











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






TensorFlow推出优化工具包:模型缩小4倍,速度提高3倍
2018年09月19日 由 浅浅 发表
269769
0

TensorFlow中引入一个新的优化工具包:一套让开发人员,无论是新手还是高手,都可以用来优化机器学习模型以进行部署和执行的技术。
虽然这些技术对于优化任何TensorFlow模型进行部署非常有用,但对于在内存严重,功耗限制和存储限制的设备上提供模型的TensorFlow Lite开发人员来说,它们尤为重要。

优化模型以减少尺寸、延迟和功率,使其在精度上可以忽略不计。
添加支持的第一种技术是TensorFlow Lite转换工具的训练后量化。对于相关的机器学习模型,这可以达到高达4倍的压缩和高达3倍的执行速度。
通过量化模型,开发人员还将获得降低功耗的额外好处。这对于在移动电话之外的边缘设备中的部署是有用的。
启用训练后量化(post-training quantization)
训练后量化技术已集成到TensorFlow Lite转换工具中。入门很简单:在构建TensorFlow模型之后,开发人员可以在TensorFlow Lite转换工具中启用“post_training_quantize”标志。假设保存的模型存储在saved_model_dir中,可以生成量化的tflite flatbuffer:
converter=tf.contrib.lite.TocoConverter.from_saved_model(saved_model_dir)
converter.post_training_quantize=True
tflite_quantized_model=converter.convert()
open(“quantized_model.tflite”, “wb”).write(tflite_quantized_model)
教程将指导您深入了解如何执行此操作。在未来,团队目标是将此技术整合到通用TensorFlow工具中,以便可以在TensorFlow Lite当前不支持的平台上进行部署。
训练后量化的好处:
- 模型尺寸缩小4倍
- 模型主要由卷积层组成,执行速度提高10-50%
- 基于RNN的模型可以提高3倍的速度
- 由于减少了内存和计算要求,我们预计大多数型号的功耗也会降低
有关少数型号的模型尺寸缩短和执行时间加速,请参见下图(使用单核心在Android Pixel 2手机上进行测量)。
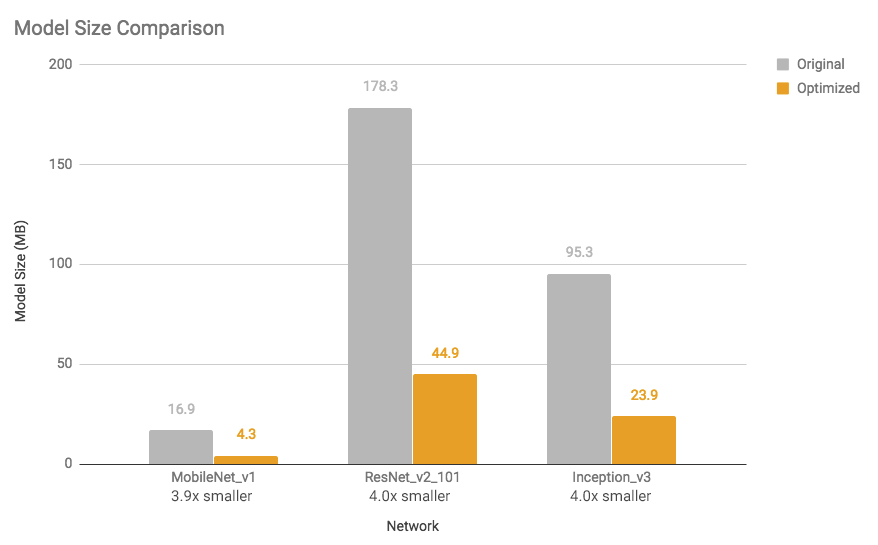
图1:模型尺寸比较:优化的模型几乎缩小了4倍
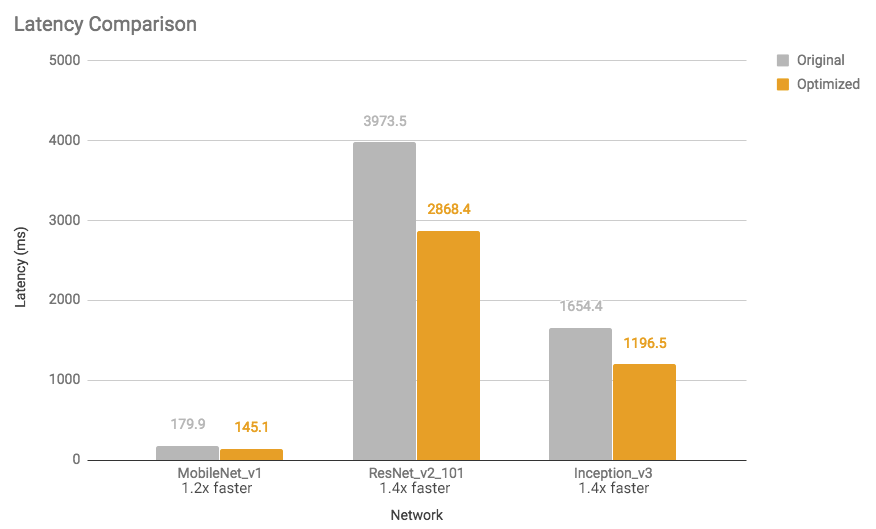
图2:延迟比较:优化模型的速度提高了1.2到1.4倍
这些加速和模型尺寸的减小对精度影响很小。通常,对于手头任务来说已经很小的模型(例如,用于图像分类的mobilenet v1)可能会损失更多的准确性。对于这些模型,团队提供预先训练的全量化模型。
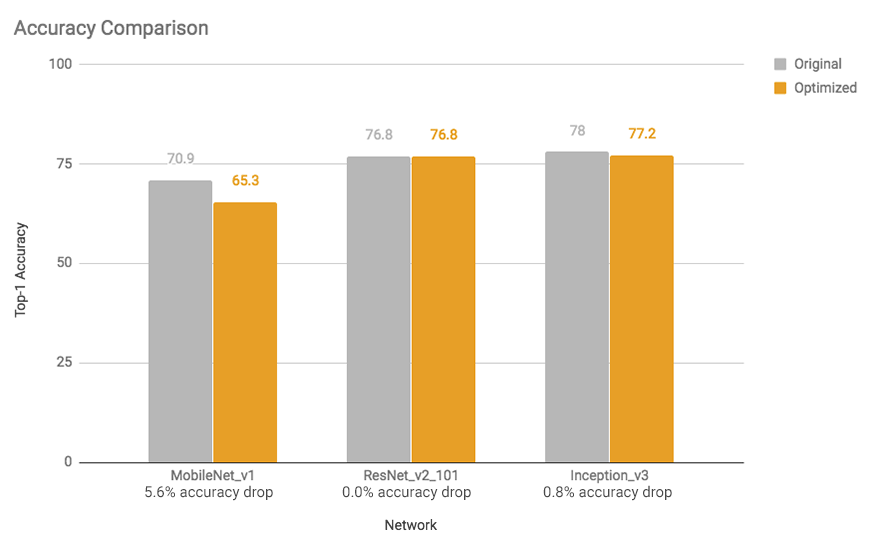
图3:精度比较:除移动网络外,优化模型的精度下降可忽略不计
团队希望将来继续改进结果,因此请参阅模型优化指南以获取最新测量结果。
训练后量化如何工作
在下层,我们通过将参数(即神经网络权重)的精度从训练时间32位浮点表示降低到更小更有效的8位整数表示来运行优化(也称为量化)。有关详细信息,请参阅培训后量化指南。(www.tensorflow.org/performance/post_training_quantization)
这些优化将确保将结果模型中的精度降低的操作定义与使用固定和浮点数学混合的内核实现配对。这将以较低的精度快速执行最重的计算,但是最敏感的计算具有更高的精度,因此通常导致任务的最终精度损失很小甚至不损失,但是相对于纯浮点执行而言显着加速。对于没有匹配的“混合”内核的操作,或者工具包认为必要的操作,它会将参数重新转换为更高的浮点精度以便执行。请参阅培训后量化页面以获取支持的混合操作列表。
未来的研究
团队将继续改进训练后量化以及其他技术,以便更容易地优化模型。这些将集成到相关的TensorFlow工作流程中,使其易于使用。
训练后量化是正在开发的优化工具包的第一个产品。团队期待得到开发者的反馈。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消