











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Python人脸检测指南(下)
2019年04月18日 由 sunlei 发表
536162
0
在前一篇文章中我写了如何使用OpenCV和Dlib在Python中创建和启动人脸检测算法,在这一篇中主要介绍如何添加一些功能来同时检测多个面孔上的眼睛和嘴巴。
1.5 包装
1.6 结果
我在YouTube上做了一个人脸检测算法的快速演示。
[playlist type="video" ids="39303"]
第二个最流行的人脸检测工具是由DLIB提供的,它使用了一个称为定向梯度直方图(HOG)的概念。这是Dalal和Triggs对原始论文的实现。
2.1理论
HOG背后的想法是将特征提取到一个向量中,并将其输入到一个分类算法中,比如支持向量机,它将评估一个人脸(或者你训练它识别的任何对象)是否存在于一个区域中。
提取的特征是图像梯度方向的分布(直方图)。梯度通常在边缘和角附近很大,允许我们检测这些区域。
在原论文中,对人体检测过程进行了实现,检测链如下:

2.1.a 预处理
首先,输入图像的大小必须相同(裁剪和重新缩放图像)。我们将应用的修补程序需要1:2的纵横比,因此输入图像的尺寸可能是64x128或100x200。
2.1.b 计算梯度图像
第一步是通过应用以下内核计算图像的水平和垂直梯度:
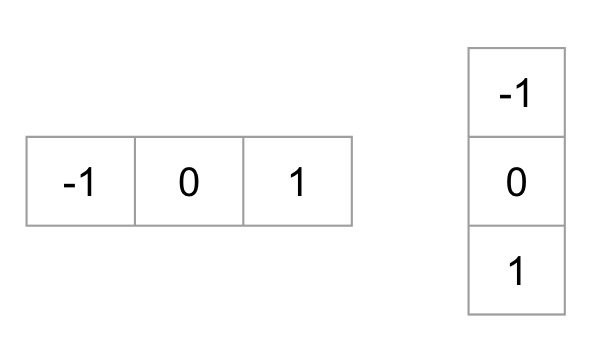
图像的梯度通常会删除不重要的信息。
我们在上面考虑的图像的梯度可以在python中这样找到:
并绘制图片:
不过,我们之前没有对图像进行预处理。
2.1.c 计算HOG
然后将图像分成8x8个单元,以提供一个紧凑的表示,并使我们的HOG对噪声更敏锐。然后,我们为每个单元格计算一个HOG。
要估计区域内梯度的方向,我们只需在每个区域内梯度方向的64个值(8x8)及其大小(另外64个值)之间构建直方图。直方图的类别对应梯度的角度,从0°到180°。总共有9个类别:0°、20°、40°……160°。
上面的代码给了我们两个信息:
梯度方向
梯度的大小
当我们构建HOG时,有3个子案例:
角度小于160°,且不介于两类之间。在这种情况下,角度将被添加到HOG的正确类别中
角度小于160°,且恰好在两类之间。在这种情况下,我们考虑对最近的两个类的贡献相等,并将大小分成2个部分
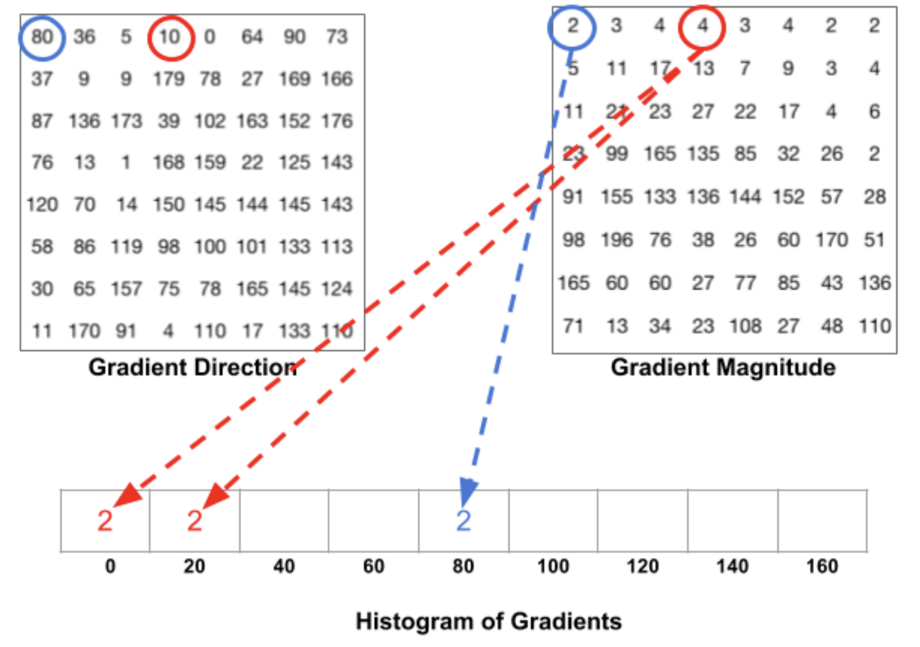
角度大于160°。在这种情况下,我们认为像素的贡献比例为160°和0°。
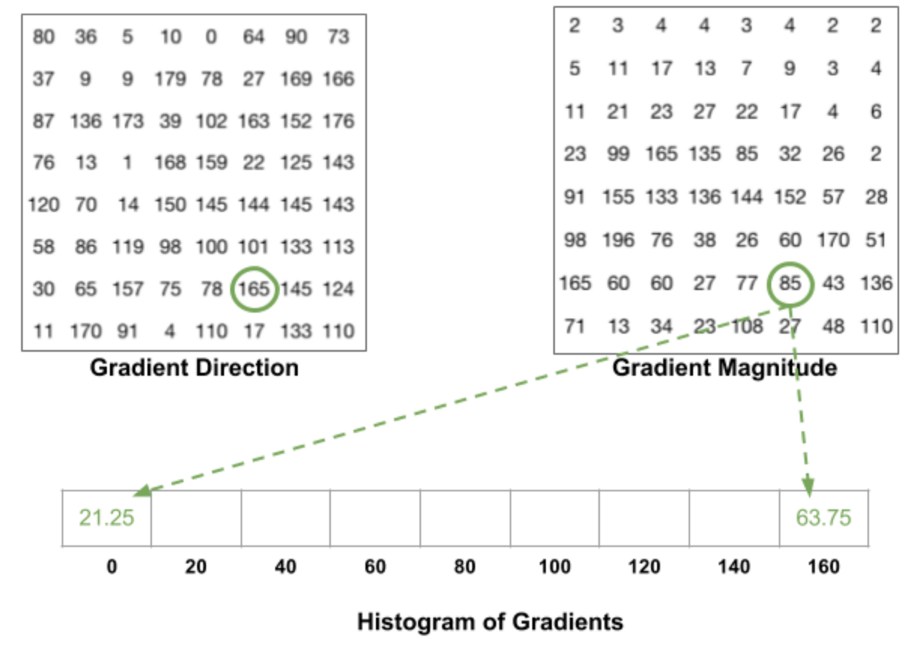
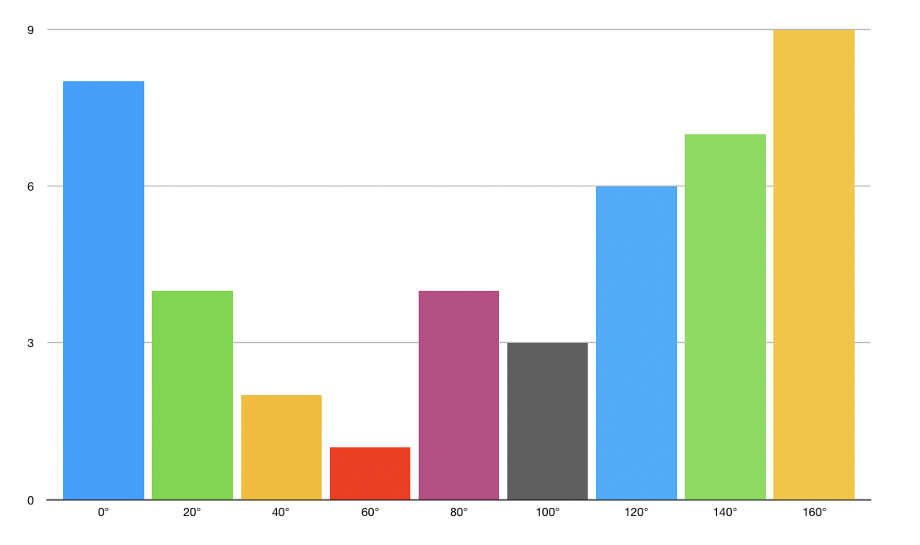
HOG对于每个8x8单元格是这样的:
2.1.d 区间归一化
最后,可以使用16x16块对图像进行归一化,使其不受光照的影响。这是通过将大小为8x8的HOG的每个值除以包含它的16x16块HOG的L2-norm来实现的,这个块实际上是一个长度为9*4 = 36的简单向量。
2.1.e 区间归一化
最后,将所有36x1向量连接成一个大向量。做完了!我们有了我们的特征向量,我们可以在这上面训练一个软SVM分类器(C=0.01)。
2.2 检测图像上的人脸
实现非常简单:
2.3 实时人脸检测
和以前一样,这个算法很容易实现。我们还实现了一个更轻巧的版本,只检测脸部。Dlib使人脸识别变得非常容易,但这是另一个话题了。
最后一种方法是基于卷积神经网络(CNN)的。它还实现了一篇关于最大边缘对象检测(MMOD)的增强结果的论文。
3.1 一点点理论
卷积神经网络(CNN)是一种主要用于计算机视觉的前馈神经网络。他们提供了一个自动化的图像预处理以及密集的神经网络部分。CNN是一种特殊类型的神经网络,用于处理具有网格状拓扑结构的数据。CNN的结构灵感来自于动物的视觉皮层。
在以前的方法中,大部分工作是选择过滤器,以便创建特性,以便从图像中提取尽可能多的信息。随着深度学习和计算能力的提高,这项工作现在可以自动化了。CNN的名称来自于这样一个事实:我们将初始图像输入与一组过滤器进行卷积。要选择的参数保留要应用的过滤器的数量和过滤器的维度。滤波器的尺寸称为步长。典型的步长值在2到5之间。
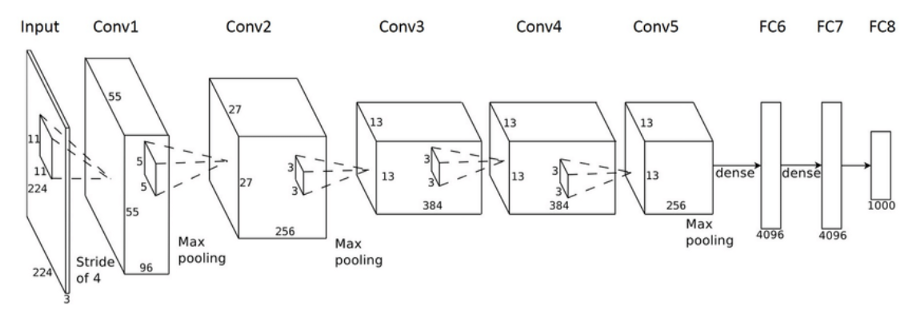
在这个特定的例子中,CNN的输出是一个二进制分类,如果有一个面,它的值为1,否则为0。
3.2检测图像上的人脸
实现过程中有一些元素发生了更改。
第一步是在这里下载预训练的模型。将权重移动到文件夹,并定义dnnDaceDetector:
然后,与我们目前所做的非常相似:
3.3 实时人脸检测
最后,我们将实现CNN人脸检测的实时版本:
这是个很难回答的问题,但我们只会讨论两个重要的指标:
计算时间
准确性
在速度方面,HOG算法似乎是最快的,其次是Haar级联分类器和CNN。
然而,Dlib中的CNN往往是最精确的算法。HOG表现得很好,但是在识别小面孔方面有一些问题。HaarCascade分类器的性能和HOG一样好。
我个人主要在我的个人项目中使用HOG,因为它可以快速的进行实时人脸检测。
结论:我希望你喜欢这个关于OpenCV和Dlib人脸检测的快速教程。如果你有任何问题/意见,请尽管提出来。
1.5 包装
import cv2
cascPath = "/usr/local/lib/python3.7/site-packages/cv2/data/haarcascade_frontalface_default.xml"
eyePath = "/usr/local/lib/python3.7/site-packages/cv2/data/haarcascade_eye.xml"
smilePath = "/usr/local/lib/python3.7/site-packages/cv2/data/haarcascade_smile.xml"
faceCascade = cv2.CascadeClassifier(cascPath)
eyeCascade = cv2.CascadeClassifier(eyePath)
smileCascade = cv2.CascadeClassifier(smilePath)
font = cv2.FONT_HERSHEY_SIMPLEX
video_capture = cv2.VideoCapture(0)
while True:
# Capture frame-by-frame
ret, frame = video_capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = faceCascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(200, 200),
flags=cv2.CASCADE_SCALE_IMAGE
)
# Draw a rectangle around the faces
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x+w, y+h), (255, 0, 0), 3)
roi_gray = gray[y:y+h, x:x+w]
roi_color = frame[y:y+h, x:x+w]
cv2.putText(frame,'Face',(x, y), font, 2,(255,0,0),5)
smile = smileCascade.detectMultiScale(
roi_gray,
scaleFactor= 1.16,
minNeighbors=35,
minSize=(25, 25),
flags=cv2.CASCADE_SCALE_IMAGE
)
for (sx, sy, sw, sh) in smile:
cv2.rectangle(roi_color, (sh, sy), (sx+sw, sy+sh), (255, 0, 0), 2)
cv2.putText(frame,'Smile',(x + sx,y + sy), 1, 1, (0, 255, 0), 1)
eyes = eyeCascade.detectMultiScale(roi_gray)
for (ex,ey,ew,eh) in eyes:
cv2.rectangle(roi_color,(ex,ey),(ex+ew,ey+eh),(0,255,0),2)
cv2.putText(frame,'Eye',(x + ex,y + ey), 1, 1, (0, 255, 0), 1)
cv2.putText(frame,'Number of Faces : ' + str(len(faces)),(40, 40), font, 1,(255,0,0),2)
# Display the resulting frame
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything is done, release the capture
video_capture.release()
cv2.destroyAllWindows()
1.6 结果
我在YouTube上做了一个人脸检测算法的快速演示。
[playlist type="video" ids="39303"]
2.Dlib中的定向梯度直方图(HOG)
第二个最流行的人脸检测工具是由DLIB提供的,它使用了一个称为定向梯度直方图(HOG)的概念。这是Dalal和Triggs对原始论文的实现。
2.1理论
HOG背后的想法是将特征提取到一个向量中,并将其输入到一个分类算法中,比如支持向量机,它将评估一个人脸(或者你训练它识别的任何对象)是否存在于一个区域中。
提取的特征是图像梯度方向的分布(直方图)。梯度通常在边缘和角附近很大,允许我们检测这些区域。
在原论文中,对人体检测过程进行了实现,检测链如下:
2.1.a 预处理
首先,输入图像的大小必须相同(裁剪和重新缩放图像)。我们将应用的修补程序需要1:2的纵横比,因此输入图像的尺寸可能是64x128或100x200。
2.1.b 计算梯度图像
第一步是通过应用以下内核计算图像的水平和垂直梯度:
图像的梯度通常会删除不重要的信息。
我们在上面考虑的图像的梯度可以在python中这样找到:
gray = cv2.imread('images/face_detect_test.jpeg', 0)im = np.float32(gray) / 255.0# Calculate gradient
gx = cv2.Sobel(im, cv2.CV_32F, 1, 0, ksize=1)
gy = cv2.Sobel(im, cv2.CV_32F, 0, 1, ksize=1)
mag, angle = cv2.cartToPolar(gx, gy, angleInDegrees=True)并绘制图片:
plt.figure(figsize=(12,8))
plt.imshow(mag)
plt.show()

不过,我们之前没有对图像进行预处理。
2.1.c 计算HOG
然后将图像分成8x8个单元,以提供一个紧凑的表示,并使我们的HOG对噪声更敏锐。然后,我们为每个单元格计算一个HOG。
要估计区域内梯度的方向,我们只需在每个区域内梯度方向的64个值(8x8)及其大小(另外64个值)之间构建直方图。直方图的类别对应梯度的角度,从0°到180°。总共有9个类别:0°、20°、40°……160°。
上面的代码给了我们两个信息:
梯度方向
梯度的大小
当我们构建HOG时,有3个子案例:
角度小于160°,且不介于两类之间。在这种情况下,角度将被添加到HOG的正确类别中
角度小于160°,且恰好在两类之间。在这种情况下,我们考虑对最近的两个类的贡献相等,并将大小分成2个部分
角度大于160°。在这种情况下,我们认为像素的贡献比例为160°和0°。
HOG对于每个8x8单元格是这样的:
2.1.d 区间归一化
最后,可以使用16x16块对图像进行归一化,使其不受光照的影响。这是通过将大小为8x8的HOG的每个值除以包含它的16x16块HOG的L2-norm来实现的,这个块实际上是一个长度为9*4 = 36的简单向量。
2.1.e 区间归一化
最后,将所有36x1向量连接成一个大向量。做完了!我们有了我们的特征向量,我们可以在这上面训练一个软SVM分类器(C=0.01)。
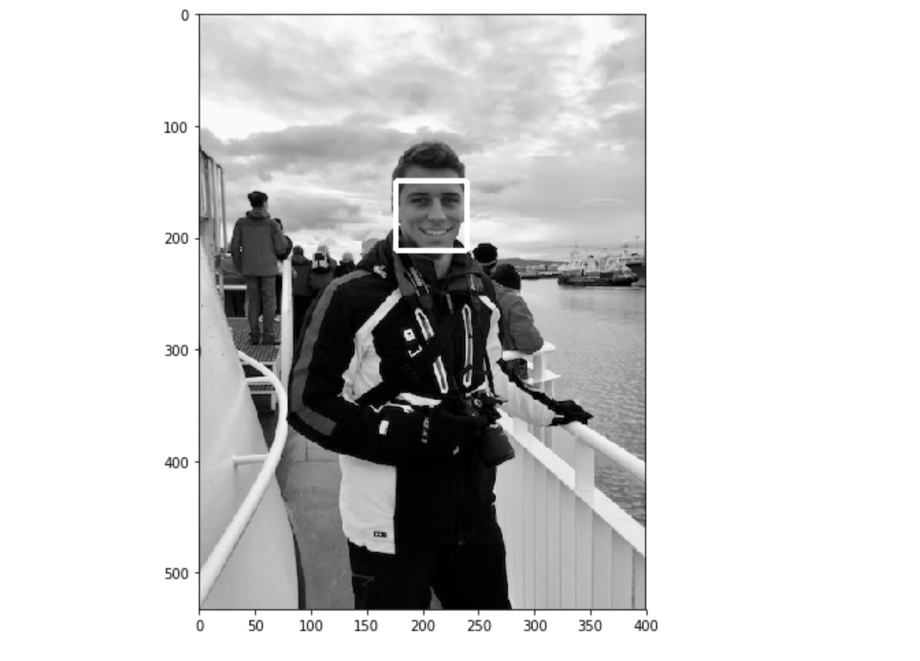
2.2 检测图像上的人脸
实现非常简单:
face_detect = dlib.get_frontal_face_detector()rects = face_detect(gray, 1)for (i, rect) in enumerate(rects):
(x, y, w, h) = face_utils.rect_to_bb(rect)
cv2.rectangle(gray, (x, y), (x + w, y + h), (255, 255, 255), 3)
plt.figure(figsize=(12,8))
plt.imshow(gray, cmap='gray')
plt.show()
2.3 实时人脸检测
和以前一样,这个算法很容易实现。我们还实现了一个更轻巧的版本,只检测脸部。Dlib使人脸识别变得非常容易,但这是另一个话题了。
video_capture = cv2.VideoCapture(0)
flag = 0
while True:
ret, frame = video_capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
rects = face_detect(gray, 1)
for (i, rect) in enumerate(rects):
(x, y, w, h) = face_utils.rect_to_bb(rect)
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 0), 2)
cv2.imshow('Video', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video_capture.release()
cv2.destroyAllWindows()
3.Dlib中的卷积神经网络
最后一种方法是基于卷积神经网络(CNN)的。它还实现了一篇关于最大边缘对象检测(MMOD)的增强结果的论文。
3.1 一点点理论
卷积神经网络(CNN)是一种主要用于计算机视觉的前馈神经网络。他们提供了一个自动化的图像预处理以及密集的神经网络部分。CNN是一种特殊类型的神经网络,用于处理具有网格状拓扑结构的数据。CNN的结构灵感来自于动物的视觉皮层。
在以前的方法中,大部分工作是选择过滤器,以便创建特性,以便从图像中提取尽可能多的信息。随着深度学习和计算能力的提高,这项工作现在可以自动化了。CNN的名称来自于这样一个事实:我们将初始图像输入与一组过滤器进行卷积。要选择的参数保留要应用的过滤器的数量和过滤器的维度。滤波器的尺寸称为步长。典型的步长值在2到5之间。
在这个特定的例子中,CNN的输出是一个二进制分类,如果有一个面,它的值为1,否则为0。
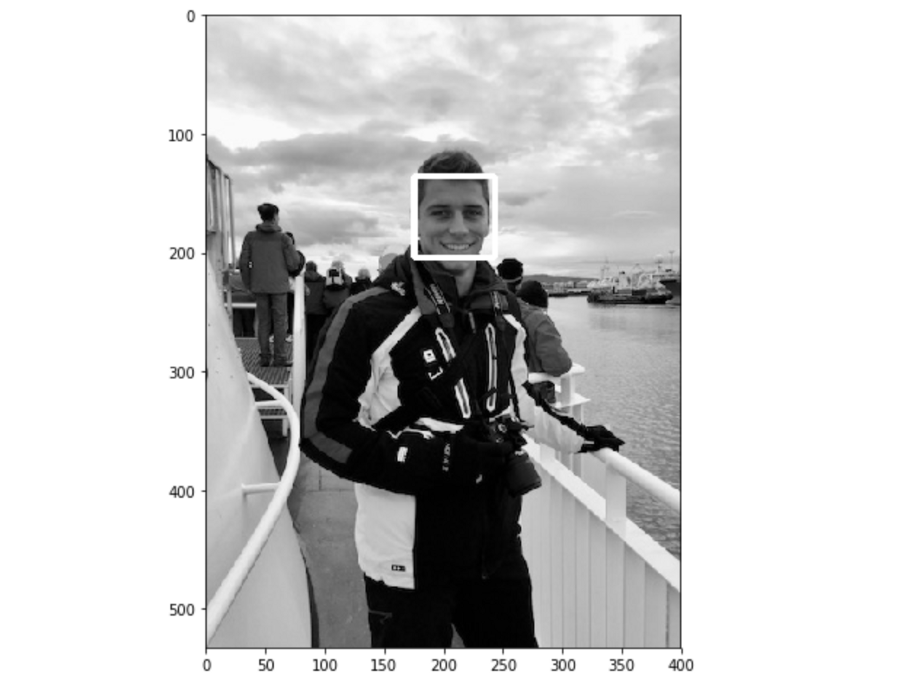
3.2检测图像上的人脸
实现过程中有一些元素发生了更改。
第一步是在这里下载预训练的模型。将权重移动到文件夹,并定义dnnDaceDetector:
dnnFaceDetector = dlib.cnn_face_detection_model_v1("mmod_human_face_detector.dat")然后,与我们目前所做的非常相似:
rects = dnnFaceDetector(gray, 1)for (i, rect) in enumerate(rects): x1 = rect.rect.left()
y1 = rect.rect.top()
x2 = rect.rect.right()
y2 = rect.rect.bottom() # Rectangle around the face
cv2.rectangle(gray, (x1, y1), (x2, y2), (255, 255, 255), 3)plt.figure(figsize=(12,8))
plt.imshow(gray, cmap='gray')
plt.show()
3.3 实时人脸检测
最后,我们将实现CNN人脸检测的实时版本:
video_capture = cv2.VideoCapture(0)
flag = 0
while True:
# Capture frame-by-frame
ret, frame = video_capture.read()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
rects = dnnFaceDetector(gray, 1)
for (i, rect) in enumerate(rects):
x1 = rect.rect.left()
y1 = rect.rect.top()
x2 = rect.rect.right()
y2 = rect.rect.bottom()
# Rectangle around the face
cv2.rectangle(frame, (x1, y1), (x2, y2), (0, 255, 0), 2)
# Display the video output
cv2.imshow('Video', frame)
# Quit video by typing Q
if cv2.waitKey(1) & 0xFF == ord('q'):
break
video_capture.release()
cv2.destroyAllWindows()
4.该选择哪一个?
这是个很难回答的问题,但我们只会讨论两个重要的指标:
计算时间
准确性
在速度方面,HOG算法似乎是最快的,其次是Haar级联分类器和CNN。
然而,Dlib中的CNN往往是最精确的算法。HOG表现得很好,但是在识别小面孔方面有一些问题。HaarCascade分类器的性能和HOG一样好。
我个人主要在我的个人项目中使用HOG,因为它可以快速的进行实时人脸检测。
结论:我希望你喜欢这个关于OpenCV和Dlib人脸检测的快速教程。如果你有任何问题/意见,请尽管提出来。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消