











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






DeepMind开发PopArt:单一智能体在多任务环境中超越人类
2018年09月14日 由 浅浅 发表
668916
0

多任务学习,即允许单个代理学习如何解决许多不同的任务,这是AI研究的长期目标。最近有一些新的进展,像DQN这样的代理能够使用相同的算法学习玩多种游戏,包括Breakout和Pong。这些算法用于为每项任务训练各个专家代理。随着AI研究向更复杂的现实世界领域发展,建立一个单一的总代理,而不是多个专家代理,来学习执行多个任务将是至关重要的。然而,这是一项重大的挑战。
一个原因是强化学习智能体用来判断成功的奖励量表通常存在差异,导致他们专注于奖励高的任务。例如,在Atari游戏Pong中,智能体每步获得-1,0或+1的奖励。相比之下,玩Ms. Pac-Man(吃豆人)的智能体可以一步获得数百或数千个积分。即使个人奖励的规模相当,但随着智能体变得更好,奖励的频率也会随着时间而变化。这意味着智能体倾向于关注那些分数较高的任务,从而在某些任务上获得更好的表现,而在其他任务上则更差。
为了解决这些问题,DeepMind开发了PopArt,这种技术可以调整每个游戏中的得分等级,因此无论每个特定游戏中可用的奖励规模如何,智能体都会判断游戏具有相同的学习价值。团队将PopArt规范化应用于最先进的强化学习智能体,从而形成一个单独的智能体,可以玩57种不同的Atari视频游戏,在整个集合中表现高于人类的中等水平。
从广义上讲,深度学习依赖于正在更新的神经网络的权重,以使其输出更接近所需的目标输出。当在深度强化学习的背景下使用神经网络时,这也适用。PopArt通过估计这些目标的平均值和传播(例如游戏中的得分)来工作。然后,在使用这些统计信息来更新网络权重之前,它会使用这些统计信息对其进行标准化。使用标准化目标可以使学习对规模和班次的变化更具鲁棒性。为了获得准确的估计,例如预期的未来分数,然后可以通过逆转标准化过程将网络的输出重新调整回真实的目标范围。如果单纯地完成,每次更新统计数据都会改变所有非标准化输出,包括已经非常好的那些。每当更新统计数据时,都会通过在相反方向更新网络来防止这种情况发生,这可以完全按照这种方式完成。这意味着可以获得大规模更新的好处,同时保持先前学习的输出不变。出于这些原因,这种方法叫做PopArt:它的工作原理是精确地保持输出,同时适应性地调整目标。
PopArt作为修剪奖励的替代方案
传统上,研究人员通过在强化学习算法中使用奖励修剪来克服不同奖励量表的问题。这会将大小分数修剪为1或-1,大致标准化预期的奖励。虽然这使学习更容易,但它也改变了智能体的目标。例如,Ms. Pac-Man的目标是收集颗粒,每个颗粒每个值10分,并且吃掉价值在200到1600点之间的幽灵。通过修剪奖励,智能体在吃颗粒或吃幽灵之间没有明显差异,导致只吃颗粒的智能体,并且不会再追逐幽灵,如以下视频所示:
[video width="640" height="420" mp4="https://www.atyun.com/uploadfile/2018/09/clipped_pacman_dvd.mp4"][/video]
当删除奖励修剪并使用PopArt的自适应标准化来稳定学习时,它会导致完全不同的行为,智能体追逐幽灵,并获得更高的分数,如本视频所示:
[video width="1920" height="1080" mp4="https://www.atyun.com/uploadfile/2018/09/Unclipped-rewards-using-PopArt.mp4"][/video]
使用PopArt进行多任务深度强化学习
我们将PopArt应用于Importance-weighted Actor-Learner Architecture(IMPALA),这是DeepMind中最常用的深度强化学习智能体之一。在我们的实验中,与没有PopArt的基线智能体相比,PopArt大大提高了智能体的性能。两者都有修剪和未修剪的奖励,PopArt智能体在游戏中的中位数得分高于人类中位数。这比修剪奖励的基线要高得多,而具有未修剪奖励的基线根本无法达到有意义的表现,因为它无法有效地处理游戏中奖励量表的巨大变化。
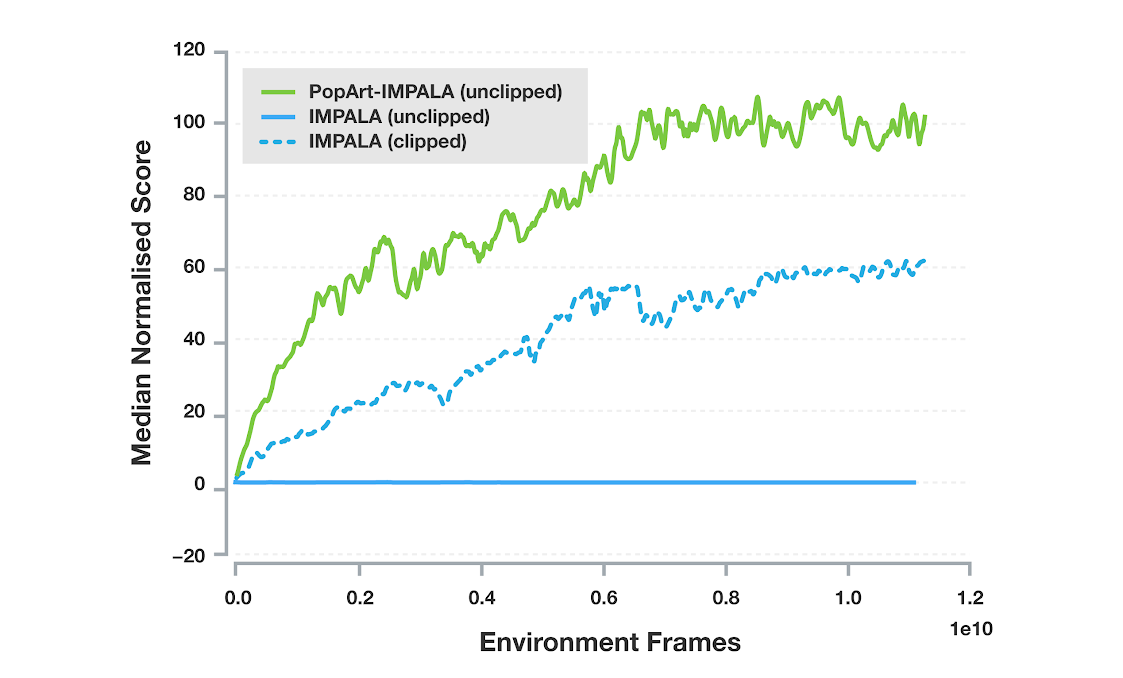
57个Atari游戏的标准化表现中位数。每一行对应于单个智能体的中位数性能,该智能体经过训练以使用相同的神经网络来玩所有这些游戏。实线表示使用奖励修剪的位置。虚线表示使用未修剪的奖励。
这是团队第一次在使用单一智能体的这种多任务环境中实现超越人类的表现,这表明PopArt可以为开放式研究问题提供一些答案,比如如何在不手动修剪或缩放奖励的情况下平衡各种目标。当AI应用于更复杂的多模态域时,其能够在学习过程中自动适应规范化的能力变得非常重要,其中智能体必须学会利用不同的奖励来权衡各种不同的目标。
论文:arxiv.org/abs/1809.04474

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消