











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






OpenAI发布通用语言模型GPT-2,参数量高达15亿
2019年02月15日 由 浅浅 发表
29808
0

OpenAI已经训练了一个大规模的无监督语言模型,它可以生成连贯的文本段落,在许多语言建模基准上实现最先进的表现,并执行基本的阅读理解,机器翻译,问答和总结,所有这些都没有针对特定任务的训练。
语言就是力量,对于AI研究来说,设计能够理解它的系统是一大挑战。而且,在没有手动制作的语法规则和精心标记的数据集的情况下,机器人仍然难以自然交流。
这些困难并没有阻止OpenAI的脚步,它正在推出AI模型GPT-2,模型不仅通过给定单词或句子生成连贯文本,还能在一系列NLP测试中实现最先进(或接近最先进的)性能,模型达到了 15 亿参数。
这些开创性的模型建立在OpenAI先前的研究基础之上,这表明无监督学习可用于将通用模型定向到特定的语言任务。该小组最新发表的论文认为,足够大的语言模型,在某些情况下是OpenAI之前模型大小的12倍,可以在没有特定领域的数据集或修改的情况下学习NLP任务。
模型部分通过Transformers实现了这一目标,变形金刚是一种相对新颖的神经结构类型,OpenAI模型核心的神经网络包括神经元,或在生物神经元之后松散建模的数学函数。这些神经元与“突触”连接,“突触”将信号传递给其他神经元,并且它们被分层排列。这些信号是数据的产物,或者输入到神经网络的信号,从一层传递到另一层,然后通过调整每个连接的突触强度权重来缓慢地调整网络。随着时间的推移,该网络从数据集中提取特征并识别样本间的趋势,最终学会做出预测。
Transformers加入了自我关注的组合。神经元的分组以不同的速率传输信号,并且它们在某种程度上智能地将信号路由到后续层。这种架构调整使OpenAI的模型能够查询过去的学习内容以获取相关信息,例如故事中提到的人物名称或在一个房间里的物体。
OpenAI的数据解决方案和语言研究主管Alec Radford表示,“某些AI模型被迫将有关背景的所有信息汇总或压缩到一个固定长度数学表征中,这是一项非常困难的任务,与此形成鲜明对比的是,一种基于自我关注的模型,它可以保持将所有不同单词的表示保留在背景中,并学习如何查询过去的功能。如果它看到mr或missus这样的单词,模型就可以学习如何查看文档和前面的所有单词,并找出标题后面可能出现的名称。”
OpenAI说,模型在第一次运行时,大约有一半的时间会产生有趣而连贯的文本。它试图始终以尽可能少的信息开始预测下一个词,给予它更多的背景,它表现得越好。
zero-shot
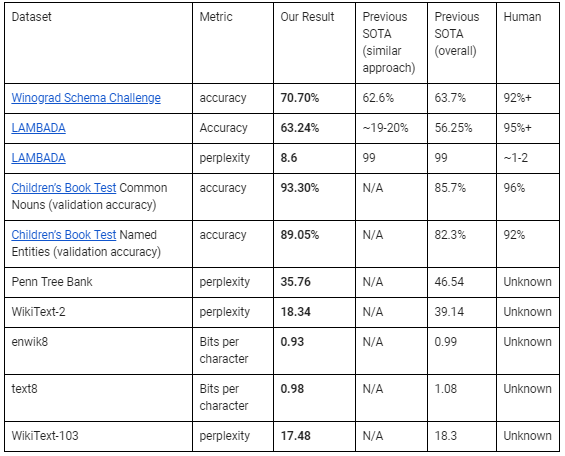
在涉及zero-shot域迁移实验中,其中模型没有事先在任何特定于测试的数据集上进行过训练,OpenAI表示其四种语言系统中最大的一个OpenAI GPT-2,在八项基准测试中的七项基准评分达到最高的分数,包括LAMBADA(测试模型在文本中模拟远程依赖的能力),Winograd模式挑战(解决文本歧义的能力的衡量标准)和Penn Treebank(数百万字的词性标记文本的集合。在某些测试中,它甚至达到了人类级别的准确性。
例如,在儿童图书测试评估系统能够捕捉不同类别单词意义的情况下,GPT-2在预测名词方面的准确率为93.3%,与人类受试者相比为96%,在预期命名时准确率为89.05%(与人类的92%相比)。
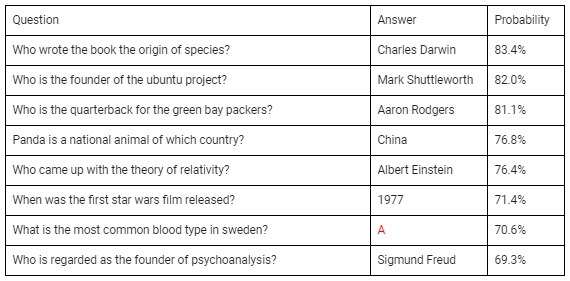
它还证明了无监督学习任务的能力。在问答测试中,提供背景信息并提出问题(“谁写了这本书的物种起源?”;“瑞典最常见的血型是什么?”;“谁提出了相对论?”),它提供回答准确率高达83.4%。
Radford表示,“它能够在所有这些领域中利用更大的模型和更多的数据,在任何一般语言预测任务中都很好。在汇总或翻译等非常有针对性的功能中,显示出有希望的初步结果。这非常令人兴奋,因为这些方法我们没有明确地训练这些任务。”
尽管如此,这还是远远不够。模型一次只能看到一页数据,而且在推理时它们并不完全一致,它们有时会捏造数字,或者以荒谬的方式切换主题。
Deepfake新闻
与传统相比,OpenAI表示它选择不发布用于训练其NLP模型的数据集,也不会发布四种语言模型中的三种或训练代码。它不会隐藏文本生成器前端,并计划将其作为人们可以直接与之交互的工具公开提供,但它认为发布其余内容可能会为滥用行为提供便利。
OpenAI表示,“大型语言模型的普遍性凸显了AI的全方位性,艺术家可以用它来帮助他们写一个简短的小说故事的同样工具,也可以用来制作关于特定公司的合成财经新闻,但种族主义,性别歧视或不具体的文本会创造假的评论,我们希望以负责任的方式宣传我们所做的事情,从而赋予其他重要性利益相关者,如记者和政策制定者,也要了解和验证我们所做的事情。”

像OpenAI的尖端语言模型这样的工具可能会被用来生成不真实或误导性的故事,2018年3月,有一半的美国人报告新闻网站上的误导信息。Gartner预测,到2022年,如果目前的趋势持续下去,发达国家的大多数人会看到更多的假信息。
人类的事实检查者不一定更好。今年,谷歌暂停了事实检查,这一标签出现在谷歌新闻的故事旁边,包括由新闻出版商和事实检查机构事实检查的信息,此前保守派出版商指责它对他们表现出偏见。
很明显,在政策领域还有很多工作要做,而OpenAI不仅要展示它在NLP中取得的令人瞩目的成就,还要引发研究人员和监管机构之间的争论。
OpenAI表示,“我们认为出版物受到一定程度的限制是技术领域的健康特征,具有变革性的社会后果,在这种情况下,我们最初是通过组织内部的粗略共识来指导的,这些结果与之前的结果存在质的差异,并且误用潜力比我们参与的先前项目更为明显。我们最终希望创建一个考虑特定类型发布的信息危害的全球AI从业者社区。”
代码:
github.com/openai/gpt-2

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消