











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






白话机器学习算法part3
2019年04月08日 由 sunlei 发表
825790
0
在前两部分中,我们已经讨论了梯度下降、线性回归和逻辑回归,现在让我们讨论决策树和随机森林模型。
传送门:
白话机器学习算法part1
白话机器学习算法part2
决策树是一种超级简单的结构,我们每天都在头脑中使用它。这只是我们如何做决定的一种表现,就像一个“如果-这个-然后-那个”的游戏。首先,你从一个问题开始。然后写下可能的答案和一些后续问题,直到每个问题都有了答案。
让我们看一个决策树来决定某人是否应该在某一天打棒球:
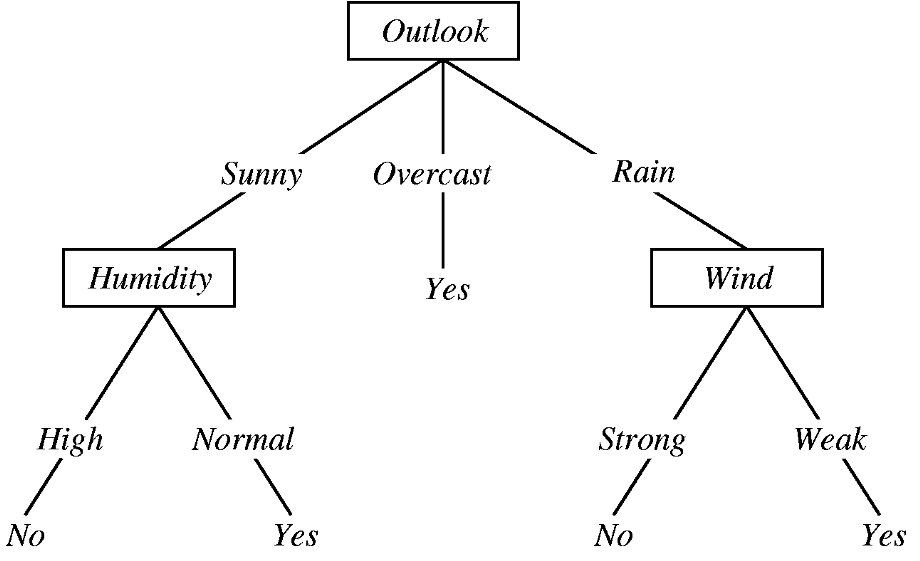
上面这棵树从一个问题开始:今天的天气状况如何?有三种可能的答案:晴天、阴天或下雨。
假如今天天气晴朗,我们就沿着“阳光明媚”的树枝走,“阳光明媚”的树枝会把我们带到“潮湿”的地方,这就会促使我们问自己,今天是高湿度的一天,还是正常的一天?假设今天湿度很高;然后,我们将跟着“高湿度”分支走,既然现在没有更多的问题要回答了,我们已经做出了最后的决定,也就是说,我们今天不应该打棒球,因为今天既晴朗又潮湿。
这就是理解决策树的全部内容!
哈哈……开个玩笑。还有一些更快捷的方法:
决策树用于建立非线性关系模型(与线性回归模型和逻辑回归模型相反)。
虽然决策树主要用于分类任务(即分类结果变量),但它可以对分类结果变量和连续结果变量进行建模。
决策树很容易理解!你可以很容易地把它们形象化,并精确地计算出在每个分裂点上发生了什么。您还可以看到哪些特性是最重要的。
决策树容易过度拟合。这是因为无论您在单个决策树中运行数据多少次,由于它只是一系列if-this-then-that语句,您最终总是会得到相同的结果。这意味着您的决策树将非常精确地匹配您的训练数据,但是当您传递新数据时,它可能无法提供有用的预测。
那么,决策树如何知道何时拆分呢?(我说的“分裂”是指形成更多的分支。)
决策树可以使用很多算法,但最流行的两种是ID3 (ID代表“迭代二分法”)和CART (CART代表“分类和回归树”)。每一种算法都使用不同的度量来决定何时拆分。ID3树使用信息获取,而CART树使用基尼指数。
我们从ID3树开始。
基本上,ID3树都是为了在最大化信息获取的过程中获得最大的回报。(正因为如此,它们也被称为贪婪的树。)
但什么是信息获取?从技术上讲,信息获取是一个使用熵作为杂质度量的标准。我们把它拆开一点。
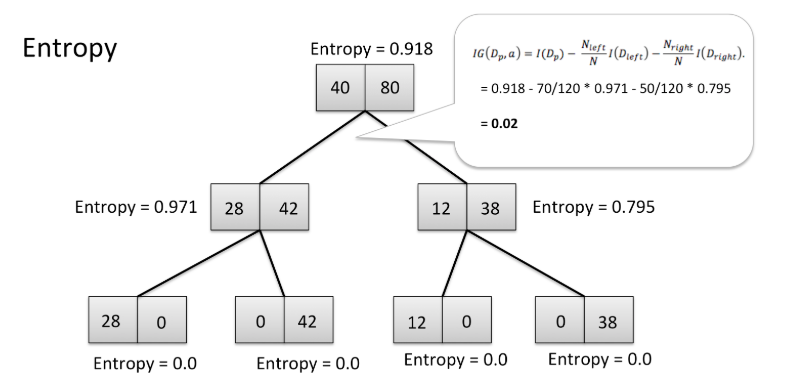
在上面的树中,你可以看到起始点的熵是0.918,而停止点的熵是0。这棵树以高信息增益和低熵结束,这正是我们想要的。
除了向低熵的方向发展,ID3树还会做出最纯粹的决定。ID3树这样做是因为它们希望每个决策尽可能清晰。低熵的东西也有高纯度。高信息增益=低熵=高纯度。
这有直观的意义——如果某件事令人困惑和混乱(即具有高熵),那么你对它的理解就是模糊的、不清晰的或不纯的。
ID3算法支持的决策树的目标是最大化每次分割的信息增益,而CART算法支持的决策树的目标是最小化基尼指数。
基尼指数基本上告诉你,从你的数据集中随机选择的数据点被错误分类的频率。在CART树中(以及生活中),我们总是希望将任何部分的错误标记数据的可能性降到最低。就是这么简单!
这些都讲得通,但是前提到的非线性的东西呢?
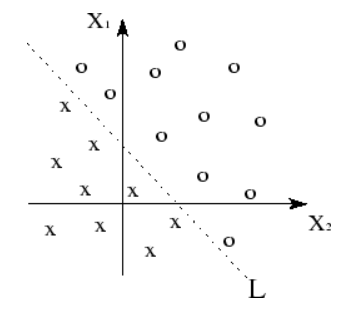
在本系列的第1部分中,我们学习了线性关系是由直线定义的。
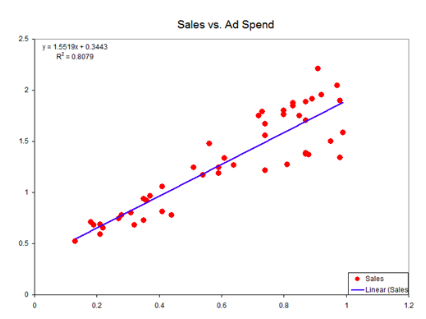
基本上,当我们可以使用直线(或线性平面)将数据点分组时,我们知道我们的数据具有某种线性,就像在最上面的图中那样。
同样,当我们用某种直线来表示变量之间的关系时,我们知道模型是线性的。这条线是线性模型下的线性函数的可视化,就像上面第二张图上的蓝线。
非线性正好与之相反。你可以用几种不同的方式来考虑非线性数据和函数:
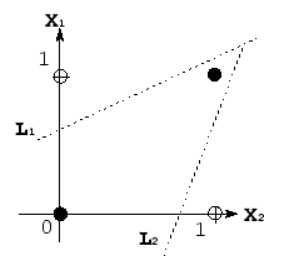
对于线性数据,您将无法可视化分割数据的线性平面。当您不能线性分离数据时,您的模型依赖于非线性函数。反过来,这意味着你的模型是非线性的!
虽然线性函数有一个恒定的斜率(因为x的微小变化导致y的微小变化),但是非线性函数没有。例如,它们的坡度可能呈指数增长。
您也可以使用与第1部分中相同的类比,但是,当您使用非线性函数工作时,自变量的微小变化会导致自变量的巨大变化或超小变化。
决策树非常擅长建模非线性关系,因为它们不依赖于线性平面来分离数据。(虽然这句话听起来很吓人,但事实并非如此——我们凭直觉就知道决策树不会线性地分离数据。您可以看看我们的树结构来证明这一点!如何将所有的“是”分成一个区域,所有的“否”分成另一个区域?你不能!)
好了,现在来看看过度拟合的问题?
因此,当您想要进行探索性分析时,决策树(无论使用哪种算法)是非常棒的。它们擅长概述数据中的重要特性,并允许您查看每个特性如何交互。然而,它们往往会与您的数据过度匹配。反过来,这意味着决策树并不擅长预测或分类他们以前从未见过的数据。
为了克服这种过度拟合,数据科学家们提出了一种称为集成模型的模型。这些模型基本上只是将许多决策树聚集在一起,并利用它们的集体力量做出能够经受住严格测试的预测。
今天就先写到这里,下一次更新就是这篇文章的最终章了。
传送门:
白话机器学习算法part1
白话机器学习算法part2
Decision Trees决策树
决策树是一种超级简单的结构,我们每天都在头脑中使用它。这只是我们如何做决定的一种表现,就像一个“如果-这个-然后-那个”的游戏。首先,你从一个问题开始。然后写下可能的答案和一些后续问题,直到每个问题都有了答案。
让我们看一个决策树来决定某人是否应该在某一天打棒球:
上面这棵树从一个问题开始:今天的天气状况如何?有三种可能的答案:晴天、阴天或下雨。
假如今天天气晴朗,我们就沿着“阳光明媚”的树枝走,“阳光明媚”的树枝会把我们带到“潮湿”的地方,这就会促使我们问自己,今天是高湿度的一天,还是正常的一天?假设今天湿度很高;然后,我们将跟着“高湿度”分支走,既然现在没有更多的问题要回答了,我们已经做出了最后的决定,也就是说,我们今天不应该打棒球,因为今天既晴朗又潮湿。
这就是理解决策树的全部内容!
哈哈……开个玩笑。还有一些更快捷的方法:
决策树用于建立非线性关系模型(与线性回归模型和逻辑回归模型相反)。
虽然决策树主要用于分类任务(即分类结果变量),但它可以对分类结果变量和连续结果变量进行建模。
决策树很容易理解!你可以很容易地把它们形象化,并精确地计算出在每个分裂点上发生了什么。您还可以看到哪些特性是最重要的。
决策树容易过度拟合。这是因为无论您在单个决策树中运行数据多少次,由于它只是一系列if-this-then-that语句,您最终总是会得到相同的结果。这意味着您的决策树将非常精确地匹配您的训练数据,但是当您传递新数据时,它可能无法提供有用的预测。
那么,决策树如何知道何时拆分呢?(我说的“分裂”是指形成更多的分支。)
决策树可以使用很多算法,但最流行的两种是ID3 (ID代表“迭代二分法”)和CART (CART代表“分类和回归树”)。每一种算法都使用不同的度量来决定何时拆分。ID3树使用信息获取,而CART树使用基尼指数。
我们从ID3树开始。
ID3树和信息获取
基本上,ID3树都是为了在最大化信息获取的过程中获得最大的回报。(正因为如此,它们也被称为贪婪的树。)
但什么是信息获取?从技术上讲,信息获取是一个使用熵作为杂质度量的标准。我们把它拆开一点。
Entropy熵
在上面的树中,你可以看到起始点的熵是0.918,而停止点的熵是0。这棵树以高信息增益和低熵结束,这正是我们想要的。
(Im)Purity
除了向低熵的方向发展,ID3树还会做出最纯粹的决定。ID3树这样做是因为它们希望每个决策尽可能清晰。低熵的东西也有高纯度。高信息增益=低熵=高纯度。
这有直观的意义——如果某件事令人困惑和混乱(即具有高熵),那么你对它的理解就是模糊的、不清晰的或不纯的。
CART Trees & The Gini Index回归树与基尼指数
ID3算法支持的决策树的目标是最大化每次分割的信息增益,而CART算法支持的决策树的目标是最小化基尼指数。
基尼指数基本上告诉你,从你的数据集中随机选择的数据点被错误分类的频率。在CART树中(以及生活中),我们总是希望将任何部分的错误标记数据的可能性降到最低。就是这么简单!
这些都讲得通,但是前提到的非线性的东西呢?
在本系列的第1部分中,我们学习了线性关系是由直线定义的。
基本上,当我们可以使用直线(或线性平面)将数据点分组时,我们知道我们的数据具有某种线性,就像在最上面的图中那样。
同样,当我们用某种直线来表示变量之间的关系时,我们知道模型是线性的。这条线是线性模型下的线性函数的可视化,就像上面第二张图上的蓝线。
非线性正好与之相反。你可以用几种不同的方式来考虑非线性数据和函数:
对于线性数据,您将无法可视化分割数据的线性平面。当您不能线性分离数据时,您的模型依赖于非线性函数。反过来,这意味着你的模型是非线性的!
虽然线性函数有一个恒定的斜率(因为x的微小变化导致y的微小变化),但是非线性函数没有。例如,它们的坡度可能呈指数增长。
您也可以使用与第1部分中相同的类比,但是,当您使用非线性函数工作时,自变量的微小变化会导致自变量的巨大变化或超小变化。
决策树非常擅长建模非线性关系,因为它们不依赖于线性平面来分离数据。(虽然这句话听起来很吓人,但事实并非如此——我们凭直觉就知道决策树不会线性地分离数据。您可以看看我们的树结构来证明这一点!如何将所有的“是”分成一个区域,所有的“否”分成另一个区域?你不能!)
好了,现在来看看过度拟合的问题?
因此,当您想要进行探索性分析时,决策树(无论使用哪种算法)是非常棒的。它们擅长概述数据中的重要特性,并允许您查看每个特性如何交互。然而,它们往往会与您的数据过度匹配。反过来,这意味着决策树并不擅长预测或分类他们以前从未见过的数据。
为了克服这种过度拟合,数据科学家们提出了一种称为集成模型的模型。这些模型基本上只是将许多决策树聚集在一起,并利用它们的集体力量做出能够经受住严格测试的预测。
今天就先写到这里,下一次更新就是这篇文章的最终章了。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
上一篇
深度学习词汇表(二)
下一篇
白话机器学习算法part4








广告


写评论取消
回复取消