











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






如何用Python抓取最便宜的机票信息(上)
2019年05月07日 由 sunlei 发表
741380
0

简单地说
这个项目的目标是为一个特定的目的地建立一个web scraper,它将运行和执行具有灵活日期的航班价格搜索(在您首先选择的日期前后最多3天)。它保存一个包含结果的Excel,并发送一封包含快速统计信息的电子邮件。显然,目的是帮助我们找到最好的交易!
实际应用取决于您。我用它搜索假期和离我的家乡最近的一些短途旅行!
如果你非常认真的对待,您可以在服务器上运行脚本(一个简单的Raspberry Pi就可以了),并让它每天启动一两次。把结果邮寄给你,我建议将excel文件保存到Dropbox文件夹中,这样你就可以随时随地访问它了。

它会搜索“灵活日期”,因此它会在你首先选择的日期之前和之后的3天内查找航班。尽管该脚本一次只能运行一对目的地,但您可以轻松地对其进行调整,以便在每个循环中运行多个目的地。您甚至可能最终发现一些错误票价…这太棒了!
另一个scraper
当我第一次开始做一些web抓取时,我对这个主题不是特别感兴趣。但是我想说!如果我想做更多的项目,包括预测模型、财务分析,或许还有一些情绪分析,但事实证明,弄清楚如何构建第一个web爬虫程序非常有趣。在我不断学习的过程中,我意识到网络抓取是互联网“工作”的关键。
您可能认为这是一个非常大胆的说法,但是如果我告诉您谷歌是由一个用Java和Python构建的web scraper开始的呢?它爬行,而且依然如此,整个互联网试图为你的问题提供最好的答案。web抓取有无数的应用程序,即使您更喜欢数据科学中的其他主题,您仍然需要一些抓取技巧来获取数据。
我在这里使用的一些技术来自于我最近买的一本很棒的书,《Web Scraping with Python》它涵盖了与web抓取相关的所有内容。书中有大量简单的例子和大量的实际应用。甚至有一个非常有趣的章节是关于解决reCaptcha检查的,这让我大吃一惊——我不知道现有的工具甚至服务来处理它!
“你喜欢旅行吗?”
这个简单而无害的问题通常会得到一个积极的答案,然后会有一两个关于先前冒险的故事。我们大多数人都会同意旅行是体验新文化和开阔视野的好方法。但如果问题是“你喜欢搜索机票的过程吗?”,我敢肯定人们的反应不会那么热烈……
Python救援.
第一个挑战是选择从哪个平台获取信息。这有点儿难,但我还是选择了Kayak。我尝试了Momondo、Skyscanner、Expedia和其他一些网站,但这些网站上的reCaptchas非常残忍。在“你是人类吗”的检查中,我尝试了几次选择交通灯、人行横道和自行车后,我得出结论,Kayak是我最好的选择,只是当你在短时间内加载了太多页面,它会发出安全检查。我设法让机器人每隔4到6小时查询一次网站,一切正常。这里或那里可能偶尔会有一个小问题,但如果您开始获得reCaptcha检查,要么手动解决它们并在此之后启动机器人,或者等待几个小时,它会重置。您可以随意将代码调整到另一个平台,欢迎您在评论部分与我们分享!
如果你刚接触网络抓取,或者你不知道为什么有些网站要花很长时间来阻止它,请在编写第一行代码之前帮你自己一个大忙。谷歌“网页抓取礼仪”。如果你像个疯子一样开始抓,你的努力可能比你想象的要快得多。
系紧你的安全带……
大人不记小人过
在导入并打开chrome选项卡之后,我们将定义一些将在循环中使用的函数。结构的构思大致是这样的:
- 一个函数将启动bot,声明我们要搜索的城市和日期
- 该函数获取第一个搜索结果,按“最佳”航班排序,然后单击“加载更多结果”
- 另一个函数将抓取整个页面,并返回一个dataframe
- 对于“便宜”和“最快”排序类型,它将重复步骤2和步骤3
- 将向您发送一封电子邮件,其中简要总结了价格(最便宜和平均价格),并将包含这三种排序类型的数据框保存为excel文件
- 前面的所有步骤都在循环中重复,循环每X小时运行一次。
每个Selenium项目都从一个WebDriver开始。我正在使用Chromedriver,但是还有其他的选择。PhantomJS或Firefox也很受欢迎。下载之后,把它放在一个文件夹里,就这样。第一行将打开一个空白的Chrome选项卡。
请记住,我并没有在这里开辟新的领域。有更先进的方式找到便宜的交易,但我希望我的文章分享一些简单但实用的东西!
from time import sleep, strftime
from random import randint
import pandas as pd
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import smtplib
from email.mime.multipart import MIMEMultipart
# Change this to your own chromedriver path!
chromedriver_path = 'C:/{YOUR PATH HERE}/chromedriver_win32/chromedriver.exe'
driver = webdriver.Chrome(executable_path=chromedriver_path) # This will open the Chrome window
sleep(2)
这些是我将用于整个项目的包。我将使用randint使bot在每次搜索之间的睡眠时间是随机的。这通常是任何bot都必须具备的特性。如果运行前面的代码,应该会打开一个Chrome窗口,bot将在其中导航。
所以让我们做一个快速测试,在另一个窗口上访问kayak.com。选择您想要往返的城市和日期。在选择日期时,请确保选择“+-3天”。我在编写代码时考虑了结果页面,所以如果只想搜索特定的日期,很可能需要做一些调整。我会试着在整篇文章中指出这些变化,但如果你卡住了,请在评论中留言给我。
点击搜索按钮,在地址栏中找到链接。它应该类似于我下面使用的链接,我将变量kayak定义为url,并从webdriver执行get方法。您的搜索结果应该出现。

每当我在几分钟内使用get命令超过两三次时,都会出现reCaptcha检查。实际上,您可以自己解决reCaptcha,并在下一次出现之前继续进行您想要的测试。从我的测试来看,第一次搜索似乎总是没问题的,所以如果您想要摆弄代码,并且让代码在它们之间有很长的间隔时自动运行,那么实际上需要您自己来解决这个难题。你真的不需要10分钟更新这些价格,对吧?
每个XPath都有它的陷阱
到目前为止,我们打开了一个窗口,得到了一个网站。为了开始获取价格和其他信息,我们必须使用XPath或CSS选择器。我选择了XPath,并不觉得有必要将其与CSS混合使用,但是完全可以这样做。使用XPath导航网页可能会让人感到困惑,即使使用我曾经使用的直接从inspector视图中使用“复制XPath”技巧,我也意识到这并不是获得所需元素的最佳方法。有时,这种联系是如此具体,以至于很快就会过时。《用Python进行Web抓取》一书出色地解释了使用XPath和CSS选择器导航的基础知识。

接下来,让我们使用Python选择最便宜的结果。上面代码中的红色文本是XPath选择器,如果在任何地方右键单击网页并选择“inspect”,就可以看到它。再次单击右键要查看代码的位置,并再次检查。
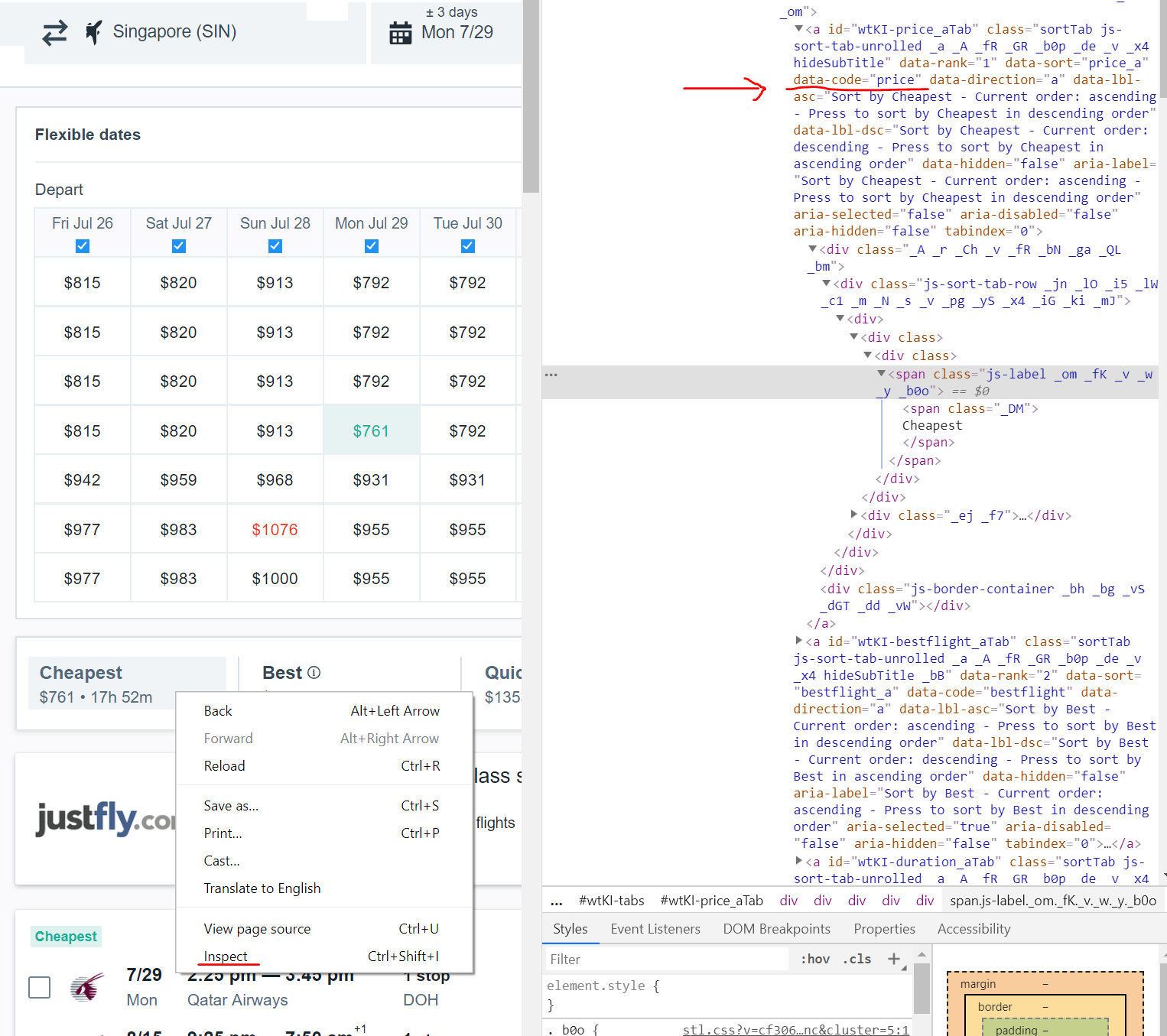
为了说明我之前对从检查器复制路径的缺点的观察,请考虑以下差异:
1 # This is what the copy method would return. Right click highlighted rows on the right side and select "copy > Copy XPath"
//*[@id="wtKI-price_aTab"]/div[1]/div/div/div[1]/div/span/span2 # This is what I used to define the "Cheapest" button
cheap_results = ‘//a[@data-code = “price”]’
第二种选择的简单性显而易见。它搜索具有属性data-code = price的元素a。第一个选项查找id等于wtKI-price_aTab的元素,并遵循第一个div元素、四个div和两个span。这次会成功的。我现在就可以告诉您,id元素将在下次加载页面时更改。每次页面加载时,字母wtKI都会动态变化,所以只要页面重新加载,您的代码就没用了。花点时间阅读一下XPath,我保证会有回报。
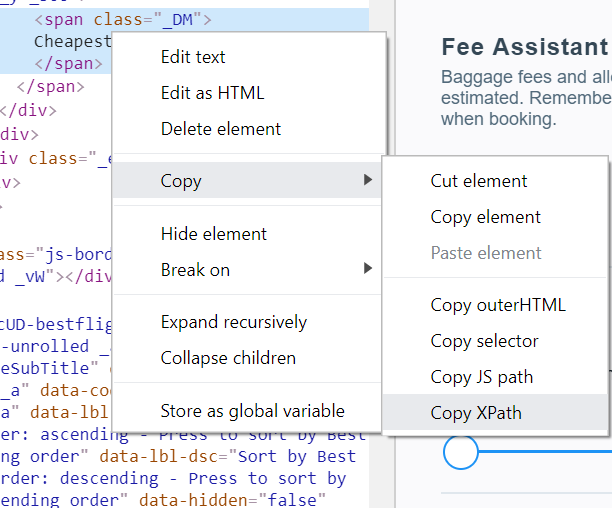
不过,使用复制方法可以在不那么“复杂”的网站上工作,这也很好!
基于上面显示的内容,如果我们想在列表中以几个字符串的形式获得所有搜索结果,该怎么办?其实很简单。每个结果都在一个对象中,这个对象的类是“resultWrapper”。获取所有结果可以通过像下面这样的for循环来实现。如果您理解了这一部分,您应该能够理解接下来的大部分代码。它基本上是指向您想要的东西(结果包装器),使用某种方式(XPath)获得文本,并将其放置在可读对象中(首先使用flight_containers,然后使用flights_list)。
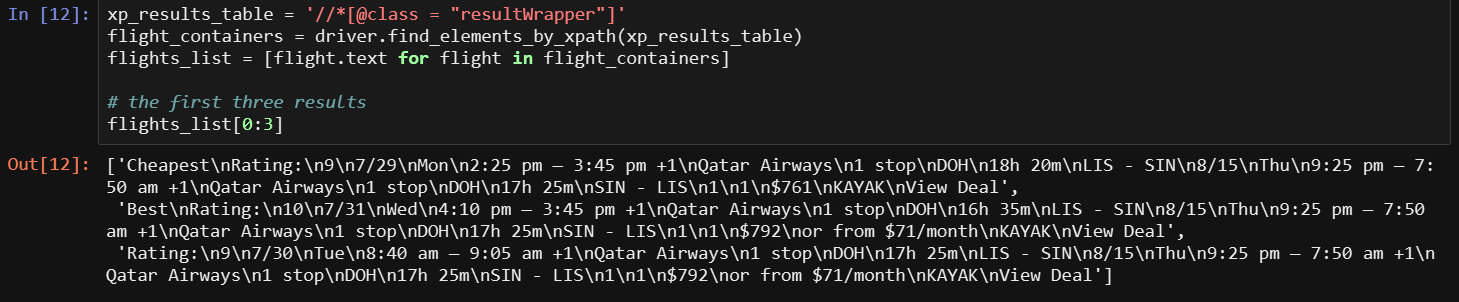
前3行显示出来,我们可以清楚地看到我们需要的所有内容,但是我们有更好的选择来获取信息。我们需要分别刮取每个元素。
准备起飞吧!
最容易编写的函数是加载更多的结果,所以让我们从这里开始。我想在不触发安全检查的情况下最大化我的航班数量,所以每次显示页面时,我都会在“加载更多结果”按钮中单击一次。惟一的新特性是try语句,我添加它是因为有时按钮加载不正确。如果它也对你起作用,只需在我将在前面展示的Start-Kayak函数中对其进行注释。
# Load more results to maximize the scraping
def load_more():
try:
more_results = '//a[@class = "moreButton"]'
driver.find_element_by_xpath(more_results).click()
# Printing these notes during the program helps me quickly check what it is doing
print('sleeping.....')
sleep(randint(45,60))
except:
pass
现在,经过长时间的介绍(我有时会忘乎所以!),我们已经准备好定义将实际擦除页面的函数。
我已经编译了下一个函数page-scrape中的大部分元素。有时,元素返回插入第一和第二条腿信息的列表。我使用了一个简单的方法来分割它们,例如在第一个section_a_list和section_b_list变量中。该函数还返回一个dataframe flights_df,因此我们可以将得到的不同排序的结果分离出来,稍后再合并它们。
def page_scrape():
"""This function takes care of the scraping part"""
xp_sections = '//*[@class="section duration"]'
sections = driver.find_elements_by_xpath(xp_sections)
sections_list = [value.text for value in sections]
section_a_list = sections_list[::2] # This is to separate the two flights
section_b_list = sections_list[1::2] # This is to separate the two flights
# if you run into a reCaptcha, you might want to do something about it
# you will know there's a problem if the lists above are empty
# this if statement lets you exit the bot or do something else
# you can add a sleep here, to let you solve the captcha and continue scraping
# i'm using a SystemExit because i want to test everything from the start
if section_a_list == []:
raise SystemExit
# I'll use the letter A for the outbound flight and B for the inbound
a_duration = []
a_section_names = []
for n in section_a_list:
# Separate the time from the cities
a_section_names.append(''.join(n.split()[2:5]))
a_duration.append(''.join(n.split()[0:2]))
b_duration = []
b_section_names = []
for n in section_b_list:
# Separate the time from the cities
b_section_names.append(''.join(n.split()[2:5]))
b_duration.append(''.join(n.split()[0:2]))
xp_dates = '//div[@class="section date"]'
dates = driver.find_elements_by_xpath(xp_dates)
dates_list = [value.text for value in dates]
a_date_list = dates_list[::2]
b_date_list = dates_list[1::2]
# Separating the weekday from the day
a_day = [value.split()[0] for value in a_date_list]
a_weekday = [value.split()[1] for value in a_date_list]
b_day = [value.split()[0] for value in b_date_list]
b_weekday = [value.split()[1] for value in b_date_list]
# getting the prices
xp_prices = '//a[@class="booking-link"]/span[@class="price option-text"]'
prices = driver.find_elements_by_xpath(xp_prices)
prices_list = [price.text.replace('$','') for price in prices if price.text != '']
prices_list = list(map(int, prices_list))
# the stops are a big list with one leg on the even index and second leg on odd index
xp_stops = '//div[@class="section stops"]/div[1]'
stops = driver.find_elements_by_xpath(xp_stops)
stops_list = [stop.text[0].replace('n','0') for stop in stops]
a_stop_list = stops_list[::2]
b_stop_list = stops_list[1::2]
xp_stops_cities = '//div[@class="section stops"]/div[2]'
stops_cities = driver.find_elements_by_xpath(xp_stops_cities)
stops_cities_list = [stop.text for stop in stops_cities]
a_stop_name_list = stops_cities_list[::2]
b_stop_name_list = stops_cities_list[1::2]
# this part gets me the airline company and the departure and arrival times, for both legs
xp_schedule = '//div[@class="section times"]'
schedules = driver.find_elements_by_xpath(xp_schedule)
hours_list = []
carrier_list = []
for schedule in schedules:
hours_list.append(schedule.text.split('\n')[0])
carrier_list.append(schedule.text.split('\n')[1])
# split the hours and carriers, between a and b legs
a_hours = hours_list[::2]
a_carrier = carrier_list[1::2]
b_hours = hours_list[::2]
b_carrier = carrier_list[1::2]
cols = (['Out Day', 'Out Time', 'Out Weekday', 'Out Airline', 'Out Cities', 'Out Duration', 'Out Stops', 'Out Stop Cities',
'Return Day', 'Return Time', 'Return Weekday', 'Return Airline', 'Return Cities', 'Return Duration', 'Return Stops', 'Return Stop Cities',
'Price'])
flights_df = pd.DataFrame({'Out Day': a_day,
'Out Weekday': a_weekday,
'Out Duration': a_duration,
'Out Cities': a_section_names,
'Return Day': b_day,
'Return Weekday': b_weekday,
'Return Duration': b_duration,
'Return Cities': b_section_names,
'Out Stops': a_stop_list,
'Out Stop Cities': a_stop_name_list,
'Return Stops': b_stop_list,
'Return Stop Cities': b_stop_name_list,
'Out Time': a_hours,
'Out Airline': a_carrier,
'Return Time': b_hours,
'Return Airline': b_carrier,
'Price': prices_list})[cols]
flights_df['timestamp'] = strftime("%Y%m%d-%H%M") # so we can know when it was scraped
return flights_df
我试着把名字写清楚。记住,变量a与行程的第一段相关,b与第二段相关。转到下一个函数。
等等,还有更精彩的吗?!我们明天见~

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消