gru-networks-2ef37df6c9be
LSTM
在LSTM体系结构中,没有像GRU那样只有一个更新门,而是有一个更新门和一个忘记门。
这种体系结构为内存单元提供了一个选项,可以保留t-1时刻的旧值,并将t时刻向其添加值。
关于LSTM的更详细的解释,请访问http://colah.github.io/posts/2015-08-explanation - lstms/
双向RNN
在上述RNN体系结构中,仅考虑以前时间戳出现的影响。在NLP的情况下,这意味着它考虑了只写在当前单词之前的单词的影响。但在语言结构中,情况并非如此,因此双向RNN出现起到了拯救作用。
双向RNN由前向和后向递归神经网络组成,并结合两个网络在任意给定时间t的结果进行最终预测,如图所示。
在这篇文章中,我试图涵盖自然语言处理领域中普遍存在的所有相关实践和神经网络架构。对于那些对深入了解神经网络感兴趣的人,我强烈建议你们去上Andrew Ng Coursera的课程。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消