











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






CVPR论文解读 | 商汤科技Spotlight:单目深度估计技术
2019年01月09日 由 荟荟 发表
747179
0
基于视觉的自动驾驶系统需要基于单目摄像头获取的图像,判断当前车辆与周围车辆、行人和障碍物的距离,距离判断的精度对自动驾驶系统的安全性有着决定性的影响,商汤科技在CVPR 2018发表亮点报告(Spotlight)论文,提出基于单目图像的深度估计算法,大幅度提升基于单目图像深度估计的精度,进一步提升自动驾驶系统的安全性。该论文由商汤科技见习研究员罗越在研究院研究员任思捷指导下完成。本文为商汤科技CVPR 2018论文解读第5期。
论文:Single View Stereo Matching
作者:Yue Luo, Jimmy Ren, Mude Lin, Jiahao Pang, Wenxiu Sun, Hongsheng Li, Liang
https://arxiv.org/abs/1803.02612
https://github.com/lawy623/SVS
简介
基于单目图像的深度估计算法具有方便部署、计算成本低等优点,受到了学术界和工业界日益增长的关注。现有的单目深度估计方法通常利用单一视角的图像数据作为输入,直接预测图像中每个像素对应的深度值,这种解决方案导致现有方法通常需要大量的深度标注数据,而这类数据通常需要较高的采集成本。近年来的改进思路主要是在训练过程中引入隐式的几何约束,通过几何变换,使用一侧摄像机图像(以下称右图)监督基于另一侧摄像机图像(以下称左图)预测的深度图,从而减少对数据的依赖。但这类方法在测试过程中仍然缺乏显式的几何约束。为了解决上述问题,本文提出单视图双目匹配模型(Single View Stereo Matching, SVS),该模型把单目深度估计分解为两个子过程,视图合成过程和双目匹配过程,其算法框架如图1所示。
[caption id="attachment_34709" align="aligncenter" width="720"]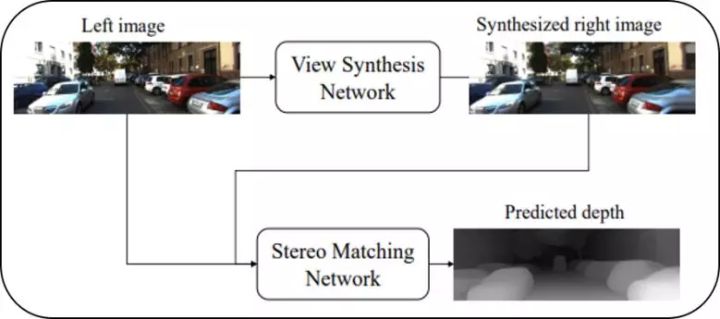 图1:单视图双目匹配模型的示意图[/caption]
图1:单视图双目匹配模型的示意图[/caption]
通过这样的分解,使得提出的模型有如下两个优点:
实验证明,本文提出的模型仅用少量的深度标注数据就可以在KITTI数据集上超过之前的所有单目深度估计方法,并首次仅靠单目图像数据就超过了双目匹配算法Block Matching的深度估计精度。
SVS模型
现有基于深度学习的单目深度估计方法,通常把CNN作为黑盒使用,学习图像块至深度值的直接映射,这类方法完全依赖高级语义信息作为预测深度的依据,尽管有些方法在损失函数上引入一些特殊的约束条件,学习这样的语义信息仍然是非常困难的。另一方面,即使这样的映射能够被成功训练,算法通常也需要大量带深度值标签的真实数据,而这类数据的采集成本非常高且耗时,极大的限制了这类技术的适用场景。
基于上述分析,本文方法提出了一种新颖的面向单目深度估计的算法框架,把单目深度估计分解为两个过程,即视图合成过程和双目匹配过程。模型的主要设计思路在于:
模型的视图合成过程由视图合成网络完成,输入一张左图,网络合成该图像对应的右图;而双目匹配过程由双目匹配网络完成,接收左图以及合成的右图,预测出左图每一个像素的视差值,详细的网络结构(如图2所示)。
[caption id="attachment_34710" align="aligncenter" width="720"]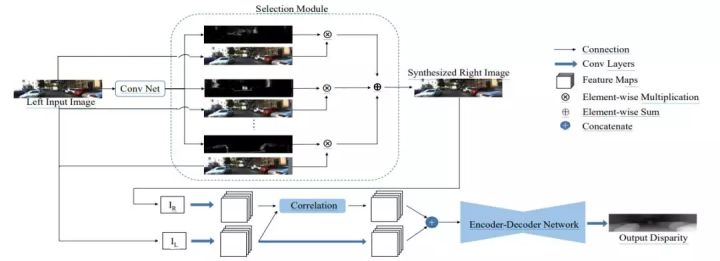 图2:算法网络结构图,上半部分网络对应视图合成网络,下半部分网络对应双目匹配网络[/caption]
图2:算法网络结构图,上半部分网络对应视图合成网络,下半部分网络对应双目匹配网络[/caption]
视图合成网络:
一般情况下,左图中的像素均可以在右图中找到匹配的像素,因此可以首先把左图平移多个不同像素距离,得到多张不同的图片,再使用神经网络预测组合系数,把多张平移后的左图和预测的系数组合得到预测的右图。具体地,视图合成网络基于Deep3D [1] 模型,图2 中的上半部分展示了视图合成网络的示意图。输入一张左图,首先主干网络对其提取不同尺度的特征,再经过上采样层把不同尺度的特征统一至同一个尺寸,然后经过累加操作融合成输出特征并预测出概率视差图,最后经过选择模块(selection module)结合概率视差图以及输入的左图,得到预测的右图。本文采用L1 损失函数训练这个网络。
双目匹配网络:
双目匹配需要把左图像素和右图中其对应像素进行匹配,再由匹配的像素差算出左图像素对应的深度,而之前的单目深度估计方法均不能显式引入类似的几何约束。由于深度学习模型的引入,双目匹配算法的性能近年来得到了极大的提升。本文的双目匹配网络基于DispNetC [2] 模型, 该模型目前在KITTI双目匹配数据集上能够达到理想的精度,其网络如图2的下半部分所示,左图以及合成的右图经过几个卷积层之后,得到的特征会经过1D相关操作(correlation)。相关操作被证明在双目匹配深度学习算法中起关键性的作用,基于相关操作,本文方法显式地引入几何约束;其得到的特征图和左图提取到的特征图进行拼接作为编码-解码网络(encoder-decoder network)的输入,并最终预测视差图。该网络的训练也同样使用L1损失函数。
实验结果
本文在KITTI公开数据集上对提出的模型进行验证,遵循Eigen等人[3]的实验设置,把697张图片作为测试图片,其余的数据作为训练图片,从定量和定性两方面对所提出的模型进行验证。
数值结果
表1总结了本文模型和其他现有方法结果的对比,可以看出,本文模型在大多数指标上均达到世界领先水平。其中,就ARD指标来说,提出的模型比之前最好的方法误差减小16.8%(0.094 vs. 0.113);表中同时也显示,经过端到端优化之后,SVS模型的性能能够进一步得到提升。
[caption id="attachment_34711" align="aligncenter" width="720"]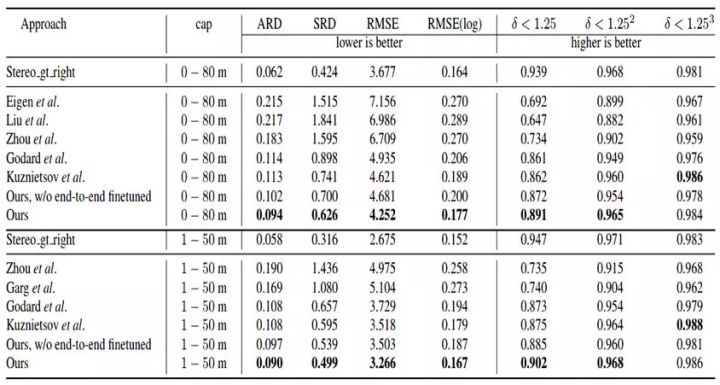 表1:KITTI数据集上SVS模型和其他方法的数值结果表中加粗表示性能最好的结果[/caption]
表1:KITTI数据集上SVS模型和其他方法的数值结果表中加粗表示性能最好的结果[/caption]
可视化结果对比
图3显示了在KITTI Eigen测试集上的深度估计结果的可视化效果,从图中可以看出本文提出的SVS模型能够得到更加精准的深度图。
[caption id="attachment_34712" align="aligncenter" width="720"] 图3:在KITTI Eigen测试集上的深度估计结果的可视化提出的SVS模型能够得到更加准确的深度图[/caption]
图3:在KITTI Eigen测试集上的深度估计结果的可视化提出的SVS模型能够得到更加准确的深度图[/caption]
在其他数据集上结果的可视化
为了验证SVS模型在其他数据集上的泛化能力,本文将在KITTI数据集上训练好的SVS模型直接应用至Cityscape和 Make3D数据集上,结果可视化效果分别展示在图4及图5中。可以看到即使在训练数据集中没有出现过的场景,本文方法仍然可以得到合理准确的深度估计结果,证实了本文方法较为强大的泛化能力。
[caption id="attachment_34713" align="aligncenter" width="720"] 图4:在Cityscape数据集上深度估计结果的可视化SVS模型能够生成理想的深度图[/caption]
图4:在Cityscape数据集上深度估计结果的可视化SVS模型能够生成理想的深度图[/caption]
[caption id="attachment_34714" align="aligncenter" width="720"] 图5:在Make3D数据集上深度估计结果的可视化本文提出的SVS模型可以得到较为准确的结果[/caption]
图5:在Make3D数据集上深度估计结果的可视化本文提出的SVS模型可以得到较为准确的结果[/caption]
与双目匹配算法Block-Matching的对比:
为了进一步确认目前性能最优异的单目深度估计方法和双目深度估计方法的差距,本文在KITTI 2015双目匹配测试集上对比了SVS模型与现有最优性能的单目深度估计方法以及双目匹配Block-Matching方法 (OCV-BM),相关结果总结在表2中,本文的SVS模型首次超越了双目匹配Block-Matching算法。
[caption id="attachment_34715" align="aligncenter" width="500"]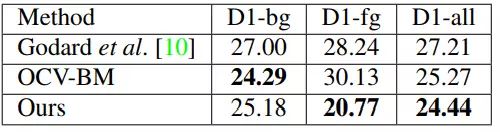 表2:在KITTI 2015双目匹配测试集上的数值结果[/caption]
表2:在KITTI 2015双目匹配测试集上的数值结果[/caption]
技术潜在应用
单目深度估计对比双目深度估计具有方便部署、成本低等优点,在很多领域有着丰富的潜在应用场景,如三维重建、增强现实等。
a) 三维重建

b) 增强现实

结论
本文提出一种简单而有效的单目深度估计模型——单视图双目匹配(SVS)。该模型通过把单目深度估计问题分解为两个子问题,即视图合成问题和双目匹配问题,避免把神经网络模型直接作为黑盒使用,提高了模型的可解释性。同时,为了更好的解决这两个子问题,显式地把几何变换编码到两个子网络中,提升网络模型的表达能力。实验结果表明,该方法仅使用少量带深度标签的训练数据,就能够超越所有之前的单目深度估计方法,并且首次仅使用单目数据就超过双目匹配算法Block-Matching的性能,在众多领域中有着丰富的潜在应用。
参考文献
[1] J. Xie, R. Girshick, and A. Farhadi. Deep3d: Fully automatic 2d-to-3d video conversion with deep convolutional neural networks. In ECCV, 2016
[2] N. Mayer, E. Ilg, P. Hausser, P. Fischer, D. Cremers, A. Dosovitskiy, and T. Brox. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In CVPR, 2016.
[3] D. Eigen, C. Puhrsch, and R. Fergus. Depth map prediction from a single image using a multi-scale deep network. In NIPS, 2014
论文:Single View Stereo Matching
作者:Yue Luo, Jimmy Ren, Mude Lin, Jiahao Pang, Wenxiu Sun, Hongsheng Li, Liang
https://arxiv.org/abs/1803.02612
https://github.com/lawy623/SVS
简介
基于单目图像的深度估计算法具有方便部署、计算成本低等优点,受到了学术界和工业界日益增长的关注。现有的单目深度估计方法通常利用单一视角的图像数据作为输入,直接预测图像中每个像素对应的深度值,这种解决方案导致现有方法通常需要大量的深度标注数据,而这类数据通常需要较高的采集成本。近年来的改进思路主要是在训练过程中引入隐式的几何约束,通过几何变换,使用一侧摄像机图像(以下称右图)监督基于另一侧摄像机图像(以下称左图)预测的深度图,从而减少对数据的依赖。但这类方法在测试过程中仍然缺乏显式的几何约束。为了解决上述问题,本文提出单视图双目匹配模型(Single View Stereo Matching, SVS),该模型把单目深度估计分解为两个子过程,视图合成过程和双目匹配过程,其算法框架如图1所示。
[caption id="attachment_34709" align="aligncenter" width="720"]
图1:单视图双目匹配模型的示意图[/caption]通过这样的分解,使得提出的模型有如下两个优点:
- 极大地减少深度标注数据的依赖;
- 在测试阶段显式地引入几何约束。
实验证明,本文提出的模型仅用少量的深度标注数据就可以在KITTI数据集上超过之前的所有单目深度估计方法,并首次仅靠单目图像数据就超过了双目匹配算法Block Matching的深度估计精度。
SVS模型
现有基于深度学习的单目深度估计方法,通常把CNN作为黑盒使用,学习图像块至深度值的直接映射,这类方法完全依赖高级语义信息作为预测深度的依据,尽管有些方法在损失函数上引入一些特殊的约束条件,学习这样的语义信息仍然是非常困难的。另一方面,即使这样的映射能够被成功训练,算法通常也需要大量带深度值标签的真实数据,而这类数据的采集成本非常高且耗时,极大的限制了这类技术的适用场景。
基于上述分析,本文方法提出了一种新颖的面向单目深度估计的算法框架,把单目深度估计分解为两个过程,即视图合成过程和双目匹配过程。模型的主要设计思路在于:
- 把双目深度估计模型中有效的几何约束显式地结合到单目深度估计模型中,提高模型的可解释性;
- 减少使用难以采集的真实深度数据,从而扩大模型的适用范围;
- 整个模型以端到端的的方式训练,从而提升深度估计准确性。
模型的视图合成过程由视图合成网络完成,输入一张左图,网络合成该图像对应的右图;而双目匹配过程由双目匹配网络完成,接收左图以及合成的右图,预测出左图每一个像素的视差值,详细的网络结构(如图2所示)。
[caption id="attachment_34710" align="aligncenter" width="720"]
图2:算法网络结构图,上半部分网络对应视图合成网络,下半部分网络对应双目匹配网络[/caption]视图合成网络:
一般情况下,左图中的像素均可以在右图中找到匹配的像素,因此可以首先把左图平移多个不同像素距离,得到多张不同的图片,再使用神经网络预测组合系数,把多张平移后的左图和预测的系数组合得到预测的右图。具体地,视图合成网络基于Deep3D [1] 模型,图2 中的上半部分展示了视图合成网络的示意图。输入一张左图,首先主干网络对其提取不同尺度的特征,再经过上采样层把不同尺度的特征统一至同一个尺寸,然后经过累加操作融合成输出特征并预测出概率视差图,最后经过选择模块(selection module)结合概率视差图以及输入的左图,得到预测的右图。本文采用L1 损失函数训练这个网络。
双目匹配网络:
双目匹配需要把左图像素和右图中其对应像素进行匹配,再由匹配的像素差算出左图像素对应的深度,而之前的单目深度估计方法均不能显式引入类似的几何约束。由于深度学习模型的引入,双目匹配算法的性能近年来得到了极大的提升。本文的双目匹配网络基于DispNetC [2] 模型, 该模型目前在KITTI双目匹配数据集上能够达到理想的精度,其网络如图2的下半部分所示,左图以及合成的右图经过几个卷积层之后,得到的特征会经过1D相关操作(correlation)。相关操作被证明在双目匹配深度学习算法中起关键性的作用,基于相关操作,本文方法显式地引入几何约束;其得到的特征图和左图提取到的特征图进行拼接作为编码-解码网络(encoder-decoder network)的输入,并最终预测视差图。该网络的训练也同样使用L1损失函数。
实验结果
本文在KITTI公开数据集上对提出的模型进行验证,遵循Eigen等人[3]的实验设置,把697张图片作为测试图片,其余的数据作为训练图片,从定量和定性两方面对所提出的模型进行验证。
数值结果
表1总结了本文模型和其他现有方法结果的对比,可以看出,本文模型在大多数指标上均达到世界领先水平。其中,就ARD指标来说,提出的模型比之前最好的方法误差减小16.8%(0.094 vs. 0.113);表中同时也显示,经过端到端优化之后,SVS模型的性能能够进一步得到提升。
[caption id="attachment_34711" align="aligncenter" width="720"]
表1:KITTI数据集上SVS模型和其他方法的数值结果表中加粗表示性能最好的结果[/caption]可视化结果对比
图3显示了在KITTI Eigen测试集上的深度估计结果的可视化效果,从图中可以看出本文提出的SVS模型能够得到更加精准的深度图。
[caption id="attachment_34712" align="aligncenter" width="720"]
图3:在KITTI Eigen测试集上的深度估计结果的可视化提出的SVS模型能够得到更加准确的深度图[/caption]在其他数据集上结果的可视化
为了验证SVS模型在其他数据集上的泛化能力,本文将在KITTI数据集上训练好的SVS模型直接应用至Cityscape和 Make3D数据集上,结果可视化效果分别展示在图4及图5中。可以看到即使在训练数据集中没有出现过的场景,本文方法仍然可以得到合理准确的深度估计结果,证实了本文方法较为强大的泛化能力。
[caption id="attachment_34713" align="aligncenter" width="720"]
图4:在Cityscape数据集上深度估计结果的可视化SVS模型能够生成理想的深度图[/caption][caption id="attachment_34714" align="aligncenter" width="720"]
图5:在Make3D数据集上深度估计结果的可视化本文提出的SVS模型可以得到较为准确的结果[/caption]与双目匹配算法Block-Matching的对比:
为了进一步确认目前性能最优异的单目深度估计方法和双目深度估计方法的差距,本文在KITTI 2015双目匹配测试集上对比了SVS模型与现有最优性能的单目深度估计方法以及双目匹配Block-Matching方法 (OCV-BM),相关结果总结在表2中,本文的SVS模型首次超越了双目匹配Block-Matching算法。
[caption id="attachment_34715" align="aligncenter" width="500"]
表2:在KITTI 2015双目匹配测试集上的数值结果[/caption]技术潜在应用
单目深度估计对比双目深度估计具有方便部署、成本低等优点,在很多领域有着丰富的潜在应用场景,如三维重建、增强现实等。
a) 三维重建
b) 增强现实
结论
本文提出一种简单而有效的单目深度估计模型——单视图双目匹配(SVS)。该模型通过把单目深度估计问题分解为两个子问题,即视图合成问题和双目匹配问题,避免把神经网络模型直接作为黑盒使用,提高了模型的可解释性。同时,为了更好的解决这两个子问题,显式地把几何变换编码到两个子网络中,提升网络模型的表达能力。实验结果表明,该方法仅使用少量带深度标签的训练数据,就能够超越所有之前的单目深度估计方法,并且首次仅使用单目数据就超过双目匹配算法Block-Matching的性能,在众多领域中有着丰富的潜在应用。
参考文献
[1] J. Xie, R. Girshick, and A. Farhadi. Deep3d: Fully automatic 2d-to-3d video conversion with deep convolutional neural networks. In ECCV, 2016
[2] N. Mayer, E. Ilg, P. Hausser, P. Fischer, D. Cremers, A. Dosovitskiy, and T. Brox. A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation. In CVPR, 2016.
[3] D. Eigen, C. Puhrsch, and R. Fergus. Depth map prediction from a single image using a multi-scale deep network. In NIPS, 2014

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消