











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






AI对象检测器实例, 如何用TensorFlow的Object Detector API来训练你的物体检测器
2018年06月01日 由 yining 发表
278907
0
这篇文章是“用Tensorflow和OpenCV构建实时对象识别应用”的后续文章。具体来说,我在自己收集和标记的数据集上训练了我的浣熊检测器。完整的数据集可以在我的Github repo上看到。
看一下这个动图,这是运行中的浣熊探测器:

如果你想知道这个探测器的更多细节,就继续读下去!
在这篇文章中,我将解释所有必要的步骤来训练你自己的检测器。特别地,我创建了一个具有相对良好结果的对象检测器来识别浣熊。
你需要做的第一件事是创建自己的数据集:Tensorflow的Object Detection API使用TFRecord文件格式,因此在最后我们需要将数据集转换为该文件格式。
有几个选项可以生成TFRecord文件。如果你有一个与PASCAL VOC数据集或者Oxford Pet数据集相似的数据集,那么它们对本操作就有了一个现成的脚本(参见py和create_pet_tf_record.py)。如果你没有其中之一,那么你需要编写自己的脚本来生成TFRecords。
为了准备API的输入文件,你需要考虑两件事。首先,你需要一个RGB图像,它被编码为jpeg或png,其次你需要一个图像的包围盒(xmin,ymin,xmax,ymax),以及在包围盒中的对象的类。
我在谷歌图片和Pixabay上凑齐了200只浣熊的照片(主要格式是jpeg,还有一些pngs),这些图片在比例、姿势和光线上都有很大的变化。以下是我收集的浣熊图像数据集的一个子集:

之后,我用LabelImg手动给它们贴上标签。LabelImg是一种图形化的图像注释工具,它是用Python编写的,并且使用Qt作为图形界面。它支持Python2和Python3,但是我用Python2和Qt4来构建它,因为我用Python3和Qt5会出现一些问题。LabelImg非常容易使用,而且注释被作为XML文件保存在PASCAL VOC格式中,这意味着我也可以使用该文件的create_pascal_tf_record.py脚本。但是我并没有这样做,因为我想要创建我自己的脚本。
在某种程度上,LabelImg在MAC OSX上打开jpeg会出现问题,所以我不得不先把它们转换成pngs格式,然后再把它们转换成jpeg格式。实际上,我可以把它们放在pngs格式中,API也是应该支持这一点的。
最后,在对图像进行标记之后,我编写了一个脚本,该脚本将XML文件转换为csv,然后创建TFRecords。我使用了160张图片用于进行训练(train.records)和40张用于测试的图片(test.records)。这个脚本也可以在我的repo中找到。
一个目标探测训练管道。它们还在repo上提供了样本配置文件。在我的训练中,我使用ssd_mobilenet_v1_pets.config作为基础。我需要将num_classes调整为1,并为模型检查点(checkpoint)、训练和测试数据文件以及标签映射(label map)设置路径(PATH_TO_BE_CONFIGURED)。至于其他配置,比如学习速率、批处理大小等等,我使用了它们的默认设置。
注意:如果你的数据集没有很大的变化,比如不同的缩放比例、姿态等等,那么数据增强选项(data_augmentation_option)是非常有趣的。这里可以找到一个完整的选项列表(参阅PREPROCESSING_FUNCTION_MAP)。
数据集(TFRecord文件)及其相应的标签映射。如何创建标签映射的例子可以在这里找到。下面是我的标签映射,它很简单,因为只有一个类:
注意:很重要的一点是,你的标签映射应该始终从id 1开始。索引0是一个占位符索引(请参阅这篇讨论以获得关于此主题的更多信息)。
(可选)预训练模型检查点。我们建议使用一个检查点,从预训练模型开始训练总是更好的,因为从头开始的训练可能需要几天的时间才能得到好的结果。在我的例子中,我使用了ssd_mobilenet_v1_coco模型,因为模型速度对我来说比精确度更重要。
现在你可以开始训练了:
以下是我的训练和评估的结果。总的来说,我以一个批尺寸为24的22k步长运行了大概一个小时,但是我已经在大约40分钟内取得了很好的效果。
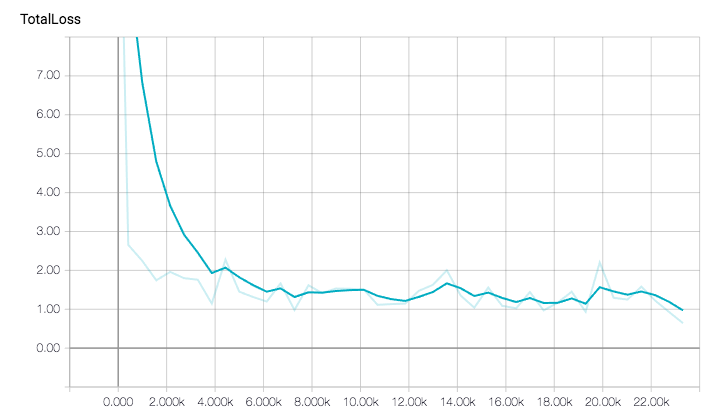
这是总损失的演变过程:
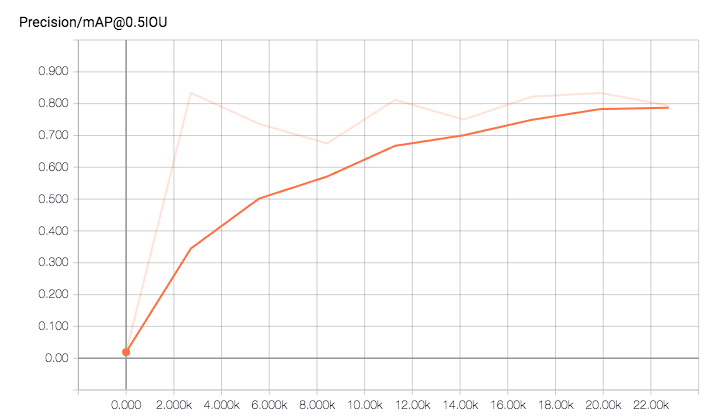
由于我只有一个类,所以只看总mAP(平均准确率)就足够了。
这里有一个在训练模型时对一个图像进行评估的例子。

在完成训练之后,我将训练过的模型导出到单个文件(Tensorflow graph proto)中,这样我就可以使用它进行推理。
在我的例子中,我必须将模型检查点从Google Cloud bucket复制到本地机器上,然后使用所提供的脚本导出模型。你可以在我的repo中找到这个模型。

你可以在Youtube上看一下这个视频:https://www.youtube.com/watch?v=W0sRoho8COI(浣熊检测器是令人震惊的)
如果你看过这个视频,你会发现并不是每个浣熊都被检测到或是被误分类。这是合乎逻辑的,因为我们只训练在一个小的数据集的模型。
此文为编译作品,作者Dat Tran,原网址:https://webcache.googleusercontent.com/search?q=cache:G8Pazlki568J:https://medium.com/towards-data-science/how-to-train-your-own-object-detector-with-tensorflows-object-detector-api-bec72ecfe1d9+&cd=1&hl=en&ct=clnk&gl=jp
看一下这个动图,这是运行中的浣熊探测器:
浣熊检测器
如果你想知道这个探测器的更多细节,就继续读下去!
在这篇文章中,我将解释所有必要的步骤来训练你自己的检测器。特别地,我创建了一个具有相对良好结果的对象检测器来识别浣熊。
创建数据集
你需要做的第一件事是创建自己的数据集:Tensorflow的Object Detection API使用TFRecord文件格式,因此在最后我们需要将数据集转换为该文件格式。
有几个选项可以生成TFRecord文件。如果你有一个与PASCAL VOC数据集或者Oxford Pet数据集相似的数据集,那么它们对本操作就有了一个现成的脚本(参见py和create_pet_tf_record.py)。如果你没有其中之一,那么你需要编写自己的脚本来生成TFRecords。
为了准备API的输入文件,你需要考虑两件事。首先,你需要一个RGB图像,它被编码为jpeg或png,其次你需要一个图像的包围盒(xmin,ymin,xmax,ymax),以及在包围盒中的对象的类。
我在谷歌图片和Pixabay上凑齐了200只浣熊的照片(主要格式是jpeg,还有一些pngs),这些图片在比例、姿势和光线上都有很大的变化。以下是我收集的浣熊图像数据集的一个子集:
浣熊图像数据集的子集
之后,我用LabelImg手动给它们贴上标签。LabelImg是一种图形化的图像注释工具,它是用Python编写的,并且使用Qt作为图形界面。它支持Python2和Python3,但是我用Python2和Qt4来构建它,因为我用Python3和Qt5会出现一些问题。LabelImg非常容易使用,而且注释被作为XML文件保存在PASCAL VOC格式中,这意味着我也可以使用该文件的create_pascal_tf_record.py脚本。但是我并没有这样做,因为我想要创建我自己的脚本。
在某种程度上,LabelImg在MAC OSX上打开jpeg会出现问题,所以我不得不先把它们转换成pngs格式,然后再把它们转换成jpeg格式。实际上,我可以把它们放在pngs格式中,API也是应该支持这一点的。
最后,在对图像进行标记之后,我编写了一个脚本,该脚本将XML文件转换为csv,然后创建TFRecords。我使用了160张图片用于进行训练(train.records)和40张用于测试的图片(test.records)。这个脚本也可以在我的repo中找到。
备注:
- 我还发现了另一个叫做FIAT(快速图像数据注释工具)的注释工具,它看起来也很不错。你可以尝试一下。
- 对于命令行中的图像处理,例如将多个图像转换为不同的文件格式,我推荐你使用ImageMagick,它是一个非常好的工具。如果你没有使用过,那就值得尝试一下。
- 确保图像的大小是中等的。如果图像太大,你可能会在训练期间运行内存不足,特别是当你不更改默认批处理大小设置时。
一个目标探测训练管道。它们还在repo上提供了样本配置文件。在我的训练中,我使用ssd_mobilenet_v1_pets.config作为基础。我需要将num_classes调整为1,并为模型检查点(checkpoint)、训练和测试数据文件以及标签映射(label map)设置路径(PATH_TO_BE_CONFIGURED)。至于其他配置,比如学习速率、批处理大小等等,我使用了它们的默认设置。
注意:如果你的数据集没有很大的变化,比如不同的缩放比例、姿态等等,那么数据增强选项(data_augmentation_option)是非常有趣的。这里可以找到一个完整的选项列表(参阅PREPROCESSING_FUNCTION_MAP)。
数据集(TFRecord文件)及其相应的标签映射。如何创建标签映射的例子可以在这里找到。下面是我的标签映射,它很简单,因为只有一个类:
item {
id: 1
name: 'raccoon' }注意:很重要的一点是,你的标签映射应该始终从id 1开始。索引0是一个占位符索引(请参阅这篇讨论以获得关于此主题的更多信息)。
(可选)预训练模型检查点。我们建议使用一个检查点,从预训练模型开始训练总是更好的,因为从头开始的训练可能需要几天的时间才能得到好的结果。在我的例子中,我使用了ssd_mobilenet_v1_coco模型,因为模型速度对我来说比精确度更重要。
现在你可以开始训练了:
- 训练可以在本地完成,也可以在云端完成(AWS、Google cloud等)。如果你在家里有GPU(至少超过2 GB),那么你可以在本地做,否则我建议你使用云计算。在我的例子中,我这次使用了Google Cloud,基本上遵循了他们文档中描述的所有步骤。
- 对于Google Cloud,你需要定义一个YAML配置文件。还有一个样本文件也被提供,并且基本上我只取默认值。
- 在训练开始时,也建议你开始做评估工作。你可以通过在你的本地机器上运行Tensorboard来监控训练和评估工作的过程。
tensorboard — logdir=gs://${YOUR_CLOUD_BUCKET}以下是我的训练和评估的结果。总的来说,我以一个批尺寸为24的22k步长运行了大概一个小时,但是我已经在大约40分钟内取得了很好的效果。
这是总损失的演变过程:
由于预训练模型,总损失相当快。
由于我只有一个类,所以只看总mAP(平均准确率)就足够了。
mAP在大约20k步长的时候达到了0.8是非常好的。
这里有一个在训练模型时对一个图像进行评估的例子。
浣熊周围的检查框随着时间的推移变得越来越好。
输出模型
在完成训练之后,我将训练过的模型导出到单个文件(Tensorflow graph proto)中,这样我就可以使用它进行推理。
在我的例子中,我必须将模型检查点从Google Cloud bucket复制到本地机器上,然后使用所提供的脚本导出模型。你可以在我的repo中找到这个模型。
地球上最著名的浣熊
福利:
你可以在Youtube上看一下这个视频:https://www.youtube.com/watch?v=W0sRoho8COI(浣熊检测器是令人震惊的)
如果你看过这个视频,你会发现并不是每个浣熊都被检测到或是被误分类。这是合乎逻辑的,因为我们只训练在一个小的数据集的模型。
此文为编译作品,作者Dat Tran,原网址:https://webcache.googleusercontent.com/search?q=cache:G8Pazlki568J:https://medium.com/towards-data-science/how-to-train-your-own-object-detector-with-tensorflows-object-detector-api-bec72ecfe1d9+&cd=1&hl=en&ct=clnk&gl=jp

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消