











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






数据虚拟化:为人工智能和机器学习解锁数据
2017年07月31日 由 yining 发表
893096
0
在可靠性、准确性和性能方面,人工智能和机器学习都严重依赖于大型设备。因为数据池越大,你就越能对模型进行训练。这就是为什么重要的数据平台能够高效地处理不同的数据流和系统,而不管数据的结构(或缺乏)、数据速度或容量。

然而,说比做容易。如今,每一个大数据平台都面临着这些系统性挑战:
1.计算/存储重叠:传统来说,计算和存储从来没有被描绘过。随着数据量的增长,你必须在计算和存储方面进行投资。
2.数据的不均匀访问:多年来,对业务操作和应用程序的过度依赖导致公司在不同的物理系统中获取、摄取和存储数据,比如文件系统、数据库(例如SQL Server或Oracle)、大数据系统(例如Hadoop)。这将导致不同的系统都有自己的访问数据的方法。
3. 硬件绑定计算:你的数据在良好的存储模式下(例如SQL Server),但是需要几个小时才能执行查询,所以你的硬件会受到限制。
4. 远程数据:数据要么分散在地理位置,要么使用不同的底层技术堆栈(如SQL Server、Oracle、Hadoop等),并存储在云中。这就要求原始数据在物理地移动以得到处理,从而增加网络的输入/输出成本。
随着人工智能和机器学习的出现,战胜这些挑战已经成为一项商业任务。数据虚拟化是基于这个前提的。
数据虚拟化提供了一些技术来使我们处理和访问数据的方式抽象化。它允许你管理和处理跨异构流和系统的数据,而不考虑它们的物理位置或格式。数据虚拟化可以定义为一组工具、技术和方法,它们可以让你访问并与数据进行交互,而不必担心其物理位置和计算所做的工作。例如,假设你有大量的数据分散在不同的系统中,并且希望以统一的方式查询所有数据,但前提是不能移动数据。
在本文中,我们将介绍一些数据虚拟化技术,并说明它们如何使大数据的处理既简单又高效。
数据虚拟化可以通过在Azure云上的高级分析栈的lambda架构师先来说明:
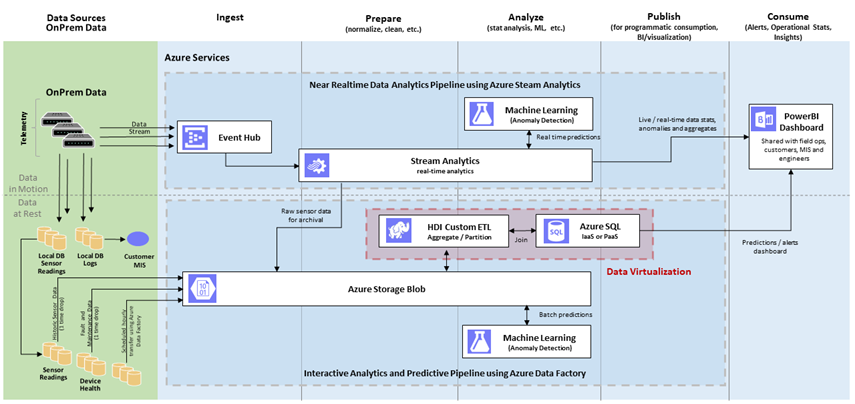
在大数据处理平台上,每秒会获取大量的数据,包括在休息和运动时的数据。然后在规范化的数据存储(例如Azure blob store)中收集这些大数据,然后进行清洗、分区、聚合,并为下游处理做好准备。下游处理的例子,比如机器学习、可视化、指示板报告生成等等。
下游处理由SQL Server支持,并且基于用户的数量—当许多查询并行地执行竞争服务时,它就会超载。为了解决这样的超载场景,数据虚拟化提供了查询扩展,其中一部分计算被卸载到更强大的系统,如Hadoop集群。
图1所示的另一个场景涉及在HDInsight(Hadoop)集群中运行的ETL过程。ETL转换可能需要访问存储在SQL Server中的引用数据。
数据虚拟化提供了混合执行,允许你从远程存储中查询引用数据,比如在SQL Server上查询。
假设你有一个多租户SQL服务器运行在硬件受限的环境中。你需要卸载一些计算以加速查询。并且你还希望访问不适合SQL Server的大数据。在这些情况下,可以使用查询横向扩展。
查询扩展使用了PolyBase技术,这是在SQL Server 2016中引入的。PolyBase允许你以更快、更高容量的大数据系统来远程执行查询的一部分,例如Hadoop集群。
查询横向扩展的架构如下所示:
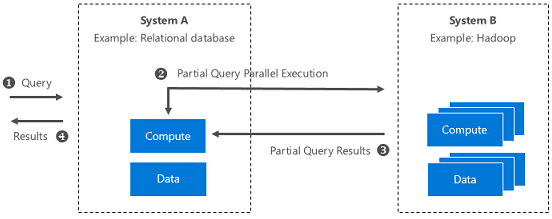
在解决方案库中使用单击自动的演示中进一步探索和部署查询横向扩展。
假设你有一个ETL过程在非结构化数据上运行,并且然后将数据存储在blob中。你需要使用存储在关系数据库中的引用数据来连接这个blob数据。那么,如何在这些不同的数据源上一致地访问数据呢? 在这种情况下,我们将使用混合执行。
混合执行允许你“将”查询“推”到远程系统,比如SQL Server,并访问引用数据。
混合执行的架构如下所示:
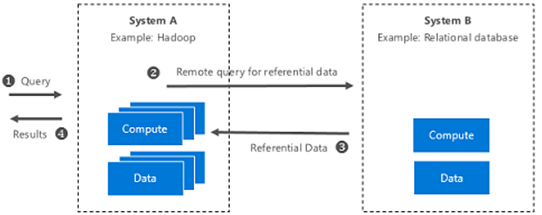
在解决方案图库中使用单击自动演示中进一步探索和部署混合执行。
你可能会问自己,使用这些技术是否值得。
当数据已经存在在Hadoop上时,查询横向扩展是有意义的。在图1中,你可能不希望只是为了看到性能的提升而将所有的数据都推到HDInsight上。
然而,我们可以想象一种情况,在HDInsight集群中发生了大量的ETL处理,并且结构化的结果被发布到SQL Server以供下游的消费(例如,通过报告工具)。为了让你了解使用这些技术可以获得的性能收益,下面展示了一些基于我们的解决方案演示中使用的数据集的基准数据。这些基准是通过改变数据集的大小和HDInsight集群的大小来产生的。
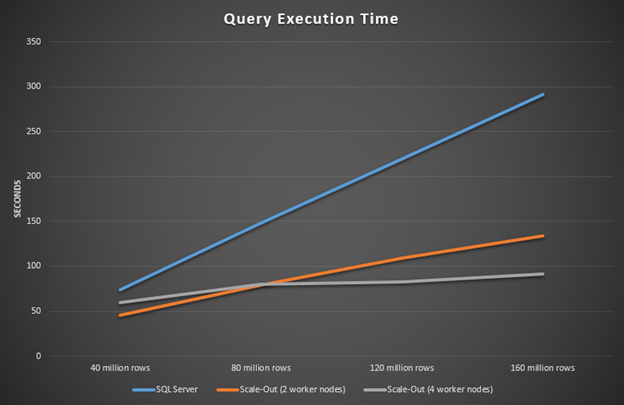
x轴显示用于基准测试的表中的行数。y轴显示查询执行的秒数。注意,执行时间内的线性增加只使用SQL Server(蓝色行),相对地,HDInsight用SQL Server来横向扩展查询执行(橙色和灰色行)。
当然,这些结果针对我们提供的解决方案演示的简化数据集和模式。SQL Server的实际数据集更大,它通常运行多个查询来争夺资源,因此可以预计将有更大幅度的性能提升。
下一个要问的问题是,何时它能变成有成本效益的,从而可以转换到使用查询横向扩展?下面的图表包含了这个实验中使用的资源的价格。你可以在这里看到详细的价格计算。
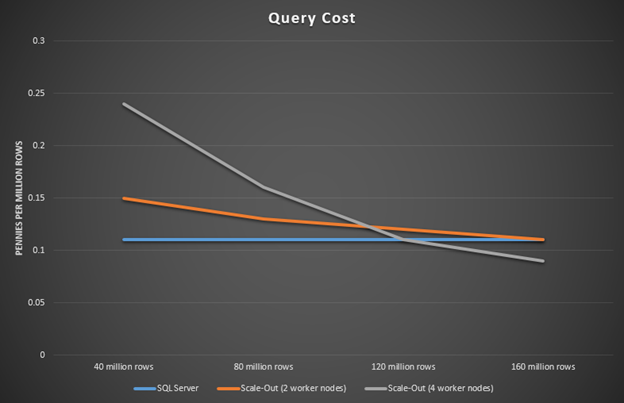
你可以看到,行数达到4000万时,在SQL Server上执行这个查询是最便宜的。但是达到1.6亿行时,横向扩展就变得更便宜了。这表明随着行数的增加,用横向扩展来运行会变得更便宜。你可以使用这些类型的基准和计算来部署资源,从而获得最佳的性能和成本平衡。
此文为编译作品,作者Robert Alexander,原网站:https://blogs.technet.microsoft.com/machinelearning/2017/06/21/data-virtualization-unlocking-data-for-ai-and-machine-learning/
然而,说比做容易。如今,每一个大数据平台都面临着这些系统性挑战:
1.计算/存储重叠:传统来说,计算和存储从来没有被描绘过。随着数据量的增长,你必须在计算和存储方面进行投资。
2.数据的不均匀访问:多年来,对业务操作和应用程序的过度依赖导致公司在不同的物理系统中获取、摄取和存储数据,比如文件系统、数据库(例如SQL Server或Oracle)、大数据系统(例如Hadoop)。这将导致不同的系统都有自己的访问数据的方法。
3. 硬件绑定计算:你的数据在良好的存储模式下(例如SQL Server),但是需要几个小时才能执行查询,所以你的硬件会受到限制。
4. 远程数据:数据要么分散在地理位置,要么使用不同的底层技术堆栈(如SQL Server、Oracle、Hadoop等),并存储在云中。这就要求原始数据在物理地移动以得到处理,从而增加网络的输入/输出成本。
随着人工智能和机器学习的出现,战胜这些挑战已经成为一项商业任务。数据虚拟化是基于这个前提的。
什么是数据虚拟化?
数据虚拟化提供了一些技术来使我们处理和访问数据的方式抽象化。它允许你管理和处理跨异构流和系统的数据,而不考虑它们的物理位置或格式。数据虚拟化可以定义为一组工具、技术和方法,它们可以让你访问并与数据进行交互,而不必担心其物理位置和计算所做的工作。例如,假设你有大量的数据分散在不同的系统中,并且希望以统一的方式查询所有数据,但前提是不能移动数据。
在本文中,我们将介绍一些数据虚拟化技术,并说明它们如何使大数据的处理既简单又高效。
数据虚拟化架构
数据虚拟化可以通过在Azure云上的高级分析栈的lambda架构师先来说明:
图1:使用Azure平台服务的Lambda架构实现
在大数据处理平台上,每秒会获取大量的数据,包括在休息和运动时的数据。然后在规范化的数据存储(例如Azure blob store)中收集这些大数据,然后进行清洗、分区、聚合,并为下游处理做好准备。下游处理的例子,比如机器学习、可视化、指示板报告生成等等。
下游处理由SQL Server支持,并且基于用户的数量—当许多查询并行地执行竞争服务时,它就会超载。为了解决这样的超载场景,数据虚拟化提供了查询扩展,其中一部分计算被卸载到更强大的系统,如Hadoop集群。
图1所示的另一个场景涉及在HDInsight(Hadoop)集群中运行的ETL过程。ETL转换可能需要访问存储在SQL Server中的引用数据。
数据虚拟化提供了混合执行,允许你从远程存储中查询引用数据,比如在SQL Server上查询。
查询横向扩展(Scale-out)
它是什么?
假设你有一个多租户SQL服务器运行在硬件受限的环境中。你需要卸载一些计算以加速查询。并且你还希望访问不适合SQL Server的大数据。在这些情况下,可以使用查询横向扩展。
查询扩展使用了PolyBase技术,这是在SQL Server 2016中引入的。PolyBase允许你以更快、更高容量的大数据系统来远程执行查询的一部分,例如Hadoop集群。
查询横向扩展的架构如下所示:
图2:查询横向扩展的系统级说明
它能解决什么问题?
- 计算/存储重叠:你可以通过在外部集群中运行查询来描绘计算。你可以通过启用HDFS中的数据来扩展SQL Server存储。
- 硬件绑定计算:你可以运行并行计算,利用更快的系统。
- 远程数据:你可以将数据保留在它的位置,只返回到处理过的结果集。
在解决方案库中使用单击自动的演示中进一步探索和部署查询横向扩展。
混合执行(Hybrid Execution)
它是什么?
假设你有一个ETL过程在非结构化数据上运行,并且然后将数据存储在blob中。你需要使用存储在关系数据库中的引用数据来连接这个blob数据。那么,如何在这些不同的数据源上一致地访问数据呢? 在这种情况下,我们将使用混合执行。
混合执行允许你“将”查询“推”到远程系统,比如SQL Server,并访问引用数据。
混合执行的架构如下所示:
图3:混合执行的系统级演示
它能解决什么问题?
- 数据的不均匀访问:你不再受数据存储的位置和数据的限制。
- 远程数据:你可以从外部系统访问引用数据,以便在下游应用程序中使用。
在解决方案图库中使用单击自动演示中进一步探索和部署混合执行。
性能基准测试:你期望得到什么样的优化收益?
你可能会问自己,使用这些技术是否值得。
当数据已经存在在Hadoop上时,查询横向扩展是有意义的。在图1中,你可能不希望只是为了看到性能的提升而将所有的数据都推到HDInsight上。
然而,我们可以想象一种情况,在HDInsight集群中发生了大量的ETL处理,并且结构化的结果被发布到SQL Server以供下游的消费(例如,通过报告工具)。为了让你了解使用这些技术可以获得的性能收益,下面展示了一些基于我们的解决方案演示中使用的数据集的基准数据。这些基准是通过改变数据集的大小和HDInsight集群的大小来产生的。
图4:在使用和不使用扩展的情况下查询执行时间
x轴显示用于基准测试的表中的行数。y轴显示查询执行的秒数。注意,执行时间内的线性增加只使用SQL Server(蓝色行),相对地,HDInsight用SQL Server来横向扩展查询执行(橙色和灰色行)。
当然,这些结果针对我们提供的解决方案演示的简化数据集和模式。SQL Server的实际数据集更大,它通常运行多个查询来争夺资源,因此可以预计将有更大幅度的性能提升。
下一个要问的问题是,何时它能变成有成本效益的,从而可以转换到使用查询横向扩展?下面的图表包含了这个实验中使用的资源的价格。你可以在这里看到详细的价格计算。
图5:查询执行时间,并且不进行扩展(定价)
你可以看到,行数达到4000万时,在SQL Server上执行这个查询是最便宜的。但是达到1.6亿行时,横向扩展就变得更便宜了。这表明随着行数的增加,用横向扩展来运行会变得更便宜。你可以使用这些类型的基准和计算来部署资源,从而获得最佳的性能和成本平衡。
此文为编译作品,作者Robert Alexander,原网站:https://blogs.technet.microsoft.com/machinelearning/2017/06/21/data-virtualization-unlocking-data-for-ai-and-machine-learning/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消