











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






MLJ:用纯JULIA开发的机器学习框架,超越机器学习管道
2019年05月06日 由 明知不问 发表
588163
0
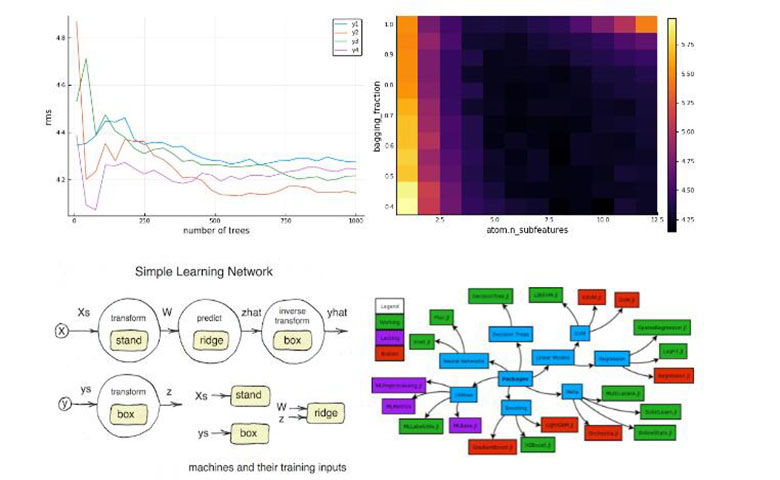 MLJ是一个用纯Julia编写的开源机器学习工具箱,它提供了一个统一的界面,用于与目前分散在不同Julia软件包中的有监督和无监督学习模型进行交互。
MLJ是一个用纯Julia编写的开源机器学习工具箱,它提供了一个统一的界面,用于与目前分散在不同Julia软件包中的有监督和无监督学习模型进行交互。MLJ旨在成为一个灵活的框架,用于组合和调整机器学习模型。
2018年12月,在早期概念验证的基础上,艾伦·图灵研究所开始了认真的开发工作。在短时间内,人们对这个项目的兴趣不断增加,现在这个项目已经成为了该研究所最受欢迎的软件存储库。
MLJ的特色
MLJ已经具备实质性的功能:
学习网络。超越传统管道的灵活模型组合。
自动调整。自动调整超参数,包括复合模型。作为与其他元算法组合的模型包装器实现调优。
同质模型集成。
模型元数据的注册表。模型元数据注册表。无需加载模型代码即可获得元数据。任务接口基础,便于模型组合。
任务界面。自动将模型与指定的学习任务相匹配,以简化基准测试和模型选择。
纯净的概率API。改进了对贝叶斯统计和概率图形模型的支持。
数据容器不可知。以你喜欢的Tables.jl格式显示并操作数据。
普遍采用分类数据类型。使模型实现能够正确地考虑训练中看到的类而不是评估中的类。
团队计划在不久的将来进行增强,包括Flux.jl深度学习模型的集成,以及使用自动微分的连续超参数的梯度下降调整。
虽然目前实现MLJ接口的机器学习模型相对较少,但正在进行的工作旨在将流行的python框架scikit-learn支持的模型封装起来,这是临时的权宜之计。
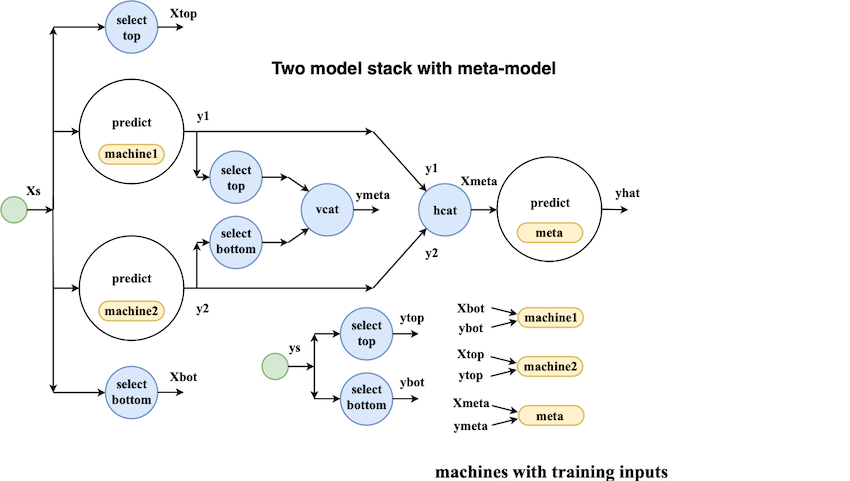
学习网络
MLJ的模型组合界面足够灵活,可以实现如数据科学竞赛中流行的模型堆栈。为了处理这种示例,界面设计必须考虑到预测和训练模式中的信息流是不同的这一事实。这可以从以下简单的双模型堆栈的示意图中看出,它被视为一个网络:
为何选择MLJ而不是ScitkitLearn.jl
为Julia用户提供的另一种机器学习工具箱是ScikitLearn.jl,最初用作流行的python库scikit-learn的Julia包装器,用Julia编写的ML算法也可以实现ScikitLearn.jl API。然而,元算法(系统调优,流水线等)仍然是python包装代码。
虽然ScitkiLearn.jl为Julia用户提供了对成熟且庞大的机器学习模型库的访问,但是scikit-learn API可以追溯到2007年,而且在未来可能不会发生重大变化。MLJ享有一些特性,从长远来看,它会成为一个更有吸引力的选择:
单一语言。ScikitLearn.jl包装了python代码,后者又为性能关键的例程包装了C代码。实现MLJ模型界面的Julia机器学习算法是100%纯Julia。在Julia中编写代码几乎与python一样快,编写良好的Julia代码运行速度几乎与C一样快。此外,单一语言设计提供了卓越的互操作性。例如,可以使用自动微分库(例如Flux.jl)实现:(i)超参数的梯度下降调优;(ii)使用CuArrays.jl,GPU性能提升而无需重大的代码重构。
模型元数据的注册表。在ScikitLearn.jl中,必须从文档中收集可用模型的列表,以及模型元数据(模型是否处理分类输入,是否可以进行概率预测等)。在MLJ中,这些信息更加结构化,MLJ可通过外部模型注册表访问(无需加载模型)。这形成了“任务”界面的基础,并促进了模型组合。
任务界面。一旦MLJ用户指定“任务”(例如“基于特征x,y,z进行房屋价值的概率预测”),则MLJ可以自动搜索匹配该任务的模型,从而协助系统进行基准测试和模型选择。
灵活的API用于模型组合。scikit-learn中的管道更像是一种事后的想法,而不是原始设计中不可或缺的部分。相比之下,MLJ的用户交互API基于灵活的“学习网络”API的要求,该API允许模型以基本上任意的方式连接(包括目标变换和逆变换)。在作为一流的独立模型导出之前,可以分阶段构建和测试网络。网络具有“智能”训练(在参数更改后仅重新训练必要的组件),并且最终将使用DAG调度程序进行训练。在Julia的元编程功能的帮助下,构建通用架构(如线性流水线和堆栈)将是单线操作。
纯净的概率API。scikit-learn API没有为概率预测的形式指定通用标准。通过沿着skpro项目的路线修复概率API ,MLJ旨在改进对贝叶斯统计和概率图形模型的支持。
普遍采用分类数据类型。Python的科学数组库NumPy没有用于表示分类数据的专用数据类型(即,没有跟踪所有池的类型可能的课程)。通常,scikit-learn模型通过要求将数据重新标记为整数来处理此问题。然而,用户在重新标记的分类数据上训练模型只是为了发现对测试集的评估,却使代码崩溃,因为分类特征具有在训练中未观察到的值。而MLJ通过坚持使用分类数据类型并坚持MLJ模型实现保留类池来缓解此类问题。例如,如果训练目标包含池中实际上不出现在训练集中的类,则概率预测将预测其支持包括缺失类,但是以概率零适当加权的分布。
资源
开源:
github.com/alan-turing-institute/MLJ.jl
项目详情:
alan-turing-institute.github.io/MLJ.jl/dev/
演示视频(从21'39起):
www.youtube.com/watch?v=CfHkjNmj1eE
建立一个自我调整的随机森林:
github.com/alan-turing-institute/MLJ.jl/blob/master/examples/random_forest.ipynb
贡献:
github.com/alan-turing-institute/MLJ.jl/blob/master/CONTRIBUTE.md

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消