











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






优步开源工具箱Ludwig,无需代码即可训练和测试AI模型
2019年02月12日 由 浅浅 发表
116295
0
 想要深入AI开发,但发现它的编程部分很困难?优步开源了Ludwig,这是一个基于谷歌TensorFlow框架的开源“工具箱”,允许用户在不编写代码的情况下训练和测试AI模型。
想要深入AI开发,但发现它的编程部分很困难?优步开源了Ludwig,这是一个基于谷歌TensorFlow框架的开源“工具箱”,允许用户在不编写代码的情况下训练和测试AI模型。优步表示,Ludwig是两年来在应用项目中简化AI系统部署的工作的最高点,并表示它一直在内部使用工具套件来完成很多任务,如从驾驶执照中提取信息,在驾驶员之间的对话中识别兴趣点,预测食物交付时间等。
优步表示,“对于经验丰富的机器学习开发人员和研究人员来说,Ludwig在帮助非专家更容易理解深度学习方面的能力方面是独一无二的,并且能够更快地进行模型改进迭代周期。通过使用Ludwig,专家和研究人员可以简化原型设计过程并简化数据处理,以便他们可以专注于开发深度学习架构而不是数据整理。”

正如优步解释的那样,Ludwig提供了一组AI架构,可以将它们组合在一起,为给定的用例创建端到端模型。开始训练只需要一个表格数据集文件(如CSV)和一个YAML配置文件,它指定前者的哪些列是输入要素(即观察到的各个属性或现象)以及哪些是输出目标变量。如果指定了多个输出目标变量,Ludwig会学会同时预测所有输出。
新模型定义可以包含其他信息,包括数据集中每个要素的预处理数据和模型训练参数。并且在Ludwig训练的模型被保存起来,可以在稍后的时间加载,以获得对新数据的预测。
对于Ludwig支持的每种数据类型,该工具集提供数据类型特定的编码器,其将原始数据映射到张量(线性代数中使用的数据结构),以及将张量映射到原始数据的解码器。内置组合器自动将所有输入编码器的张量拼接在一起,对其进行处理,并将它们返回以用于输出解码器。
“通过组合这些特定于数据类型的组件,用户可以在各种任务上建立Ludwig训练模型,例如,通过组合文本编码器和类别解码器,用户可以获得文本分类器,而组合图像编码器和文本解码器将使用户能够获得图像字幕模型......这种多功能且灵活的编码器-解码器架构使经验不足的深度学习从业者能够轻松地训练各种机器学习任务的模型,例如文本分类,对象分类,图像字幕,序列标记,回归,语言建模,机器翻译,时间序列预测和问答。”
此外,Ludwig还提供了一组用于训练,测试模型和获取预测的命令行实用程序;用于评估模型和通过可视化比较其预测的工具;Python编程API允许用户训练或加载模型并使用它来获取新数据的预测。此外,Ludwig能够通过使用优步的Horovod进行分布式模型训练。
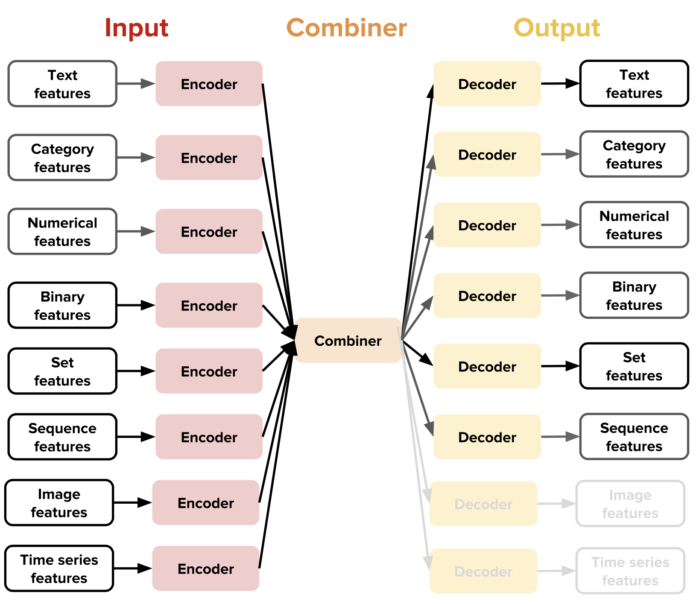
目前,Ludwig包含用于二进制值,浮点数,类别,离散序列,集合,包,图像,文本和时间序列的编码器和解码器,并且它支持选择预训练模型。
团队表示,“我们决定开源Ludwig,因为我们相信它可以成为非专家机器学习从业者和经验丰富的深度学习开发人员和研究人员的有用工具。非专家可以快速训练和测试深度学习模型,而无需编写代码。专家可以获得强大的基线来比较他们的模型,并拥有实验设置,通过执行标准数据预处理和可视化,可以轻松测试新想法和分析模型。”
未来,优步计划为文本,图像,音频,点云和图形的数据类型添加新的编码器,并集成更具可扩展性的解决方案来管理大数据集。
开源:
github.com/uber/ludwig

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消