











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






PlaNet深度强化学习网络解析
2019年04月15日 由 sunlei 发表
803183
0
最近,迁移学习在机器学习领域非常流行。
迁移学习是谷歌、Salesforce、IBM和Azure提供的许多托管自动化服务的基础。现在,它在最新的NLP研究中占据了重要地位——出现在Google的Transformers(Bert)模型的双向编码器,出现在Sebastian Ruder和Jeremy Howard的通用语言模型文本分类微调(ULMFIT)中。
正如Sebastian在他的博客中所写的,“NLP的ImageNet时刻已经到来”。
这一切之所以成为头条新闻,是因为它们证明了预先训练的语言模型可以用于在广泛的NLP任务中实现最先进的结果。这些方法预示着一个分水岭时刻的到来:它们对NLP的广泛影响可能与预先训练的ImageNet模型对计算机视觉的影响相同。
我们也开始看到神经网络的例子,它可以使用跨领域的转移学习来处理多个任务。Paras Chopra为一个PyTorch网络提供了一个很好的教程,该网络可以基于文本描述进行图像搜索,搜索相似的图像和单词,并为图像编写标题。
目前的主要问题是:迁移学习能否在强化学习中应用?
与其他机器学习方法相比,深度强化学习因其对数据的渴求而闻名,在学习过程中容易出现不稳定(参见Deepmind关于神经网络RL的论文),在性能方面也比较落后。我们看到强化学习应用于游戏或机器人的主要领域和用例是有原因的,也就是说,可以生成大量的模拟数据的场景。
与此同时,许多人认为强化学习仍然是实现人工通用智能(AGI)的最可行的方法。然而,强化学习不断地与泛化到不同环境中的许多任务的能力相冲突——这是智能的一个关键属性。
毕竟,学习不是一件容易的事。当这些环境既需有高维度的感觉输入,又不存在进步、奖励或成功的概念,或存在极其延迟的概念时,这些强化学习主体必须处理并获得对其环境的有效表示。最重要的是,他们必须利用这些信息来总结过去的经验概况为新的情况。
到目前为止,强化学习技术和研究主要集中在个人任务的掌握上。我很想知道迁移学习是否能够帮助强化学习研究达到普遍性——所以当谷歌人工智能团队今年早些时候发布了深度规划网络(Planet)代理时,我非常兴奋。
在这个项目中,PlaNet agent的任务是“规划”一系列动作,以实现一个目标,比如平衡杆,教一个虚拟实体(人类或猎豹)走路,或者通过击打某个特定位置来保持盒子的旋转。

从最初的谷歌AI博客文章介绍PlaNet,这里有六个任务(加上与该任务相关的挑战):
这些任务之间有一些共同的目标是地球需要实现的:
那么谷歌人工智能团队是如何实现这些目标的呢?
行星AI…还有其他的?
行星人工智能以三种不同的方式与传统的强化学习背道而驰:
让我们深入研究其中的每一个差异,看看它们是如何影响模型性能的。
作者的主要决定是使用紧凑的潜在状态还是来自环境的原始感觉输入。
这里有一些权衡。使用紧凑的潜在空间意味着额外的困难,因为现在代理不仅要学习如何打败游戏,还必须理解游戏中的视觉概念——这种图像的编码和解码需要大量的计算。
使用紧凑的潜在状态空间的主要好处是,它允许代理学习更抽象的表示,比如对象的位置和速度,并且避免生成图像。这意味着实际的计划要快得多,因为代理只需要预测未来的奖励,而不需要预测图像或场景。
由于研究人员认为“潜在的动力学模型的同步训练与提供的奖励将会创建一个潜在的嵌入敏感因素的变异相关的奖励信号和对外来因素的模拟环境中使用的训练。潜伏期动力学模型现在正被更广泛地使用。”
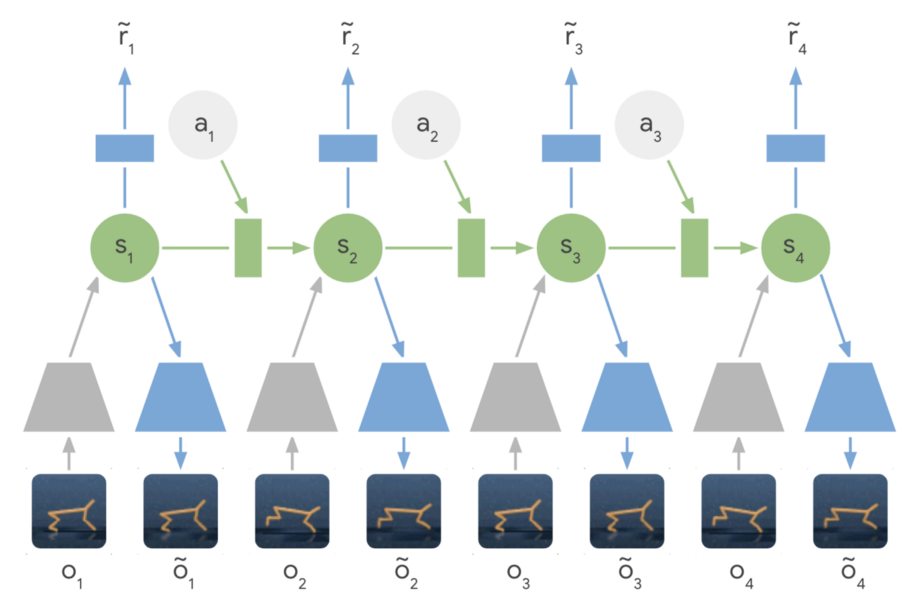
一篇优秀的论文“关于使用深层自动编码器进行有效的嵌入式强化学习”,其中写道:
在自主嵌入式系统中,减少在现实世界中采取的操作数量和学习策略所需的精力通常是至关重要的。从高维图像表示中训练增强学习代理是非常昂贵和费时的。自编码器是一种用于将高维数据(如像素化图像)压缩为较小的潜在表示的深度神经网络。

基于模型的强化学习试图让主体了解世界的一般行为。与其直接将观察结果映射到操作,这允许代理明确地提前计划,通过“想象”它们的长期结果来更仔细地选择操作。采用基于模型的方法的好处在于它的示例效率更高——这意味着它不会从头开始学习每个新任务。
观察无模型强化学习和基于模型强化学习的区别的一种方法是,看看我们是在优化最大奖励还是最小成本(无模型=最大奖励,而基于模型=最小成本)。
无模型强化学习技术(如使用策略渐变)可以是强力解决方案,最终会发现正确的操作并将其内部化为策略。策略梯度实际上必须经历一个积极的奖励,并且经常经历它,以便最终缓慢地将策略参数转向能够带来高回报的重复动作。
一个值得注意的有趣的事儿:任务类型如何影响您可能选择的方法。在Andrej Kaparthy的文章《深度强化学习:像素中的Pong》中,他描述了策略梯度能够打败人类的游戏/任务:
“在许多游戏中,策略梯度很容易击败人类。特别是,任何需要精确发挥、快速反应和不需要太多长期计划的频繁奖励信号的东西都是理想的,因为这些奖励和行动之间的短期关联可以很容易地通过方法“注意到”,可以通过策略精心完善执行。你可以在我们的Pong代理中看到这一点:它开发了一种策略,它等待球,然后快速冲刺,刚好在边缘接住球,这样就可以快速、高垂直速度地将球发射出去。重复此策略的代理将连续获得几分。在Atari的许多游戏中,深度Q学习都会以这种方式破坏人类的基本表现。如弹球、突破等。”
在第一场游戏之后,行星代理已经对引力和动力学有了初步的了解,并能够在接下来的游戏中重复使用这些知识。因此,PlaNet的效率通常是以前从零开始学习的技术的50倍。这意味着代理只需要看一个动画的五帧(实际是1/5秒的连续镜头)就能预测这个序列将如何以惊人的高准确度继续下去。在实现方面,这意味着团队不需要训练六个单独的模型就可以在任务上实现稳定的性能。
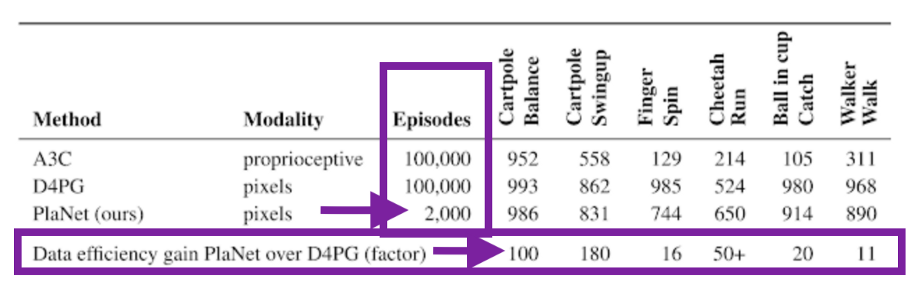
论文中写到:“Planet解决了各种各样的基于图像的控制任务, 在最终性能方面与代理先进模范自由竞争,平均数据效率提高了5000%……这些学习到的动态可以独立于任何特定的任务,因此有可能转移到其他任务的环境”。
看看PlaNet在仅有2000集的D4PG上惊人的数据效率提升吧:
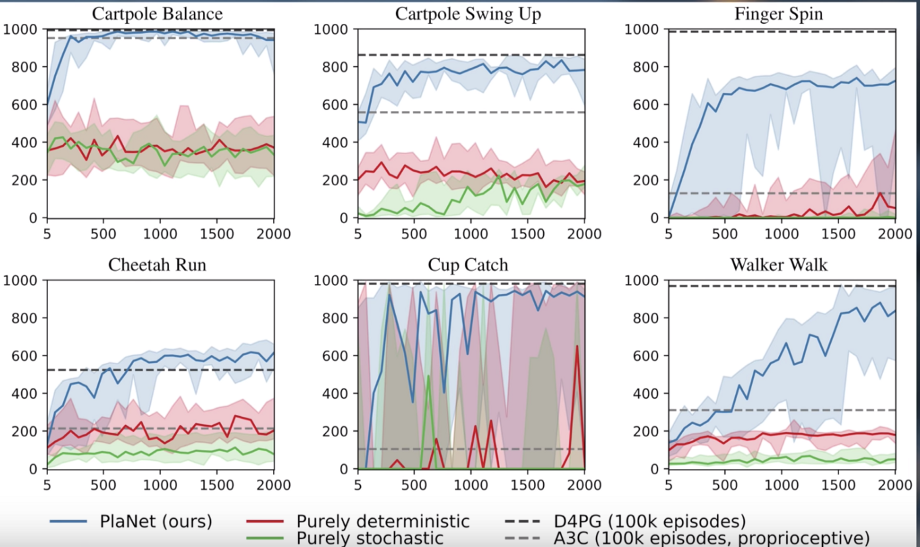
以及这些测试性能与收集的剧集数量的对比图(PlaNet用蓝色表示):
这些令人难以置信的令人兴奋的结果意味着一个数据高效和可推广的强化学习的新时代。各位看官请务必关注一点!
迁移学习是谷歌、Salesforce、IBM和Azure提供的许多托管自动化服务的基础。现在,它在最新的NLP研究中占据了重要地位——出现在Google的Transformers(Bert)模型的双向编码器,出现在Sebastian Ruder和Jeremy Howard的通用语言模型文本分类微调(ULMFIT)中。
正如Sebastian在他的博客中所写的,“NLP的ImageNet时刻已经到来”。
这一切之所以成为头条新闻,是因为它们证明了预先训练的语言模型可以用于在广泛的NLP任务中实现最先进的结果。这些方法预示着一个分水岭时刻的到来:它们对NLP的广泛影响可能与预先训练的ImageNet模型对计算机视觉的影响相同。
我们也开始看到神经网络的例子,它可以使用跨领域的转移学习来处理多个任务。Paras Chopra为一个PyTorch网络提供了一个很好的教程,该网络可以基于文本描述进行图像搜索,搜索相似的图像和单词,并为图像编写标题。
目前的主要问题是:迁移学习能否在强化学习中应用?
与其他机器学习方法相比,深度强化学习因其对数据的渴求而闻名,在学习过程中容易出现不稳定(参见Deepmind关于神经网络RL的论文),在性能方面也比较落后。我们看到强化学习应用于游戏或机器人的主要领域和用例是有原因的,也就是说,可以生成大量的模拟数据的场景。
与此同时,许多人认为强化学习仍然是实现人工通用智能(AGI)的最可行的方法。然而,强化学习不断地与泛化到不同环境中的许多任务的能力相冲突——这是智能的一个关键属性。
毕竟,学习不是一件容易的事。当这些环境既需有高维度的感觉输入,又不存在进步、奖励或成功的概念,或存在极其延迟的概念时,这些强化学习主体必须处理并获得对其环境的有效表示。最重要的是,他们必须利用这些信息来总结过去的经验概况为新的情况。
到目前为止,强化学习技术和研究主要集中在个人任务的掌握上。我很想知道迁移学习是否能够帮助强化学习研究达到普遍性——所以当谷歌人工智能团队今年早些时候发布了深度规划网络(Planet)代理时,我非常兴奋。
Behind PlaNet
在这个项目中,PlaNet agent的任务是“规划”一系列动作,以实现一个目标,比如平衡杆,教一个虚拟实体(人类或猎豹)走路,或者通过击打某个特定位置来保持盒子的旋转。
从最初的谷歌AI博客文章介绍PlaNet,这里有六个任务(加上与该任务相关的挑战):
- 手推车平衡:从一个平衡位置开始,代理必须快速识别以保持手推车向上
- 卡特波尔开关:用一个固定的摄像头,这样手推车就可以移动到看不见的地方。因此,代理必须在多个帧上吸收和记住信息。
- 手指旋转:需要预测两个独立的物体,以及它们之间的相互作用。
- 猎豹赛跑(Cheetah Run):包括与地面的接触,这些接触很难精确预测,因此需要一个能够预测多种可能未来的模型。
- 接球:只有当球被接住时才会发出稀疏的奖励信号。这就需要对遥远的未来做出准确的预测,来计划一系列精确的行动。
- 步行:模拟机器人从躺在地上开始,必须先学会站起来,然后再学会走路。
这些任务之间有一些共同的目标是地球需要实现的:
- 代理需要预测各种可能的未来(用于稳健的规划)
- 代理需要根据最近行动的结果/奖励来更新计划
- 代理需要在许多时间步骤中保留信息
那么谷歌人工智能团队是如何实现这些目标的呢?
行星AI…还有其他的?
行星人工智能以三种不同的方式与传统的强化学习背道而驰:
- 利用潜在动力学模型-行星从一系列隐藏或潜在状态而不是图像中学习,以预测未来的潜在状态。
- 基于模型的规划——Planet在没有策略网络的情况下工作,而是基于连续规划做出决策。
- 迁移学习——谷歌人工智能团队训练了一个行星代理来解决所有六个不同的任务。
让我们深入研究其中的每一个差异,看看它们是如何影响模型性能的。
1、潜在动力学模型
作者的主要决定是使用紧凑的潜在状态还是来自环境的原始感觉输入。
这里有一些权衡。使用紧凑的潜在空间意味着额外的困难,因为现在代理不仅要学习如何打败游戏,还必须理解游戏中的视觉概念——这种图像的编码和解码需要大量的计算。
使用紧凑的潜在状态空间的主要好处是,它允许代理学习更抽象的表示,比如对象的位置和速度,并且避免生成图像。这意味着实际的计划要快得多,因为代理只需要预测未来的奖励,而不需要预测图像或场景。
由于研究人员认为“潜在的动力学模型的同步训练与提供的奖励将会创建一个潜在的嵌入敏感因素的变异相关的奖励信号和对外来因素的模拟环境中使用的训练。潜伏期动力学模型现在正被更广泛地使用。”
一篇优秀的论文“关于使用深层自动编码器进行有效的嵌入式强化学习”,其中写道:
在自主嵌入式系统中,减少在现实世界中采取的操作数量和学习策略所需的精力通常是至关重要的。从高维图像表示中训练增强学习代理是非常昂贵和费时的。自编码器是一种用于将高维数据(如像素化图像)压缩为较小的潜在表示的深度神经网络。
2、基于模型的计划与无模型
基于模型的强化学习试图让主体了解世界的一般行为。与其直接将观察结果映射到操作,这允许代理明确地提前计划,通过“想象”它们的长期结果来更仔细地选择操作。采用基于模型的方法的好处在于它的示例效率更高——这意味着它不会从头开始学习每个新任务。
观察无模型强化学习和基于模型强化学习的区别的一种方法是,看看我们是在优化最大奖励还是最小成本(无模型=最大奖励,而基于模型=最小成本)。
无模型强化学习技术(如使用策略渐变)可以是强力解决方案,最终会发现正确的操作并将其内部化为策略。策略梯度实际上必须经历一个积极的奖励,并且经常经历它,以便最终缓慢地将策略参数转向能够带来高回报的重复动作。
一个值得注意的有趣的事儿:任务类型如何影响您可能选择的方法。在Andrej Kaparthy的文章《深度强化学习:像素中的Pong》中,他描述了策略梯度能够打败人类的游戏/任务:
“在许多游戏中,策略梯度很容易击败人类。特别是,任何需要精确发挥、快速反应和不需要太多长期计划的频繁奖励信号的东西都是理想的,因为这些奖励和行动之间的短期关联可以很容易地通过方法“注意到”,可以通过策略精心完善执行。你可以在我们的Pong代理中看到这一点:它开发了一种策略,它等待球,然后快速冲刺,刚好在边缘接住球,这样就可以快速、高垂直速度地将球发射出去。重复此策略的代理将连续获得几分。在Atari的许多游戏中,深度Q学习都会以这种方式破坏人类的基本表现。如弹球、突破等。”
3、迁移学习
在第一场游戏之后,行星代理已经对引力和动力学有了初步的了解,并能够在接下来的游戏中重复使用这些知识。因此,PlaNet的效率通常是以前从零开始学习的技术的50倍。这意味着代理只需要看一个动画的五帧(实际是1/5秒的连续镜头)就能预测这个序列将如何以惊人的高准确度继续下去。在实现方面,这意味着团队不需要训练六个单独的模型就可以在任务上实现稳定的性能。
论文中写到:“Planet解决了各种各样的基于图像的控制任务, 在最终性能方面与代理先进模范自由竞争,平均数据效率提高了5000%……这些学习到的动态可以独立于任何特定的任务,因此有可能转移到其他任务的环境”。
看看PlaNet在仅有2000集的D4PG上惊人的数据效率提升吧:
以及这些测试性能与收集的剧集数量的对比图(PlaNet用蓝色表示):
这些令人难以置信的令人兴奋的结果意味着一个数据高效和可推广的强化学习的新时代。各位看官请务必关注一点!

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
深度学习词汇表(三)
下一篇
Python人脸检测指南(上)








广告


写评论取消
回复取消