











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






可分离卷积基本介绍
2019年04月11日 由 sunlei 发表
256978
0
任何一个研究MobileNet架构的人无疑都会遇到可分离卷积的概念。可分离卷积是什么,它和普通卷积有什么不同?
可分离卷积有两种主要类型:空间可分离卷积和深度可分离卷积。
从概念上讲,这是两个当中比较简单的一个,并说明了将一个卷积分解成两个卷积的思想,所以我从这部分开始说起。遗憾的是,空间可分卷积有一些明显的局限性,这意味着它在深度学习中没有得到广泛的应用。
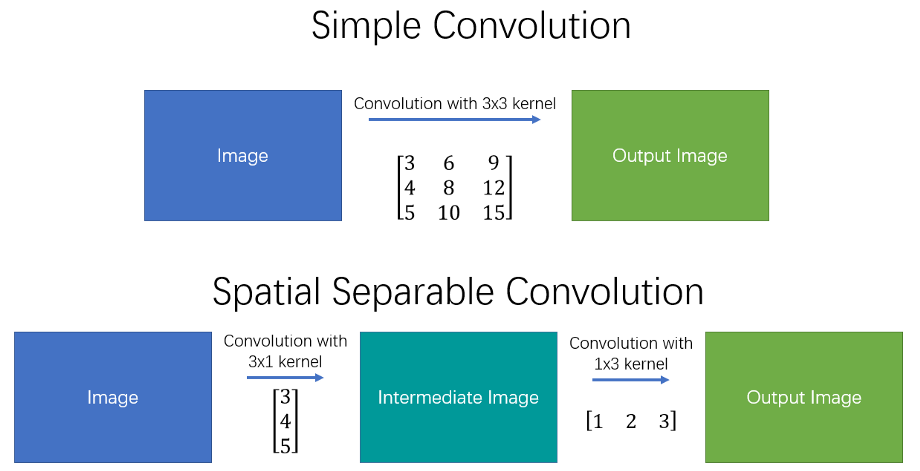
空间可分卷积之所以如此命名,是因为它主要处理图像和内核的空间维度:宽度和高度。(另一个维度,即“深度”维度,是每个图像的通道数)。
空间可分卷积只是把一个核分成两个更小的核。最常见的情况是将一个3x3内核分成一个3x1和一个1x3内核,就像这样:
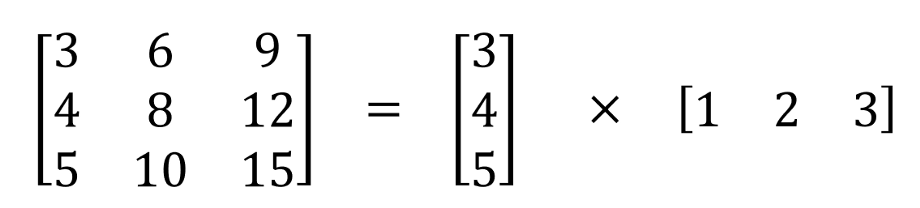
现在,我们不是用9次乘法去做一个卷积,而是做两个卷积每个卷积做3次乘法(总共6次)来达到同样的效果。乘法越少,计算复杂度越低,网络运行速度越快。
可以在空间上分离的最著名的卷积之一是Sobel内核,用于检测边缘:
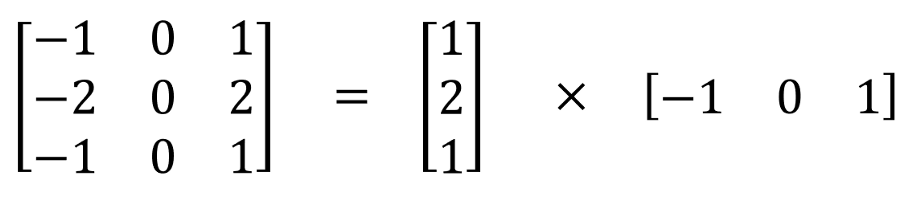
空间可分离卷积的主要问题是,并非所有的内核都可以“分离”成两个更小的内核。这在培训期间变得特别麻烦,因为在网络可能采用的所有内核中,它最终只能使用可以被分成两个较小内核的一小部分。
与空间可分卷积不同,深度可分卷积使用的内核不能“分解”成两个更小的内核。因此,它更常用。这是在keras.layers.separatibleconv2d或tf.layers.separatible_conv2d中看到的可分离卷积类型。
深度可分离卷积之所以如此命名,是因为它不仅处理空间维度,还处理深度维度-通道的数量。通常输入图像可以有3个通道:RGB。经过几次卷积后,一个图像可能有多个通道。你可以把每个频道想象成那个图像的一个特殊解释;例如,“红色”通道解释每个像素的“红色”,“蓝色”通道解释每个像素的“蓝色”,“绿色”通道解释每个像素的“绿色”。一个有64个频道的图像有64种不同的解释。
与空间可分离卷积类似,深度可分离卷积将一个核分裂成两个独立的核,分别做两个卷积:深度卷积和点向卷积。但首先,让我们看看普通卷积是如何工作的。
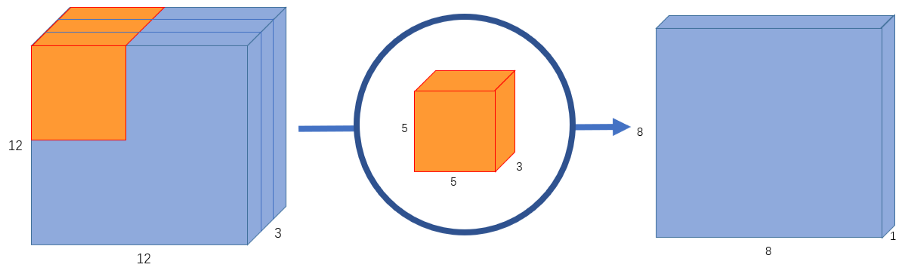
一个典型的图像不是二维的;它也有深度,宽度和高度。假设我们有一个12x12x3像素的输入图像,大小为12x12的RGB图像。
我们对图像做一个5x5的卷积,不加填充,步幅为1。如果我们只考虑图像的宽度和高度,卷积过程是这样的:12x12 - (5x5) - >8x8。5x5内核每25个像素进行标量乘法,每次输出一个数字。由于没有填充(12-5 +1 = 8),我们最终得到一个8x8像素的图像。
然而,由于图像有3个通道,卷积核也需要有3个通道。这意味着,不是做5x5=25次乘法,而是每次内核移动时做5x5x3=75次乘法。
就像二维解释一样,我们对每25个像素做标量矩阵乘法,输出一个数字。在经过5x5x3内核之后,12x12x3图像将变成8x8x1图像。
如果我们想增加输出图像中的通道数量呢?如果我们想要大小为8x8x256的输出呢?
我们可以创建256个内核来创建256个8x8x1图像,然后将它们堆叠在一起,创建出8x8x256图像输出。
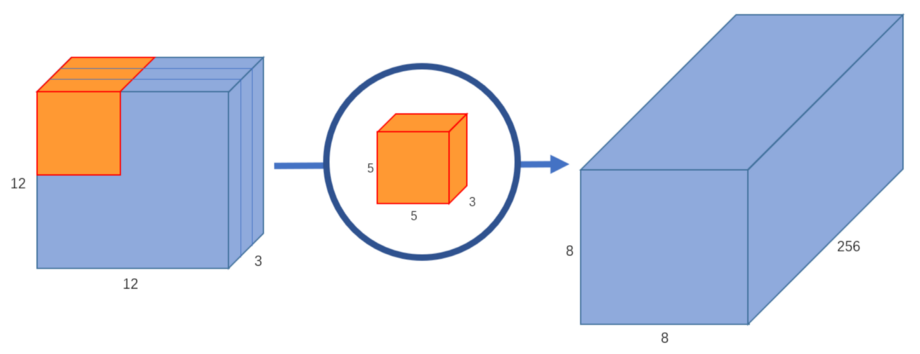
这就是正常卷积的工作原理。我喜欢把它看做一个函数:12x12x3-(5x5x3x256)->12x12x256(其中5x5x3x256表示内核的高度、宽度、输入通道数和输出通道数)。并不是说这不是矩阵乘法;我们不是将整个图像乘以内核,而是将内核移动到图像的每个部分,并分别乘以图像的小部分。
深度可分离卷积将这个过程分为两部分:深度卷积和点向卷积。
在第一部分深度卷积中,我们在不改变深度的情况下,对输入图像进行了反方向卷积。我们使用3个5x5x1形状的内核。
可以参考一下视频:https://youtu.be/D_VJoaSew7Q
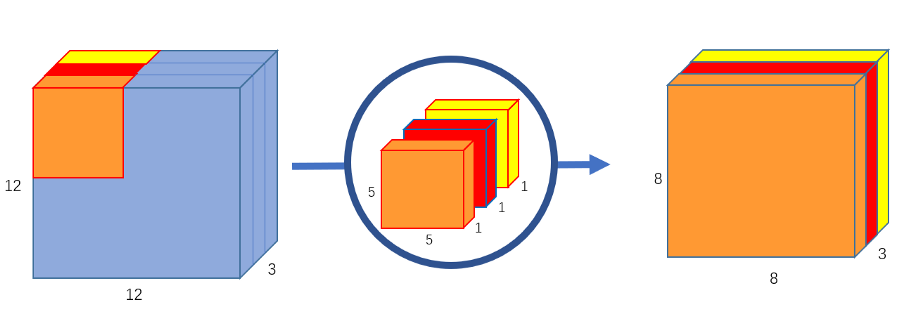
每个5x5x1内核迭代图像的1个通道(注意:1个通道,而不是所有通道),得到每25个像素组的标量积,得到一个8x8x1图像。将这些图像叠加在一起可创建8x8x3图像。
记住,原始卷积将12x12x3图像转换为8x8x256图像。目前,深度卷积已经将12x12x3图像转换为8x8x3图像。现在,我们需要增加每个图像的通道数。
点向卷积之所以如此命名是因为它使用了一个1x1内核,或者说是一个遍历每个点的内核。该内核有一个深度,不管输入图像有多少通道;在我们的例子中,它是3。因此,我们通过8x8x3图像迭代1x1x3内核,得到8x8x1图像。
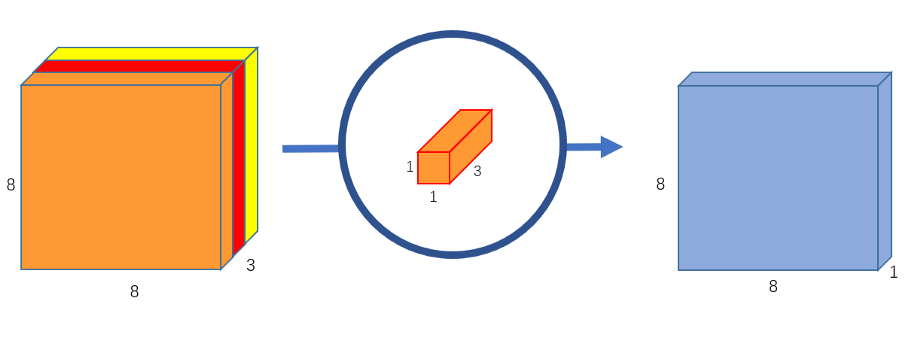
我们可以创建256个1x1x3内核,每个内核输出一个8x8x1图像,以得到形状为8x8x256的最终图像。
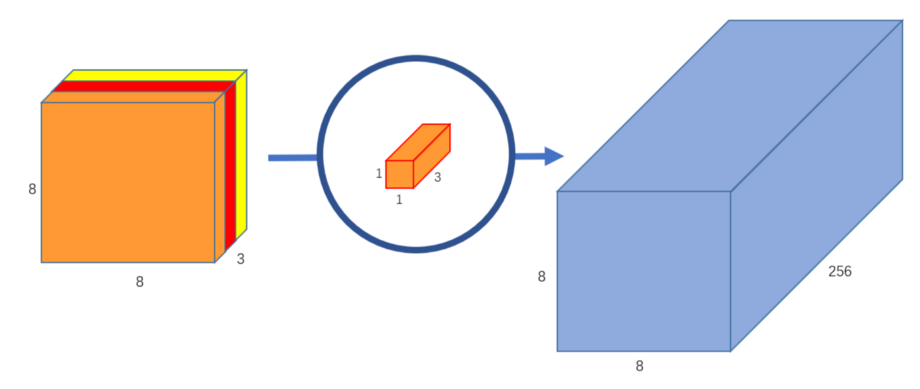
就这样!我们把卷积分解成2:深度卷积和点向卷积。更抽象地说,如果原始卷积函数是12x12x3 - (5x5x3x256)→12x12x256,我们可以将这个新的卷积表示为12x12x3 - (5x5x1x1) - > (1x1x3x256) - >12x12x256。
但是创建一个深度可分离卷积有什么意义呢?
我们来计算一下计算机在原始卷积中要做的乘法的个数。有256个5x5x3内核可以移动8x8次。这是256 x3x5x5x8x8 = 1228800乘法。
可分离卷积呢?在深度卷积中,我们有3个5x5x1的内核它们移动了8x8次。也就是3x5x5x8x8 = 4800。在点向卷积中,我们有256个1x1x3的内核它们移动了8x8次。这是256 x1x1x3x8x8 = 49152。把它们加起来,就是53952次乘法。
52,952比1,228,800小很多。计算量越少,网络就能在更短的时间内处理更多的数据。
然而,这是如何实现的呢?我第一次遇到这种解释时,我的直觉并没有真正理解它。这两个卷积不是做同样的事情吗?在这两种情况下,我们都通过一个5x5内核传递图像,将其缩小到一个通道,然后将其扩展到256个通道。为什么一个的速度是另一个的两倍多?
经过一段时间的思考,我意识到主要的区别是:在普通卷积中,我们对图像进行了256次变换。每个变换都要用到5x5x3x8x8=4800次乘法。在可分离卷积中,我们只对图像做一次变换——在深度卷积中。然后,我们将转换后的图像简单地延长到256通道。不需要一遍又一遍地变换图像,我们可以节省计算能力。
值得注意的是,在Keras和Tensorflow中,都有一个称为“深度乘数”的参数。默认设置为1。通过改变这个参数,我们可以改变深度卷积中输出通道的数量。例如,如果我们将深度乘法器设置为2,每个5x5x1内核将输出8x8x2的图像,使深度卷积的总输出(堆叠)为8x8x6,而不是8x8x3。有些人可能会选择手动设置深度乘法器来增加神经网络中的参数数量,以便更好地学习更多的特征。
深度可分离卷积是不是很棒?当然!因为它减少了卷积中参数的数量,如果你的网络已经很小,你可能会得到很少的参数,你的网络可能无法在训练中正确运作。然而,如果使用得当,它可以在适当的情况下提高效率,这使得它成为一个非常受欢迎的选择。
1x1 Kernels:
最后,由于点向卷积使用了这个概念,我想讨论一下1x1内核的用法。
一个1x1内核——或者更确切地说,n个1x1xm内核,其中n是输出通道的数量,m是输入通道的数量——可以在可分离卷积之外使用。1x1内核的一个明显目的是增加或减少图像的深度。如果你发现卷积有太多或太少的通道,1x1核可以帮助平衡它。
然而,对我来说,1x1核的主要目的是应用非线性。在神经网络的每一层之后,我们都可以应用一个激活层。无论是ReLU、PReLU、Softmax还是其他,与卷积层不同,激活层是非线性的。直线的线性组合仍然是直线。非线性层扩展了模型的可能性,这也是通常使“深度”网络优于“宽”网络的原因。为了在不显著增加参数和计算量的情况下增加非线性层的数量,我们可以应用一个1x1内核并在它之后添加一个激活层。这有助于给网络增加一层深度。
可分离卷积有两种主要类型:空间可分离卷积和深度可分离卷积。
…
空间可分离卷积
从概念上讲,这是两个当中比较简单的一个,并说明了将一个卷积分解成两个卷积的思想,所以我从这部分开始说起。遗憾的是,空间可分卷积有一些明显的局限性,这意味着它在深度学习中没有得到广泛的应用。
空间可分卷积之所以如此命名,是因为它主要处理图像和内核的空间维度:宽度和高度。(另一个维度,即“深度”维度,是每个图像的通道数)。
空间可分卷积只是把一个核分成两个更小的核。最常见的情况是将一个3x3内核分成一个3x1和一个1x3内核,就像这样:
现在,我们不是用9次乘法去做一个卷积,而是做两个卷积每个卷积做3次乘法(总共6次)来达到同样的效果。乘法越少,计算复杂度越低,网络运行速度越快。
可以在空间上分离的最著名的卷积之一是Sobel内核,用于检测边缘:
空间可分离卷积的主要问题是,并非所有的内核都可以“分离”成两个更小的内核。这在培训期间变得特别麻烦,因为在网络可能采用的所有内核中,它最终只能使用可以被分成两个较小内核的一小部分。
…
深度可分离卷积
与空间可分卷积不同,深度可分卷积使用的内核不能“分解”成两个更小的内核。因此,它更常用。这是在keras.layers.separatibleconv2d或tf.layers.separatible_conv2d中看到的可分离卷积类型。
深度可分离卷积之所以如此命名,是因为它不仅处理空间维度,还处理深度维度-通道的数量。通常输入图像可以有3个通道:RGB。经过几次卷积后,一个图像可能有多个通道。你可以把每个频道想象成那个图像的一个特殊解释;例如,“红色”通道解释每个像素的“红色”,“蓝色”通道解释每个像素的“蓝色”,“绿色”通道解释每个像素的“绿色”。一个有64个频道的图像有64种不同的解释。
与空间可分离卷积类似,深度可分离卷积将一个核分裂成两个独立的核,分别做两个卷积:深度卷积和点向卷积。但首先,让我们看看普通卷积是如何工作的。
…
普通卷积
一个典型的图像不是二维的;它也有深度,宽度和高度。假设我们有一个12x12x3像素的输入图像,大小为12x12的RGB图像。
我们对图像做一个5x5的卷积,不加填充,步幅为1。如果我们只考虑图像的宽度和高度,卷积过程是这样的:12x12 - (5x5) - >8x8。5x5内核每25个像素进行标量乘法,每次输出一个数字。由于没有填充(12-5 +1 = 8),我们最终得到一个8x8像素的图像。
然而,由于图像有3个通道,卷积核也需要有3个通道。这意味着,不是做5x5=25次乘法,而是每次内核移动时做5x5x3=75次乘法。
就像二维解释一样,我们对每25个像素做标量矩阵乘法,输出一个数字。在经过5x5x3内核之后,12x12x3图像将变成8x8x1图像。
如果我们想增加输出图像中的通道数量呢?如果我们想要大小为8x8x256的输出呢?
我们可以创建256个内核来创建256个8x8x1图像,然后将它们堆叠在一起,创建出8x8x256图像输出。
这就是正常卷积的工作原理。我喜欢把它看做一个函数:12x12x3-(5x5x3x256)->12x12x256(其中5x5x3x256表示内核的高度、宽度、输入通道数和输出通道数)。并不是说这不是矩阵乘法;我们不是将整个图像乘以内核,而是将内核移动到图像的每个部分,并分别乘以图像的小部分。
深度可分离卷积将这个过程分为两部分:深度卷积和点向卷积。
…
第1部分-深度卷积:
在第一部分深度卷积中,我们在不改变深度的情况下,对输入图像进行了反方向卷积。我们使用3个5x5x1形状的内核。
可以参考一下视频:https://youtu.be/D_VJoaSew7Q
每个5x5x1内核迭代图像的1个通道(注意:1个通道,而不是所有通道),得到每25个像素组的标量积,得到一个8x8x1图像。将这些图像叠加在一起可创建8x8x3图像。
…
第2部分-点向卷积:
记住,原始卷积将12x12x3图像转换为8x8x256图像。目前,深度卷积已经将12x12x3图像转换为8x8x3图像。现在,我们需要增加每个图像的通道数。
点向卷积之所以如此命名是因为它使用了一个1x1内核,或者说是一个遍历每个点的内核。该内核有一个深度,不管输入图像有多少通道;在我们的例子中,它是3。因此,我们通过8x8x3图像迭代1x1x3内核,得到8x8x1图像。
我们可以创建256个1x1x3内核,每个内核输出一个8x8x1图像,以得到形状为8x8x256的最终图像。
就这样!我们把卷积分解成2:深度卷积和点向卷积。更抽象地说,如果原始卷积函数是12x12x3 - (5x5x3x256)→12x12x256,我们可以将这个新的卷积表示为12x12x3 - (5x5x1x1) - > (1x1x3x256) - >12x12x256。
…
但是创建一个深度可分离卷积有什么意义呢?
我们来计算一下计算机在原始卷积中要做的乘法的个数。有256个5x5x3内核可以移动8x8次。这是256 x3x5x5x8x8 = 1228800乘法。
可分离卷积呢?在深度卷积中,我们有3个5x5x1的内核它们移动了8x8次。也就是3x5x5x8x8 = 4800。在点向卷积中,我们有256个1x1x3的内核它们移动了8x8次。这是256 x1x1x3x8x8 = 49152。把它们加起来,就是53952次乘法。
52,952比1,228,800小很多。计算量越少,网络就能在更短的时间内处理更多的数据。
然而,这是如何实现的呢?我第一次遇到这种解释时,我的直觉并没有真正理解它。这两个卷积不是做同样的事情吗?在这两种情况下,我们都通过一个5x5内核传递图像,将其缩小到一个通道,然后将其扩展到256个通道。为什么一个的速度是另一个的两倍多?
经过一段时间的思考,我意识到主要的区别是:在普通卷积中,我们对图像进行了256次变换。每个变换都要用到5x5x3x8x8=4800次乘法。在可分离卷积中,我们只对图像做一次变换——在深度卷积中。然后,我们将转换后的图像简单地延长到256通道。不需要一遍又一遍地变换图像,我们可以节省计算能力。
值得注意的是,在Keras和Tensorflow中,都有一个称为“深度乘数”的参数。默认设置为1。通过改变这个参数,我们可以改变深度卷积中输出通道的数量。例如,如果我们将深度乘法器设置为2,每个5x5x1内核将输出8x8x2的图像,使深度卷积的总输出(堆叠)为8x8x6,而不是8x8x3。有些人可能会选择手动设置深度乘法器来增加神经网络中的参数数量,以便更好地学习更多的特征。
深度可分离卷积是不是很棒?当然!因为它减少了卷积中参数的数量,如果你的网络已经很小,你可能会得到很少的参数,你的网络可能无法在训练中正确运作。然而,如果使用得当,它可以在适当的情况下提高效率,这使得它成为一个非常受欢迎的选择。
…
1x1 Kernels:
最后,由于点向卷积使用了这个概念,我想讨论一下1x1内核的用法。
一个1x1内核——或者更确切地说,n个1x1xm内核,其中n是输出通道的数量,m是输入通道的数量——可以在可分离卷积之外使用。1x1内核的一个明显目的是增加或减少图像的深度。如果你发现卷积有太多或太少的通道,1x1核可以帮助平衡它。
然而,对我来说,1x1核的主要目的是应用非线性。在神经网络的每一层之后,我们都可以应用一个激活层。无论是ReLU、PReLU、Softmax还是其他,与卷积层不同,激活层是非线性的。直线的线性组合仍然是直线。非线性层扩展了模型的可能性,这也是通常使“深度”网络优于“宽”网络的原因。为了在不显著增加参数和计算量的情况下增加非线性层的数量,我们可以应用一个1x1内核并在它之后添加一个激活层。这有助于给网络增加一层深度。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消