











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






可解释的机器学习:从任何机器学习模型中提取可理解的见解
2019年04月13日 由 张江 发表
700701
0
 想象一下,你是一名数据科学家,在空闲时间,你会根据自己的脸书和推特数据,预测你的朋友将在夏天去哪里度假。如果预测结果准确,可能会给你的朋友留下深刻的印象,但如果预测是错误的,除了失去作为“数据科学家”的声誉之外,无伤大雅。
想象一下,你是一名数据科学家,在空闲时间,你会根据自己的脸书和推特数据,预测你的朋友将在夏天去哪里度假。如果预测结果准确,可能会给你的朋友留下深刻的印象,但如果预测是错误的,除了失去作为“数据科学家”的声誉之外,无伤大雅。但如果现在涉及投资,比如你想投资你朋友可能度假的地方。如果模型的预测出错,你就会赔钱。只要该模型没有产生重大影响,它的可解释性就没那么重要,但是当基于模型的预测涉及到经济问题时,它就变得十分重要了。
可解释的机器学习
解释意味着以可理解的术语阐释或呈现。在机器学习系统的背景下,可解释性是向人类解释或以可理解的术语呈现的能力。
机器学习模型被许多人称为“黑匣子”。这意味着虽然我们可以从中获得准确的预测,但我们无法清楚地解释或识别这些预测背后的逻辑。但是我们如何从模型中提取重要的见解呢?要记住哪些事项以及我们需要实现哪些特征?这些是在提出模型可解释性问题时会想到的重要问题。
可解释性的重要性
一些人经常问的问题是,为什么我们不满足于模型的结果,为什么我们如此痴迷于知道机器为什么做出特定的决定?这很大程度上与模型在现实世界中可能产生的影响有关。对于仅仅用于推荐电影的模型,其影响远远小于为预测药物结果而创建的模型。
“问题在于,单一的度量标准,如分类精度,是对大多数实际任务的不完整描述。”
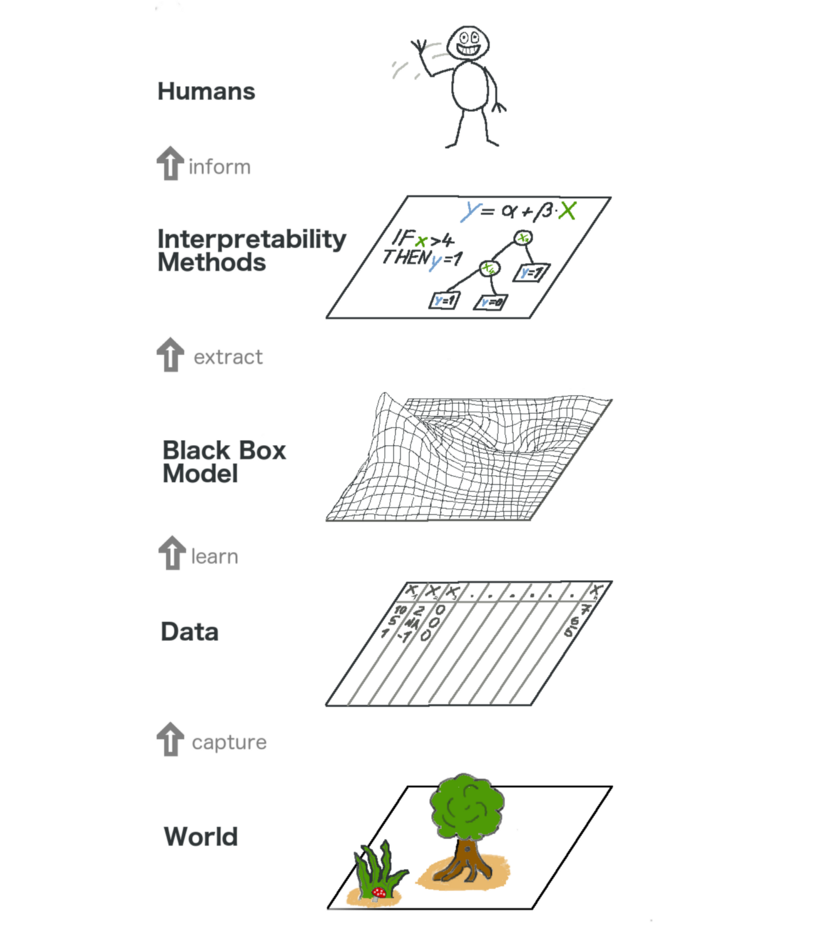
下图是可解释的机器学习的全貌。在某种程度上,我们通过收集原始数据捕获世界,并使用该数据进行进一步预测。从本质上讲,可解释性只是模型帮助人类理解过程的另一层。
可解释性带来的一些好处是:
- 可靠性
- 排除故障
- 通知特征工程
- 指导未来的数据收集
- 告知人类决策
- 建立信任关系
只要我们能将其付诸实践,理论才有意义。如果你想真正了解这个主题,可以尝试Kaggle的机器学习解释性速成课程。它具有适当数量的理论和代码,可以将概念置于透视图中,并有助于将模型可解释性概念应用于现实问题。
可从模型中提取的见解
要解释模型,我们需要以下见解:
- 模型中最重要的特征
- 对于来自模型的任何单个预测,数据中的每个特征对该特定预测的影响
- 每个特征对大量可能的预测的影响
让我们讨论一些有助于从模型中提取上述见解的技巧:
1.排列重要性
模型认为哪些特征很重要?哪些特征对模型预测的影响可能比其他特征更大?这个概念称为特征重要性,排列重要性是一种广泛用于计算特征重要性的技术。它帮助我们看到我们的模型何时产生违反直觉的结果,并且当我们的模型按照我们希望的方式工作时,它帮助我们展示其他的结果。
排列重要性适用于许多科学学习估算器。这个想法很简单:随机排列或混排验证数据集中的单个列,使所有其他列保持不变。如果模型的精度下降很多并导致误差增加,则该特征被认为是重要的。另一方面,如果对其值进行改组不会影响模型的准确性,则该特征被视为不重要。
研究
考虑一个模型,该模型基于特定的参数来预测一个足球队是否会有一名男子赢得Man of the Game,表现最好的球员将获得这个称号。
在拟合模型之后计算排列重要性。因此,让我们在训练数据上训练并拟合一个随机森林分类器模型,记作my_model。
排列重要性使用ELI5库计算。ELI5是一个Python库,允许使用统一API可视化和调试各种机器学习模型。它内置了对多个ML框架的支持,并提供了一种解释黑盒模型的方法。
使用eli5库计算并显示重要性:
(这里val_X,val_y分别表示验证集)
import eli5
from eli5.sklearn import PermutationImportance
perm = PermutationImportance(my_model, random_state=1).fit(val_X, val_y)
eli5.show_weights(perm, feature_names = val_X.columns.tolist())
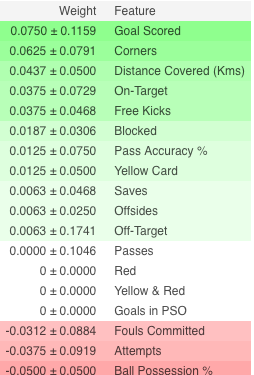
解释
- 顶部的特征最重要,底部的特征最不重要。对于这个例子,得分是最重要的特征
- ±之后的数字测量了从一次重新洗牌到下一次重组的表现
- 一些权重是负的。这是因为在那些情况下,发现混排数据的预测比实际数据更准确
实践
要获得完整的示例并测试你的理解,请单击下面的链接进入Kaggle页面:
www.kaggle.com/dansbecker/permutation-importance
2. 部分依赖图
部分依赖图(简短PDP或PD图)显示了一个或两个特征对机器学习模型的预测结果的边际效应。PDP显示特征如何影响预测。PDP可以通过1D或2D图显示目标与所选特征之间的关系。
研究
在模型拟合后也要计算PDP。在我们上面讨论的足球问题中,有很多特征,比如传球,投篮,进球等等。我们首先考虑单排。假设该排表示一个球队有50%的时间控球,传球100次,射门10次进1球。
我们继续拟合我们的模型并计算一支球队拥有一名赢得称号的球员的概率,这是我们的目标变量。接下来,我们将选择一个变量并不断改变值。例如,如果球队进1球,2球,3球等,我们将计算结果,然后绘制所有这些值,我们得到预测的结果与目标得分的图表。
用于绘制PDP的库称为python partial dependence plot toolbox或简称PDPbox。
from matplotlib import pyplot as plt
from pdpbox import pdp, get_dataset, info_plots
# Create the data that we will plot
pdp_goals = pdp.pdp_isolate(model=my_model, dataset=val_X, model_features=feature_names, feature='Goal Scored')
# plot it
pdp.pdp_plot(pdp_goals, 'Goal Scored')
plt.show()
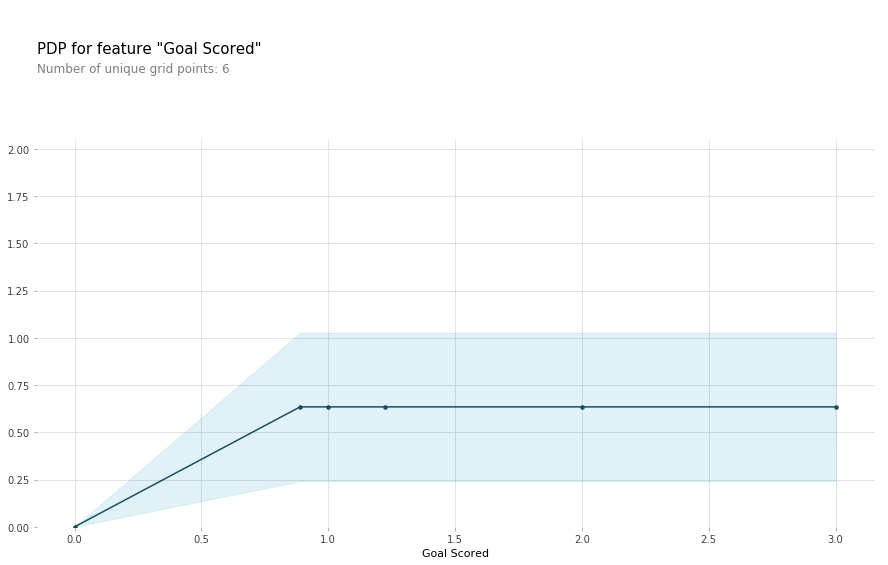
解释
- Y轴表示从基线或最左边的值预测到的变化
- 蓝色区域表示置信区间
- 对于“目标得分”图表,我们观察到得分目标会增加获得奖励的可能性,但会在一段时间内达到饱和度
我们也可以用2D局部图来可视化两个特征之间的部分依赖关系。
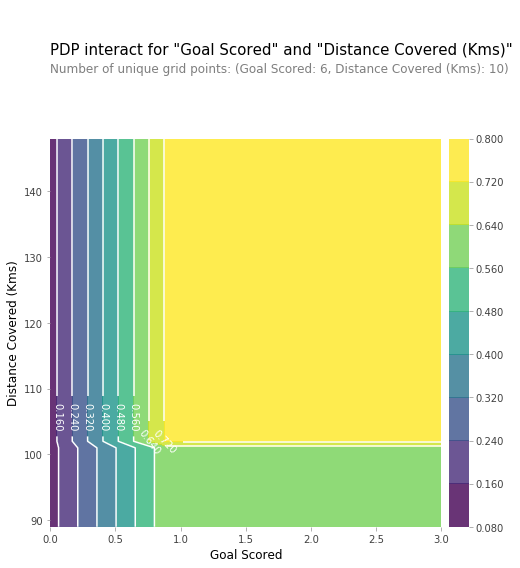
实践:www.kaggle.com/dansbecker/partial-plots
3. SHAP值
SHAP代表SHapley ADditive exPlanation,有助于细分预测以显示每个特征的影响。它基于Shapley值,这是一种用于博弈论的技术,确定协作游戏中每个玩家对其成功贡献的程度。通常情况下,在准确性和可解释性之间取得正确的权衡可能很困难,但SHAP值可以同时提供二者。
研究
再一次,与足球的示例一起,我们想要预测球队有一个赢得称号的球员的概率。SHAP值解释了对于给定特征具有特定值的影响,与我们在该特征采用某些基线值时所做的预测相比较。
SHAP值使用Shap库计算,可以从PyPI或conda轻松安装。
Shap值显示给定特征改变了我们预测的程度(与我们在该特征的某个基线值处进行预测的情况相比)。让我们说我们想知道当球队打进3球而不是某些固定基线时的预测是什么。如果我们能够回答这个问题,我们可以对其他特征执行相同的步骤,如下所示:
sum(SHAP values for all features) = pred_for_team - pred_for_baseline_values
因此,预测可以分解为下图:

解释
上面的解释显示了各自有助于将模型输出从基值(我们传递的训练数据集上的平均模型输出)推到模型输出的特征。将预测推高的特征以红色显示,推动预测更低的特征为蓝色。
- 这里的base_value是0.4979,而我们的预测值是0.7
- Goal Scored = 2对增加预测的影响最大
- ball possession特征对降低预测的影响最大
实践
深入了解SHAP值:www.kaggle.com/dansbecker/shap-values
4. SHAP值的高级用法
聚合许多SHAP值可以对模型进行更详细的了解。
SHAP摘要图
为了概述哪些特征对于模型最重要,我们可以绘制每个样本的每个特征的SHAP值。摘要图说明哪些特征最重要,以及它们对数据集的影响范围。
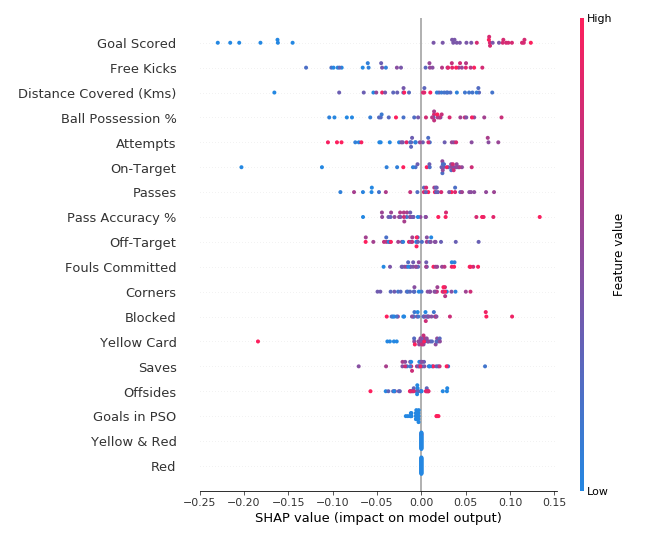
关于每个点:
- 垂直位置显示它描绘的特征
- 颜色显示该特征对于该行的数据集是高还是低
- 水平位置显示该值是否导致更高或更低的预测
左上角的点是一支进球很少的球队,将预测降低了0.25。
SHAP依赖贡献图
虽然SHAP概要图给出了每个特征的一般概述,但是依赖于SHAP的图显示了模型输出如何随特征值变化。SHAP依赖贡献图提供了与PDP类似的见解,但是它们拥有更多细节。
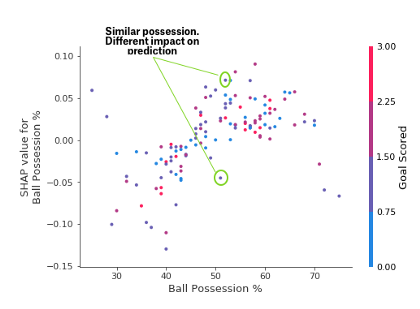
上面的依赖贡献图表明,控球可以增加球队的球员获奖的机会。但如果他们只进了一个球,这种趋势就会逆转,如果他们进的球太少,裁判可能会因为他们控球太多而惩罚他们。
实践:www.kaggle.com/dansbecker/advanced-uses-of-shap-values
结论
机器学习不再是黑匣子了。如果我们无法向其他人解释结果,那么一个好模型有什么用呢。可解释性与创建模型同样重要,为了使其被更广泛的接受,机器学习系统能够为其决策提供满意的解释至关重要。正如爱因斯坦曾说的,“如果你不能简单地解释它,你就不能理解它。”

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
可分离卷积基本介绍
下一篇
深度学习词汇表(三)








广告


写评论取消
回复取消