











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






捕获深度学习数据以训练神经网络
2019年05月02日 由 马什么梅 发表
502053
0
 在GDC 2019上,NVIDIA发表了演讲,题为“真正的下一代:为游戏和图形添加深度学习”,详细介绍了当前最先进的游戏深度学习技术。
在GDC 2019上,NVIDIA发表了演讲,题为“真正的下一代:为游戏和图形添加深度学习”,详细介绍了当前最先进的游戏深度学习技术。在下面的摘录中,NVIDIA的高级研究科学家Anjul Patney提供了有关如何捕获神经网络训练数据的信息。他还描述了常见的深度学习错误,并解释了如何解决这些问题。
关键点:
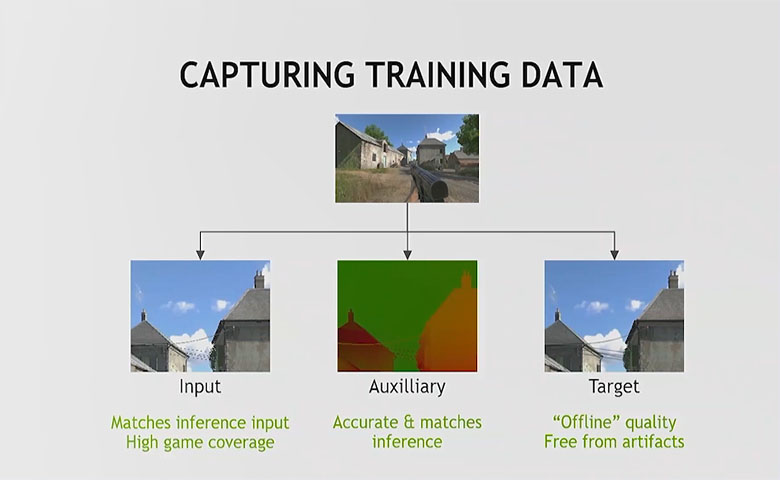
必须为神经网络训练捕获三组特定数据。
输入数据:这是你尝试优化,改进或删除伪影的输入。你会希望在最终运行中执行推理的确切位置捕获此数据集。捕获管道和推理管道应该对齐。应该拥有高水平的游戏覆盖率:包括所有生物群系(白天/黑夜,室内/室外等)。
辅助缓冲区:这是元数据(附加信息),你将使用它向网络提供有关正在执行的任务的更多详细信息。它必须匹配输入。
目标:参考必须是非常高的质量。通常情况下,你需要在一个状态中使用这些特征,该特征是正在训练并提升到最高保真度的。
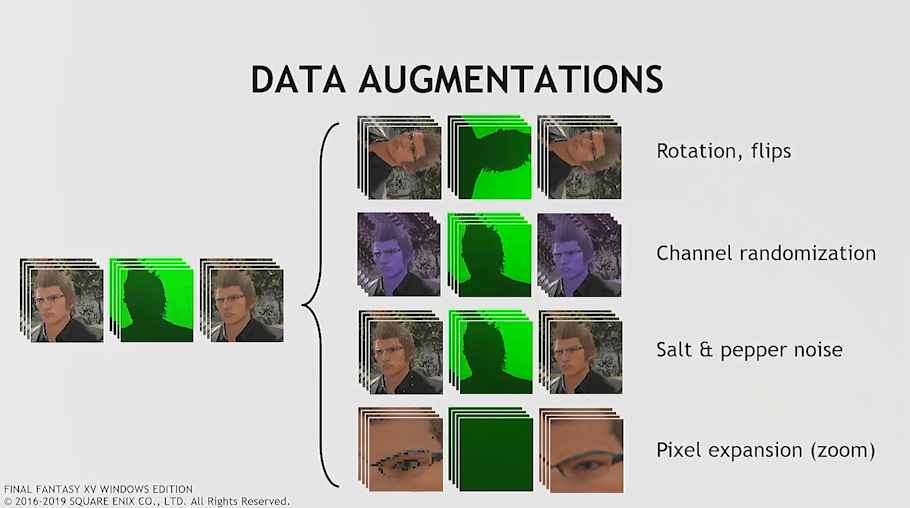
数据增强可能很有用,但它通常不是实际数据的良好替代品。
神经网络训练的增强包括翻转数据,随机化颜色或添加噪声。目标是扩展你正在显示网络的输入的范围。这可能是一项有用的练习,但你必须要小心。在许多情况下,此数据集将比网络看到的实际输入更宽。这可能导致网络学习超出预期,最终结果更差。
使用确定性渲染器
一个常见的瓶颈:当捕获数据时,你正在从渲染器中编写一堆图像,但你不能再玩游戏时执行此操作。更令人沮丧的是,你经常会改变分辨率,调整细节水平等。为了确保所有导出的数据都是对齐的,你肯定会想要使用确定性的渲染器。
确保轻松访问中间缓冲区
深度、运动和正常缓冲区应该是非临时存在的,并且它们应该易于访问并从管道中导出。
需要提升单个效果
许多引擎停在实时的质量水平。而你会想要一个超越它的引擎,并希望单个效果离线质量完美,因为目标图像中的任何缺陷都将在网络学习时被网络重现。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消