











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






机器学习技术如何应用于股票价格预测?(下)
2019年07月02日 由 sunlei 发表
395837
0
上一篇文章中,我们一起了解了用“移动平均”、“线性回归”预测股价的方法,今天这篇文章中,我们继续讲解XGBoost、LSTM的方法预测股价。
前文回顾:用于股票价格预测的机器学习技术(上)
梯度增强是以迭代的方式将弱学习者转化为强学习者的过程。XGBoost这个名称指的是推动增强树算法的计算资源极限的工程目标。自2014年推出以来,XGBoost已被证明是一种非常强大的机器学习技术,通常是许多机器学习竞赛中的首选算法。
我们将在训练集上训练XGBoost模型,使用验证集调优其超参数,最后将XGBoost模型应用于测试集并报告结果。可以使用的明显特征是最近N天的调整收盘价,以及最近N天的成交量。除了这些特性,我们还可以进行一些特性工程。我们将构建的附加功能包括:
在构建这个模型的过程中,我学到了一个有趣的经验,那就是特征缩放对于模型的正常工作非常重要。我的第一个模型根本没有实现任何缩放,下面的图显示了对验证集的预测。这里所发生的是,该模型训练的调整收盘价在89到125之间,因此该模型只能在这个范围内输出预测。当模型试图预测验证集并且发现值超出这个范围时,它不能很好地概括。
[caption id="attachment_41691" align="aligncenter" width="853"]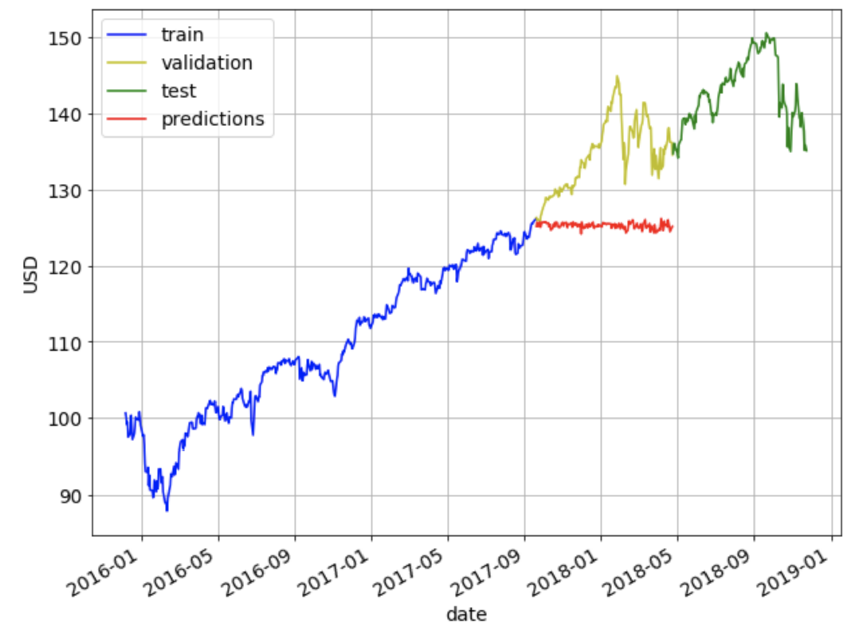 如果特征和目标缩放不正确,预测是非常不准确的。[/caption]
如果特征和目标缩放不正确,预测是非常不准确的。[/caption]
我试着下一个训练集规模意味着0和方差1,我应用同样的变换验证集。但很明显,这也不会起作用,因为这里我们计算出的平均值和方差来转换验证集。因为从验证集值远远大于从训练集,后扩展仍将是更大的值。
结果是,预测仍然像上面那样,只是y轴上的值现在缩放了。
最后,我将火车集合缩放为均值0和方差1,然后用这个来训练模型。随后,当我对验证集进行预测时,对于每个样本的每个特征组,我将把它们缩放为均值0和方差1。例如,如果我们对第T天进行预测,我将取最近N天(从第T-N天到第T-1天)的调整后收盘价,并将其缩放为均值0和方差1。对我们上面构建的其他特性重复同样的步骤。然后我们使用这些缩放的特征来进行预测。预测值也将被缩放,我们使用相应的平均值和方差对其进行反向变换。我发现这种扩展方式提供了最好的性能,正如我们将在下面看到的。
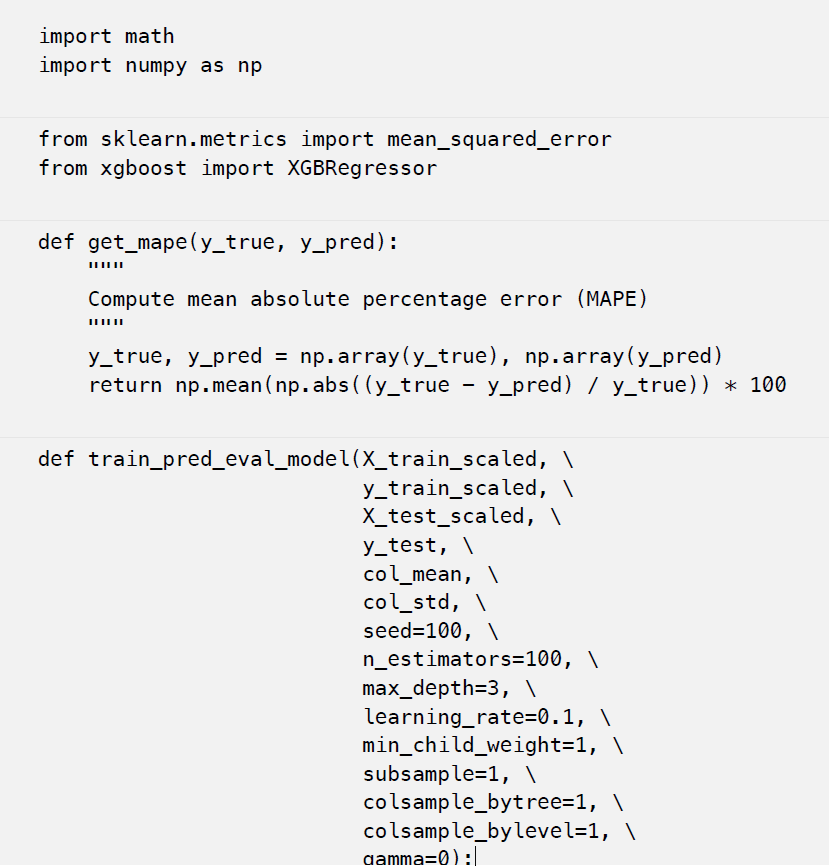
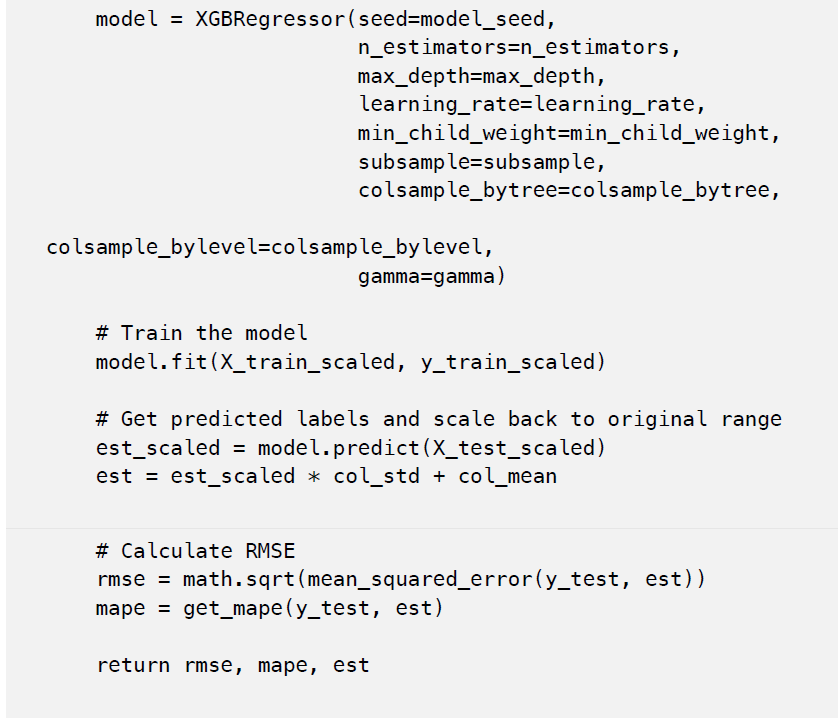
下面是我们用来训练模型和进行预测的代码。



下图显示了验证集上实际值和预测值之间的RMSE,对于不同的N值,我们将使用N=3,因为它给出了最低的RMSE。
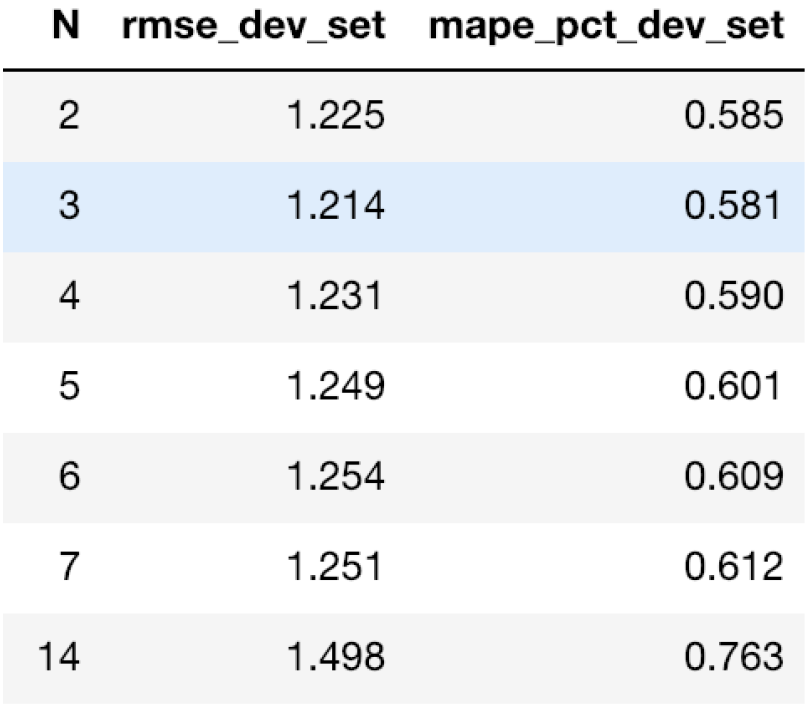
使用RMSE和MAPE调整N。
超参数和调优前后的性能如下所示。
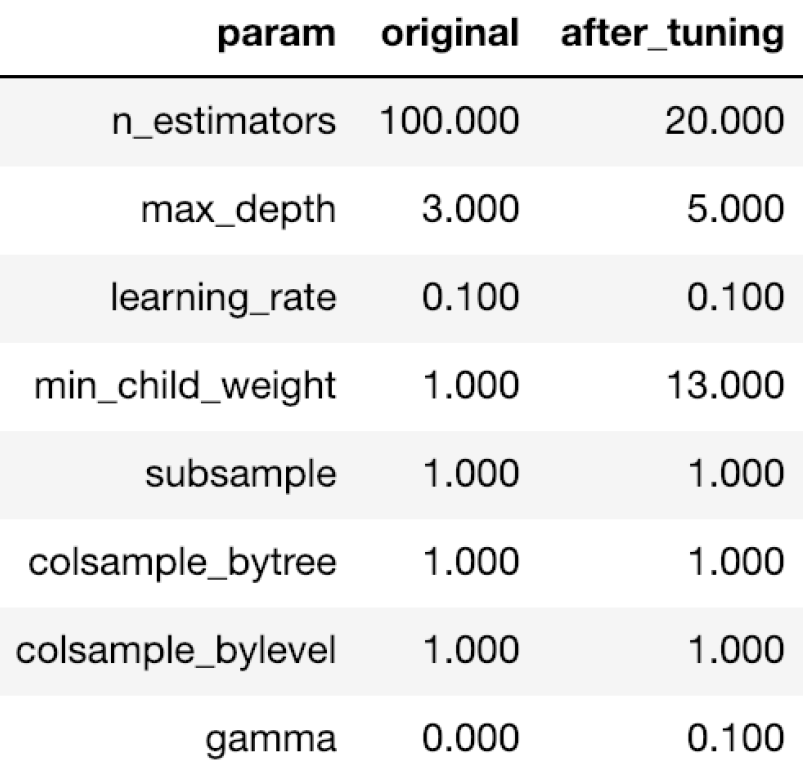
[caption id="attachment_41700" align="aligncenter" width="807"] 使用RMSE和MAPE调优XGBoost超参数。[/caption]
使用RMSE和MAPE调优XGBoost超参数。[/caption]
下图显示了使用XGBoost方法进行的预测。
[caption id="attachment_41701" align="aligncenter" width="846"]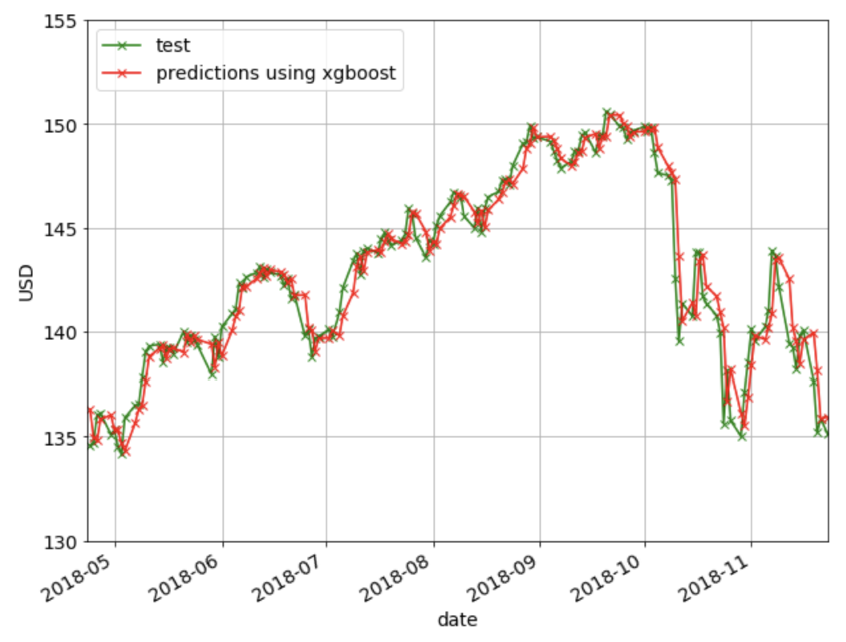 使用XGBoost方法进行预测。[/caption]
使用XGBoost方法进行预测。[/caption]
LSTM是一种深度学习技术,它是为了解决长序列中梯度消失问题而发展起来的。LSTM有三个门:更新门、遗忘门和输出门。update和forget gates确定是否更新了内存单元的每个元素。输出门决定作为下一层的激活而输出的信息量。
下面介绍我们将使用的LSTM体系结构。我们将使用两层LSTM模块和中间的dropout层来避免过拟合。
[caption id="attachment_41702" align="aligncenter" width="832"]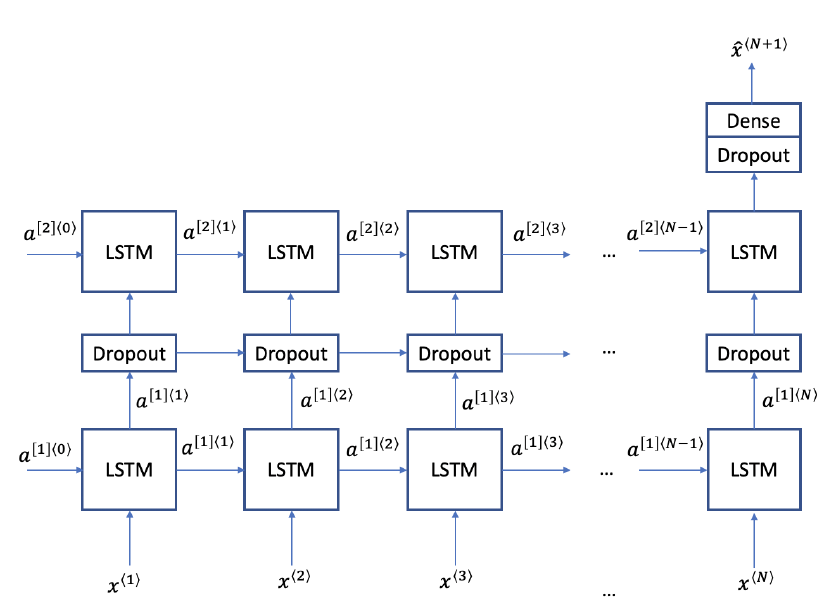 LSTM网络架构。[/caption]
LSTM网络架构。[/caption]
下面是我们用来训练模型和做预测的代码。
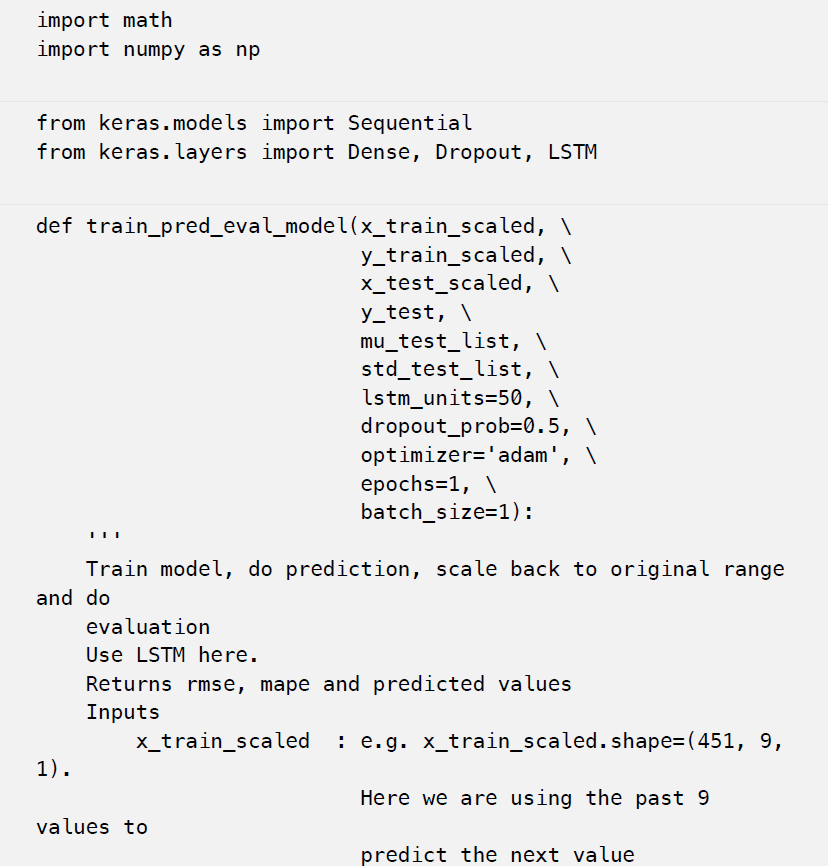
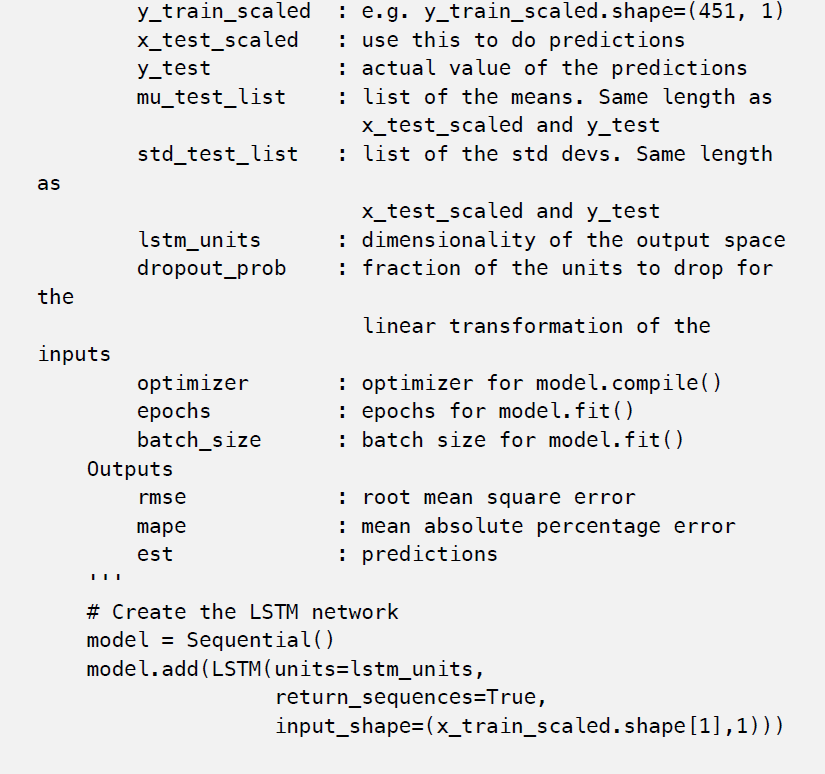

我们将使用与XGBoost中相同的方法来扩展数据集。在对验证集进行调优之前和之后,LSTM网络的超参数和性能如下所示。
[caption id="attachment_41706" align="aligncenter" width="806"]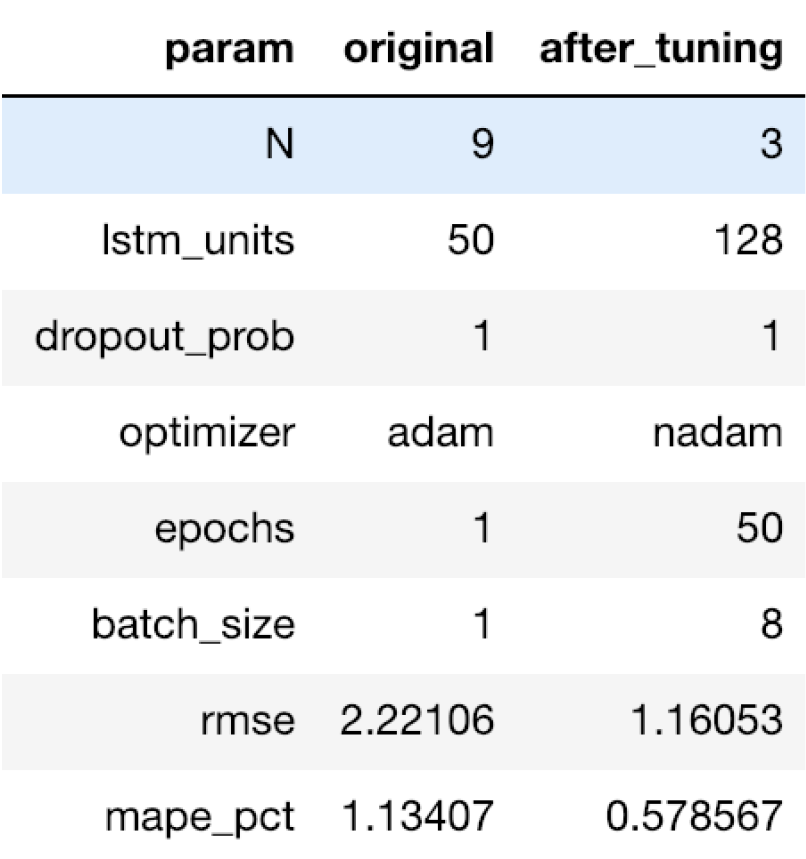 使用RMSE和MAPE调优LSTM超参数。[/caption]
使用RMSE和MAPE调优LSTM超参数。[/caption]
下图显示了使用LSTM的预测。
[caption id="attachment_41707" align="aligncenter" width="872"]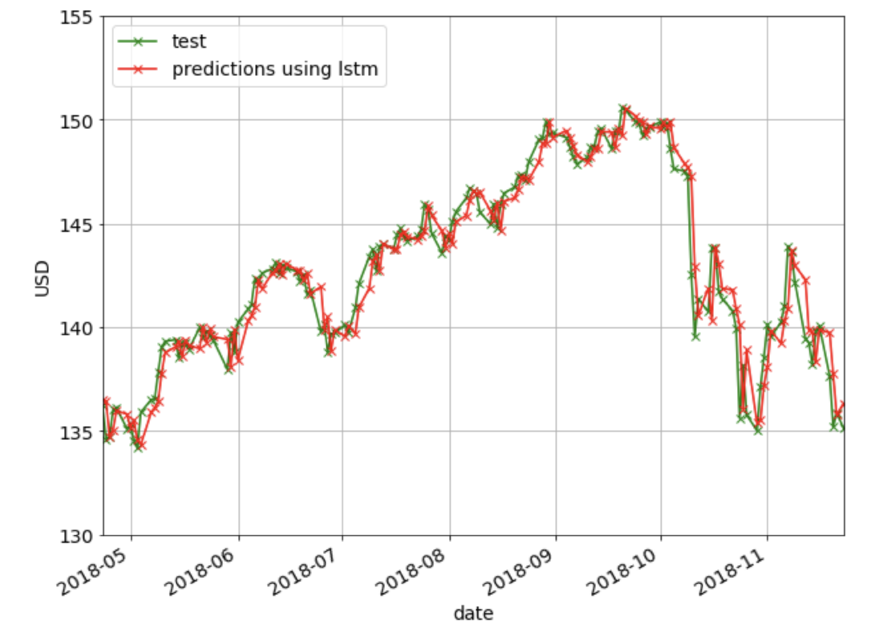 使用LSTM方法进行预测。[/caption]
使用LSTM方法进行预测。[/caption]
下面我们将在同一图表中绘制我们之前探索的所有方法的预测。很明显,使用线性级数的预测提供了最差的性能。除此之外,从视觉上很难判断哪种方法提供了最好的预测。
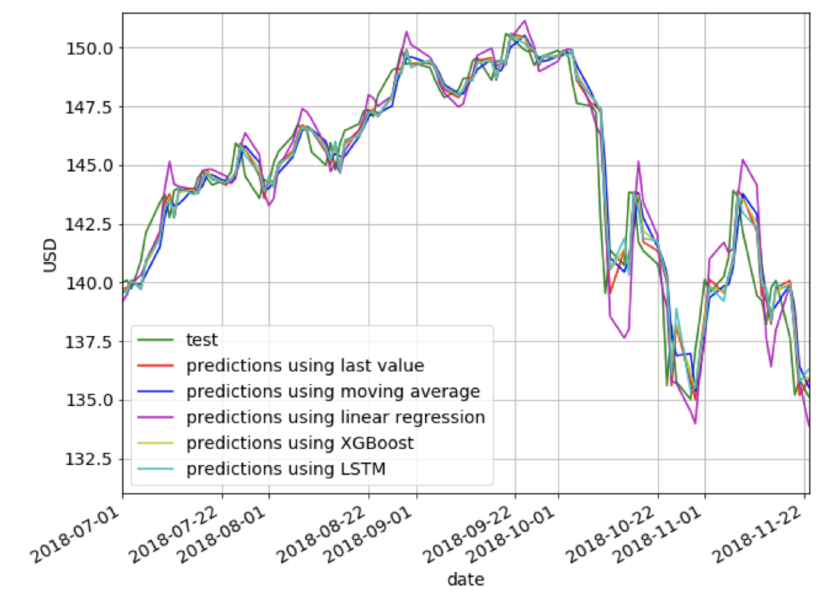
下面是我们探索的各种方法的RMSE和MAPE的并列比较。我们看到最后一个值方法给出了最低的RMSE和MAPE,其次是XGBoost,然后是LSTM。有趣的是,简单的last value方法优于所有其他更复杂的方法,但这可能是因为我们的预测范围只有1。对于较长的预测周期,我相信其他方法可以比上一种方法更好地捕捉趋势和季节性。
[caption id="attachment_41709" align="aligncenter" width="823"]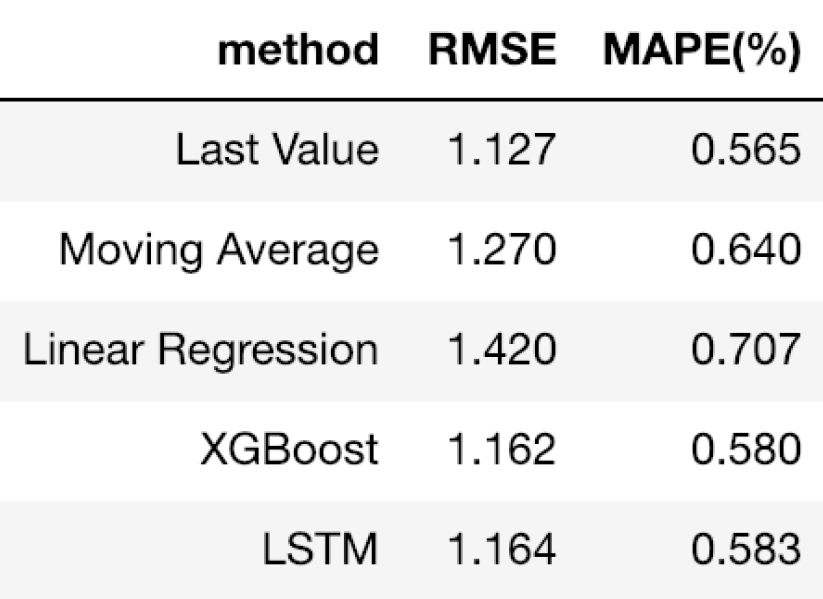 比较各种方法使用RMSE和MAPE。[/caption]
比较各种方法使用RMSE和MAPE。[/caption]
作为未来的工作,探索更长期的预测范围将是有趣的,例如1个月或1年。探索其他预测技术,如自回归综合移动平均(ARIMA)和三指数平滑(即霍尔特-温特斯方法)等其他预测技术,并了解它们与上述机器学习方法的比较,也会很有意思。
前文回顾:用于股票价格预测的机器学习技术(上)
极端的梯度增加(XGBoost)
梯度增强是以迭代的方式将弱学习者转化为强学习者的过程。XGBoost这个名称指的是推动增强树算法的计算资源极限的工程目标。自2014年推出以来,XGBoost已被证明是一种非常强大的机器学习技术,通常是许多机器学习竞赛中的首选算法。
我们将在训练集上训练XGBoost模型,使用验证集调优其超参数,最后将XGBoost模型应用于测试集并报告结果。可以使用的明显特征是最近N天的调整收盘价,以及最近N天的成交量。除了这些特性,我们还可以进行一些特性工程。我们将构建的附加功能包括:
- 高与低之间的差异为每一天的最后N天
- 最近N天每天开盘和收盘的差异
在构建这个模型的过程中,我学到了一个有趣的经验,那就是特征缩放对于模型的正常工作非常重要。我的第一个模型根本没有实现任何缩放,下面的图显示了对验证集的预测。这里所发生的是,该模型训练的调整收盘价在89到125之间,因此该模型只能在这个范围内输出预测。当模型试图预测验证集并且发现值超出这个范围时,它不能很好地概括。
[caption id="attachment_41691" align="aligncenter" width="853"]
如果特征和目标缩放不正确,预测是非常不准确的。[/caption]我试着下一个训练集规模意味着0和方差1,我应用同样的变换验证集。但很明显,这也不会起作用,因为这里我们计算出的平均值和方差来转换验证集。因为从验证集值远远大于从训练集,后扩展仍将是更大的值。
结果是,预测仍然像上面那样,只是y轴上的值现在缩放了。
最后,我将火车集合缩放为均值0和方差1,然后用这个来训练模型。随后,当我对验证集进行预测时,对于每个样本的每个特征组,我将把它们缩放为均值0和方差1。例如,如果我们对第T天进行预测,我将取最近N天(从第T-N天到第T-1天)的调整后收盘价,并将其缩放为均值0和方差1。对我们上面构建的其他特性重复同样的步骤。然后我们使用这些缩放的特征来进行预测。预测值也将被缩放,我们使用相应的平均值和方差对其进行反向变换。我发现这种扩展方式提供了最好的性能,正如我们将在下面看到的。
下面是我们用来训练模型和进行预测的代码。
下图显示了验证集上实际值和预测值之间的RMSE,对于不同的N值,我们将使用N=3,因为它给出了最低的RMSE。
使用RMSE和MAPE调整N。
超参数和调优前后的性能如下所示。
[caption id="attachment_41700" align="aligncenter" width="807"]
使用RMSE和MAPE调优XGBoost超参数。[/caption]下图显示了使用XGBoost方法进行的预测。
[caption id="attachment_41701" align="aligncenter" width="846"]
使用XGBoost方法进行预测。[/caption]长期短期记忆(LSTM)
LSTM是一种深度学习技术,它是为了解决长序列中梯度消失问题而发展起来的。LSTM有三个门:更新门、遗忘门和输出门。update和forget gates确定是否更新了内存单元的每个元素。输出门决定作为下一层的激活而输出的信息量。
下面介绍我们将使用的LSTM体系结构。我们将使用两层LSTM模块和中间的dropout层来避免过拟合。
[caption id="attachment_41702" align="aligncenter" width="832"]
LSTM网络架构。[/caption]下面是我们用来训练模型和做预测的代码。
我们将使用与XGBoost中相同的方法来扩展数据集。在对验证集进行调优之前和之后,LSTM网络的超参数和性能如下所示。
[caption id="attachment_41706" align="aligncenter" width="806"]
使用RMSE和MAPE调优LSTM超参数。[/caption]下图显示了使用LSTM的预测。
[caption id="attachment_41707" align="aligncenter" width="872"]
使用LSTM方法进行预测。[/caption]调查结果及未来工作
下面我们将在同一图表中绘制我们之前探索的所有方法的预测。很明显,使用线性级数的预测提供了最差的性能。除此之外,从视觉上很难判断哪种方法提供了最好的预测。
下面是我们探索的各种方法的RMSE和MAPE的并列比较。我们看到最后一个值方法给出了最低的RMSE和MAPE,其次是XGBoost,然后是LSTM。有趣的是,简单的last value方法优于所有其他更复杂的方法,但这可能是因为我们的预测范围只有1。对于较长的预测周期,我相信其他方法可以比上一种方法更好地捕捉趋势和季节性。
[caption id="attachment_41709" align="aligncenter" width="823"]
比较各种方法使用RMSE和MAPE。[/caption]作为未来的工作,探索更长期的预测范围将是有趣的,例如1个月或1年。探索其他预测技术,如自回归综合移动平均(ARIMA)和三指数平滑(即霍尔特-温特斯方法)等其他预测技术,并了解它们与上述机器学习方法的比较,也会很有意思。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
下一篇
对抗鲁棒分类器神经网络画风迁移








广告


写评论取消
回复取消