











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Boosting算法大比拼:XGBoost vs. LightGBM vs. Catboost
2019年07月09日 由 sunlei 发表
815250
0

目标
我们要做什么?
我们将让XGBoost、LightGBM和Catboost在3轮内完成战斗:
- 分类:在时尚MNIST中对图片进行分类(60000行,784个特征)
- 回归:预测纽约市出租车价格(6万行,7个特征)
- 海量数据集:预测纽约市出租车价格(200万行,7大特色)
我们要怎么做?
在每一轮中,我们将遵循以下步骤:
XGBoost、Catboost、LightGBM的训练基线模型(每个模型使用相同的参数训练)
使用GridSearchCV训练XGBoost、Catboost、LightGBM的微调模型
根据以下指标衡量工作绩效:
- 培训及预测时间
- 预测分数
- 可解释性(特性重要性、shap值、可视化树)
代码
您可以在这里找到随附的代码。
调查结果
让我们从最重要的发现开始。
研究结果
让我们从最重要的发现开始。
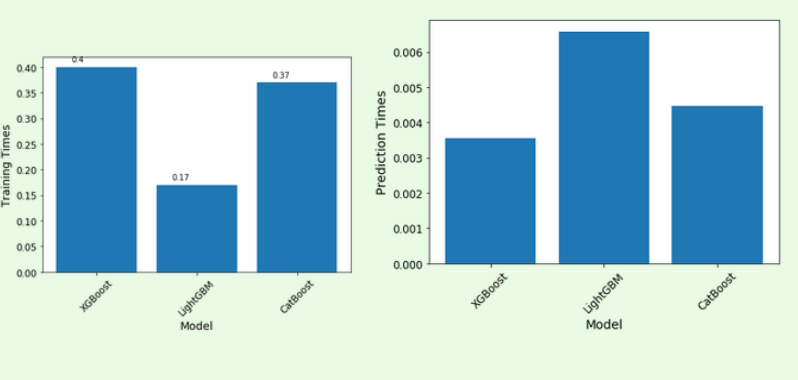
1.运行时间和准确度得分
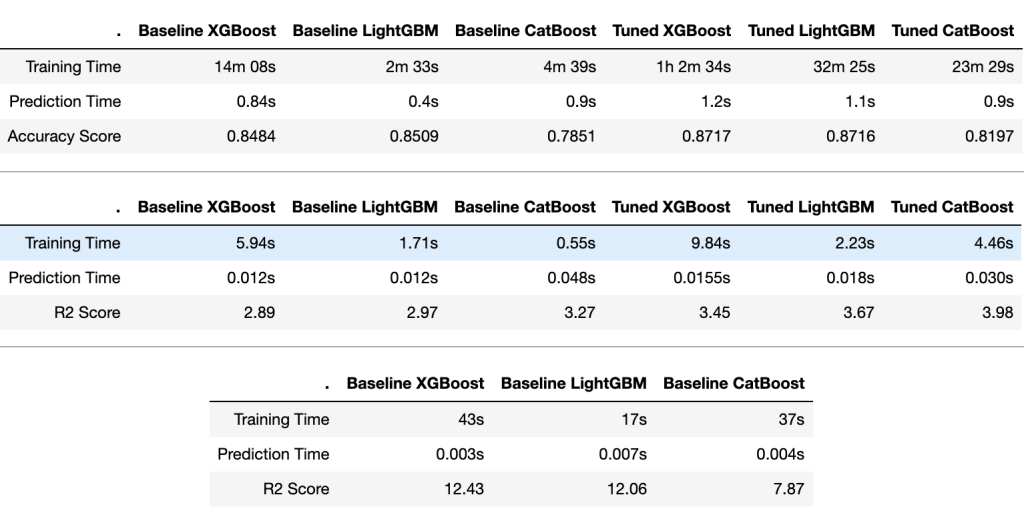
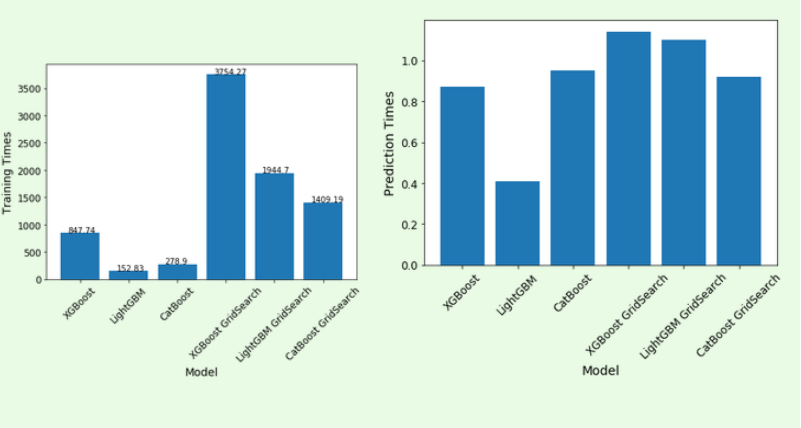
LightGBM在训练和预测时间上都是明显的赢家,而CatBoost则略微落后。XGBoost花了更多的时间来训练,但是有合理的预测时间。(在增强树中进行培训的时间复杂度介于(log)和(2),和预测是(log2);=数量的训练例子,=数量的特性,和=决策树的深度)。
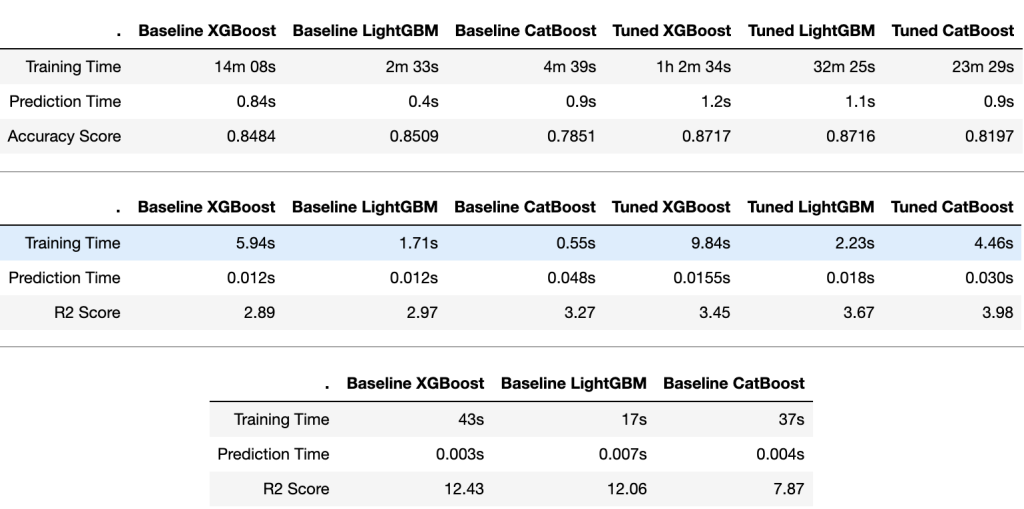
Classification Challenge分类挑战
Regression Challenge回归挑战
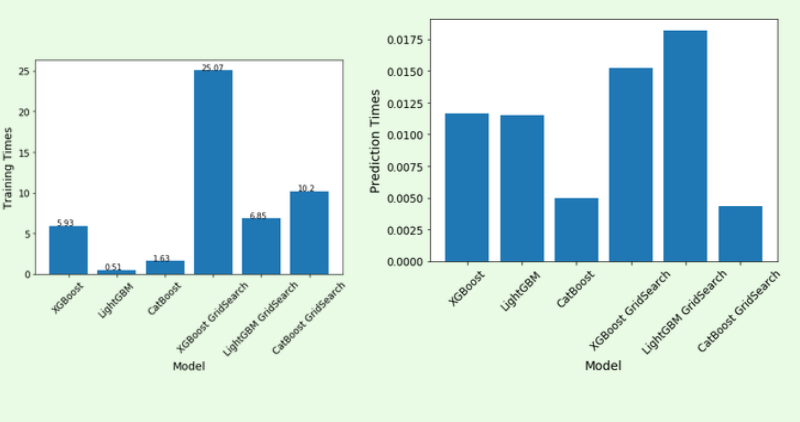
Massive Dataset Challenge海量数据集挑战
2. 可解释性
一个模型的预测分数只能描绘出其预测的部分图景。我们还想知道为什么模型会做出预测。
在这里,我们绘制模型的特征重要性,SHAP值,并绘制一个实际的决策树,以更准确地理解模型的预测。
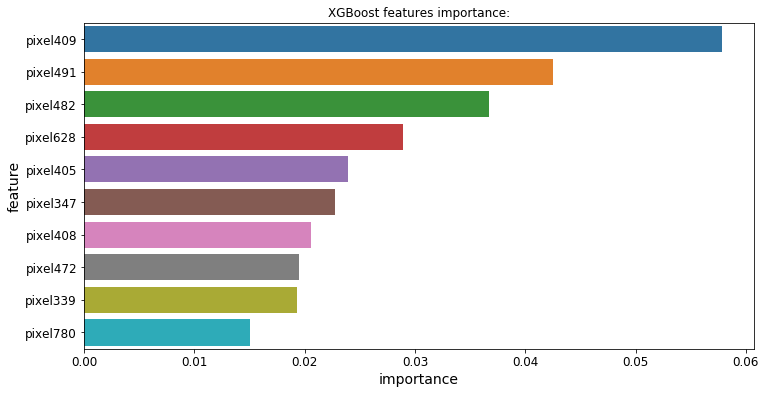
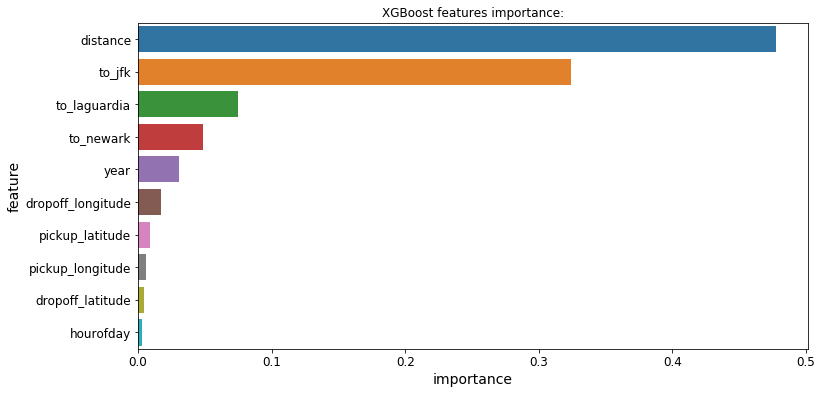
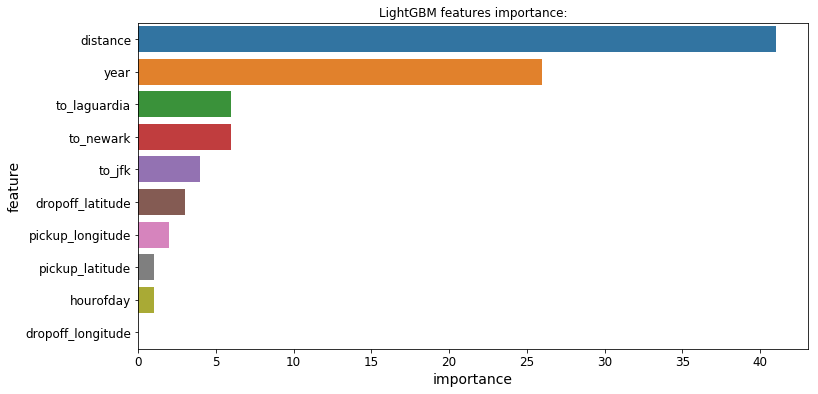
3.功能的重要性
所有3个模型都提供了一个.feature_importances_属性,让我们可以看到哪些特性对每个模型的预测影响最大:
Classification Challenge分类挑战
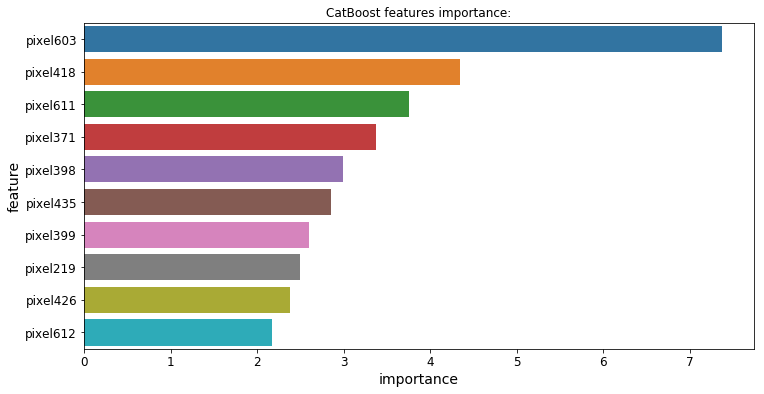
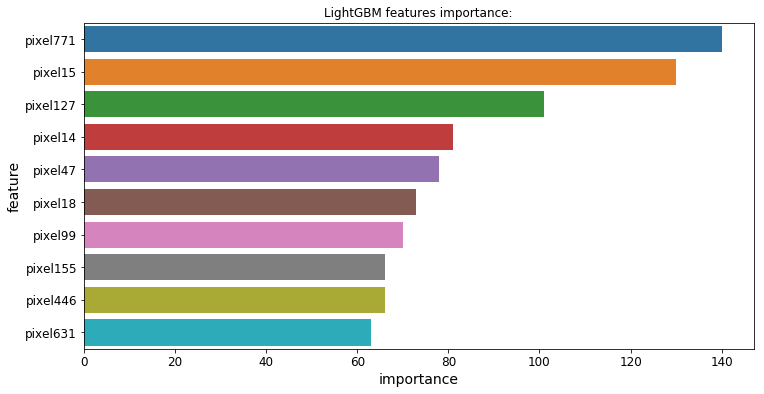
Regression Challenge回归挑战
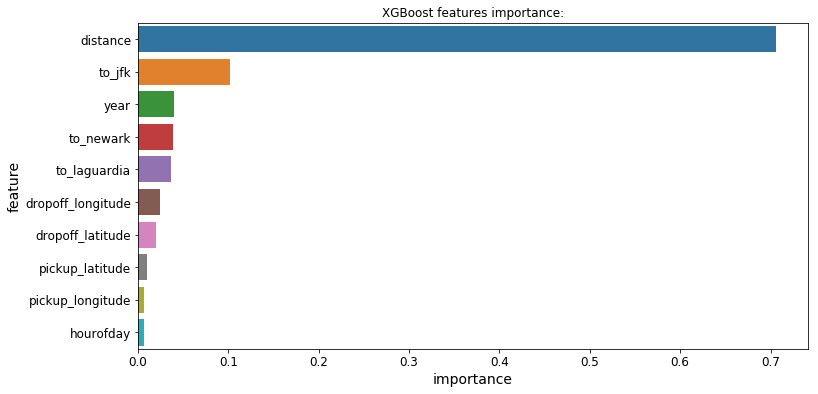

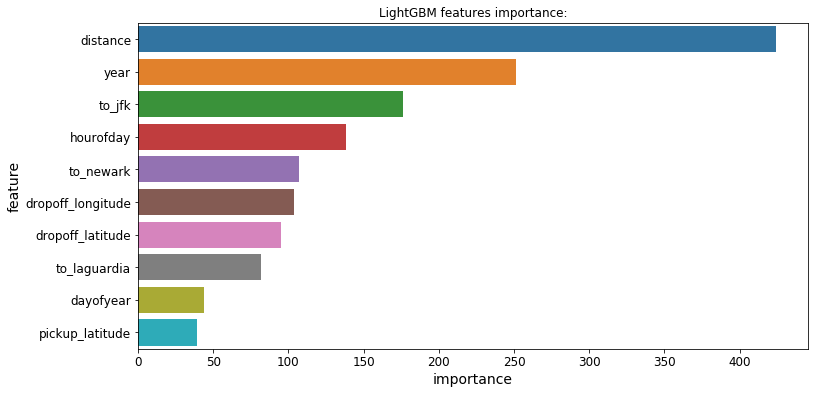
Massive Dataset Challenge海量数据集挑战

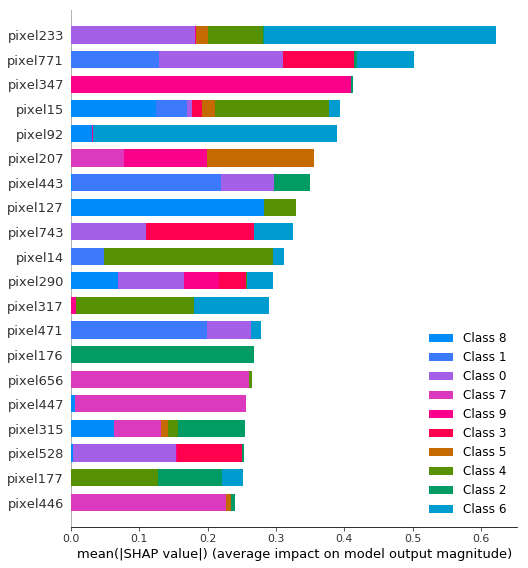
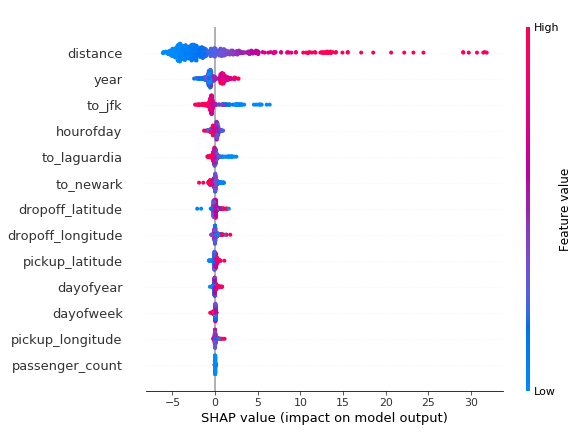
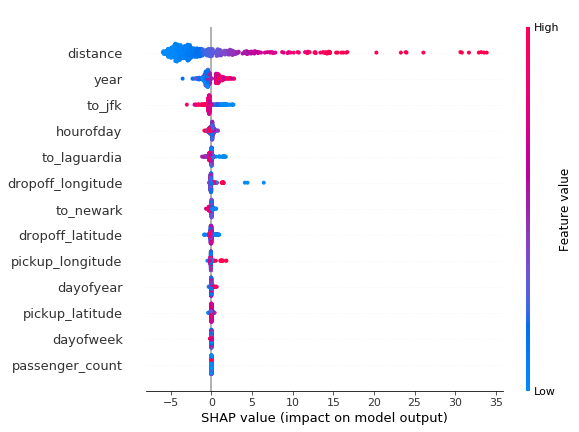
4.SHAP值
另一种了解每个特性对模型输出影响分布的方法是SHAP摘要图。SHAP值是特征之间的公平信用分配,并具有博弈论一致性的理论保证,这使得它们通常比整个数据集的典型特征重要性更值得信赖。
Classification Challenge分类挑战
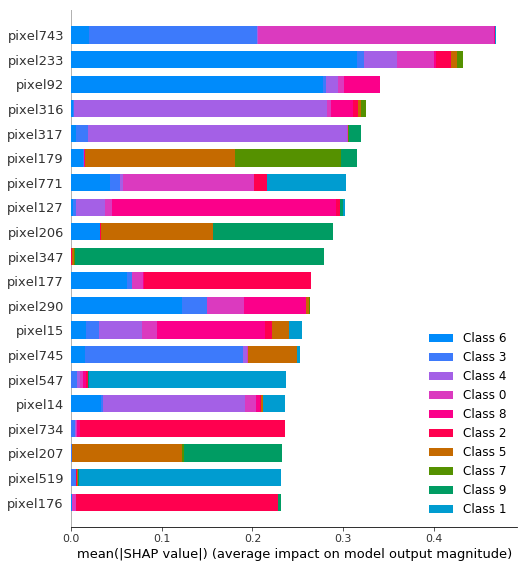
Regression Challenge回归挑战
绘制树木图
最后,XGBoost和LightGBM允许我们绘制用于进行预测的实际决策树,这对于更好地了解每个特征对目标变量的预测能力非常有用。
CatBoost船没有树的绘图功能。如果你真的想看到CatBoost的结果,这里提出了一个解决方案。
Classification Challenge分类挑战
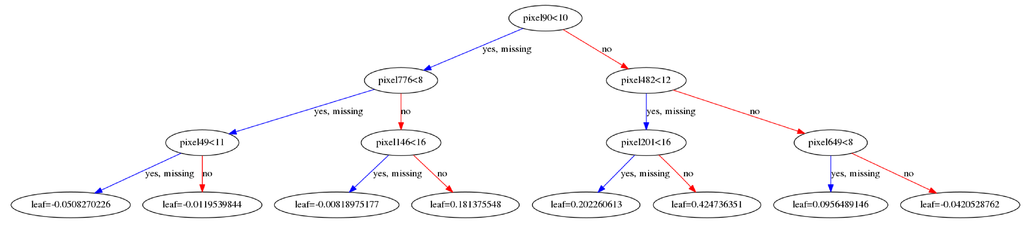
Regression Challenge回归挑战


模型比较
概述
如果你想深入研究这些算法,这里有一些介绍它们的论文的链接:
CatBoost:支持分类特性的梯度增强
LightGBM:一种高效的梯度增强决策树
XGBoost:一个可扩展的树增强系统
CatBoost
- 与XGBoost相比,它的准确性和训练时间显著提高
- 支持现成的分类功能,因此我们不需要预处理分类功能(例如,通过标签编码或OneHotEncoding)。事实上,CatBoost文档特别警告不要在预处理期间使用一个热编码,因为“这会影响培训速度和最终的质量”。
- 更好地处理过拟合,特别是在小数据集上实现有序增强
- 支持开箱即用的GPU培训(只需设置task_type = " GPU ")
- 处理开箱即用的缺失值
LightGBM
- 与XGBoost相比,它的准确性和训练时间显著提高
- 支持并行树提升,即使在大型数据集(比XGBoost)上也能提供更好的培训速度。
- 通过使用一种将连续特征提取为离散特征的柱状图型算法,实现了极快的训练速度和较低的内存使用率。
- 通过使用叶向拆分而不是水平拆分来获得极大的准确性,这会导致非常快速的聚合,并在非常复杂的树中捕获训练数据的底层模式。使用num_leaves和max_depth hyper参数控制过度拟合。
XGBoost
- 支持并行树提升
- 使用正则化来包含过拟合
- 支持用户定义的评估指标
- 处理框外缺少的值
- 比传统的梯度增强方法(如AdaBoost)快得多
超参数
检查下面的文档,以获得这些模型的超参数的完整列表:
XGBoost参数
LightGBM参数
CatBoost参数
让我们来看看每个模型最重要的参数!
Catboost
n_estimators—可以构建的树的最大数量。
学习率-学习率。用于减小梯度步长。
eval_metric—用于过拟合检测和最佳模型选择的度量。
深度——树的深度。
子样本—行采样率,不能用于贝叶斯增强类型设置。
l2_leaf_reg—成本函数L2正则化项下的系数。
random_strength—当选择树结构时,用于评分分割的随机性的数量。使用此参数可避免模型过度拟合。
min_data_in_leaf—叶中的最小训练样本数。CatBoost不会在样本计数小于指定值的叶中搜索新的拆分。
colsample_bylevel、colsample_bytree、colsample_bynode—各层、各树和各节点的列采样率。
task_type -采用值“GPU”或“CPU”。如果数据集足够大(从成千上万个对象开始),在GPU上的训练相对于在CPU上的训练可以显著提高速度。数据集越大,加速就越重要。
boosting_type-默认情况下,小数据集的增强类型设置为“Ordered”。这可以防止过度拟合,但在计算方面代价很高。尝试将此参数的值设置为“Plain”以加快训练。
rsm-对于具有数百个特性的数据集,此参数可加快培训速度,通常不会影响质量。对于很少(10-20)特性的数据集,不建议更改此参数的默认值。
border_count-此参数定义为每个功能考虑的拆分数。默认情况下,它设置为254(如果在CPU上执行训练)或128(如果在GPU上执行训练)。
LightGBM
num_leaves—树中叶子的最大数量。在LightGBM中,num_leaves必须小于2^(max_depth),以防止过拟合。较高的数值可以提高精度,但可能容易出现过拟合。
max_depth—树可以增长到的最大深度。有助于防止过度拟合。
min_data_in_leaf—每个叶子中的最小数据。一个小的值可能会导致过度拟合。
eval_metric—用于过拟合检测和最佳模型选择的度量。
学习率-学习率。用于减小梯度阶跃。
n_estimators—可以构建的树的最大数量。
colsample_bylevel、colsample_bytree、colsample_bynode—各层、各树和各节点的列采样率。
boosting_type -接受以下值:
- “gbdt”,传统的梯度增强决策树。
- “dart”,辍学者会遇到多个加法回归树。
- “goss”,基于梯度的单侧采样。
- “rf”,随机森林。
n_jobs——并行线程的数量。使用-1来使用所有可用的线程。
min_split_again—在树的叶子节点上进行进一步分区所需的最小损失减少。
feature_fraction—每次迭代中使用的特性的一部分。将此值设置得更低以增加训练速度。
bagging_fraction—每次迭代使用的数据的分数。将此值设置得更低以增加训练速度。
application - default=regression, type=enum, options=
- 回归:执行回归任务
- 二进制:二进制分类
- 多层结构:多层结构分类
- Lambdarank:Lambdarank应用
num_iteration—要执行的增强迭代的迭代。
max_bin—用于存储特性值的最大桶数。有助于防止过拟合。
好了!
就这样吧!
希望你读完这篇文章有所收获!

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消