











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






tf.estimator示例:多GPU高效训练深度学习模型
2018年09月17日 由 yuxiangyu 发表
845926
0

在Zalando研究所,与大多数人工智能研究部门一样,我们意识到尝试和快速成型思想的重要性。随着数据集越来越大,了解如何在共享资源上快速高效地训练深度学习模型就变得非常有用。TensorFlow的Estimators API可用于在具有多GPU的分布式环境中训练模型。在这里,我们将通过训练一个使用tf.keras编写的自定义Estimators来展示这个工作流程(在这里数据集使用小型的Fashion-MNIST),并在最后展示更实用的用例。
注意:TensorFlow团队一直在努力开发一个新的功能(在撰写本文时仍处于开发状态),可让你训练tf.keras模型而无需先将其转换为Estimator,只需几行额外的代码!那个工作流程也很棒。下面我会重点介绍Estimators API。无论选择哪一个都取决于你!
我们需要记住的是,只要用tf.keras.estimator.model_to_estimator方法将tf.keras.Model转换为tf.estimator.Estimator对象,tf.keras.Model就可以使用tf.estimator API训练。转换后,我们可以应用Estimators提供的机制在不同的硬件配置训练(代码链接在文末)。
import os
import time
#!pip install -q -U tensorflow-gpu
import tensorflow as tf
import numpy as np
导入Fashion-MNIST数据集
我们将使用Fashion-MNIST数据集,这是MNIST的替代品,其中包含数千张Zalando时尚文章的灰度图像。获取训练和测试数据非常简单:
(train_images,train_labels),(test_images,test_labels)=
tf.keras.datasets.fashion_mnist.load_data()
我们想要将这些图像的像素值从0到255之间的数字转换为0到1之间的数字,并将数据集转换为[B,H,W,C]格式(B是图像数量,H和W是高度和宽度,C是我们数据集的通道数量,灰度图的情况下为1):
TRAINING_SIZE = len(train_images)
TEST_SIZE = len(test_images)
train_images = np.asarray(train_images, dtype=np.float32) / 255
# Convert the train images and add channels
train_images = train_images.reshape((TRAINING_SIZE, 28, 28, 1))
test_images = np.asarray(test_images, dtype=np.float32) / 255
# Convert the test images and add channels
test_images = test_images.reshape((TEST_SIZE, 28, 28, 1))
然后,我们希望将标签从整数id(如2或Pullover)转换为独热编码 (如0,0,1,0,0,0,0,0,0,0)。我们使用tf.keras.utils.to_categorical函数来做这点:
# How many categories we are predicting from (0-9)
LABEL_DIMENSIONS = 10
train_labels = tf.keras.utils.to_categorical(train_labels,
LABEL_DIMENSIONS)
test_labels = tf.keras.utils.to_categorical(test_labels,
LABEL_DIMENSIONS)
# Cast the labels to floats, needed later
train_labels = train_labels.astype(np.float32)
test_labels = test_labels.astype(np.float32)
建立一个tf.keras 模型
我们使用Keras Functional API创建我们的神经网络。Keras是一个用于构建和训练深度学习模型的高级API,好处在于用户友好、模块化且易于扩展。tf.keras是TensorFlow的Keras Functional API实现,它支持诸如Eager Execution(急切执行),tf.data管道和Estimators等等。
在架构方面,我们将使用ConvNets。在较高层上,ConvNets由卷积层(Conv2D)和池化层(MaxPooling2D)组成。但最重要的,他们视每个训练实例为三维张量(height,width,channels),灰度图像的情况下开头为channels=1,并返回一个三维张量。
因此,在ConvNet部分之后,我们将需要Flatten张量并添加稠密层,其中最后一个返回带有tf.nn.softmax激活的大小为LABEL_DIMENSIONS的向量:
inputs = tf.keras.Input(shape=(28,28,1)) # Returns a placeholder
x = tf.keras.layers.Conv2D(filters=32,
kernel_size=(3, 3),
activation=tf.nn.relu)(inputs)
x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=2)(x)
x = tf.keras.layers.Conv2D(filters=64,
kernel_size=(3, 3),
activation=tf.nn.relu)(x)
x = tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=2)(x)
x = tf.keras.layers.Conv2D(filters=64,
kernel_size=(3, 3),
activation=tf.nn.relu)(x)
x = tf.keras.layers.Flatten()(x)
x = tf.keras.layers.Dense(64, activation=tf.nn.relu)(x)
predictions = tf.keras.layers.Dense(LABEL_DIMENSIONS,
activation=tf.nn.softmax)(x)
我们现在可以定义我们的模型,选择优化器(我们从TensorFlow中选择一个,不使用tf.keras.optimizers)并编译它:
model = tf.keras.Model(inputs = inputs,outputs = predictions)
optimizer = tf.train.AdamOptimizer(learning_rate = 0.001)
model.compile(loss ='categorical_crossentropy',
optimizer = optimizer,
metrics = ['accuracy'])
创建Estimator
要从编译的Keras模型创建Estimator,我们需要调用model_to_estimator方法。请注意,Keras模型的初始模型状态将保留在创建好Estimator中。
那么Estimator有什么好处呢?那么开始:
- 无需更改模型即可在本地主机或分布式多GPU环境中运行基于Estimator的模型;
- Estimator简化了模型开发人员之间的共享实现;
- Estimator为你构建了图,有点像Eager Execution,没有显式会话。
那么我们如何使用多GPU开始训练我们的简单tf.keras模型呢?我们可以使用tf.contrib.distribute.MirroredStrategy范式,它用同步训练进行图内复制。
实际上,每个工作的GPU都有一个网络副本,获取数据的子集,在该数据上计算本地梯度,然后等待所有工作者(worker,这里指工作的机器)以同步方式完成。然后,工作者通过Ring All-reduce操作对本地梯度进行通信(这通常被优化以减少网络带宽并增加吞吐量)。一旦所有梯度到达,每个工作者将它们均分并更新其参数,然后开始下一步。这在有多个gpu且通过某些高速互连连接到单个节点的情况下非常理想。
要使用此策略,我们首先从编译的tf.keras模型中创建一个Estimator,然后通过RunConfig配置给它一个MirroredStrategy结构。默认情况下,此配置将使用所有GPU,但你也可以用num_gpus选项使用特定数量的GPU:
NUM_GPUS = 2
strategy = tf.contrib.distribute.MirroredStrategy(num_gpus=NUM_GPUS)
config = tf.estimator.RunConfig(train_distribute=strategy)
estimator = tf.keras.estimator.model_to_estimator(model,
config=config)
创建一个Estimator输入函数
要将数据传输到Estimator,我们需要定义一个数据导入函数,该函数返回批量数据(images,labels)的tf.data数据集。下面的函数接受numpy数组并通过ETL进程返回数据集。
请注意,最后我们还调用了这样的prefetch方法,它将在训练时将数据缓冲到GPU,以便下一批数据准备就绪并等待gpu,而不是让gpu在每次迭代时等待数据。GPU可能仍然没有得到充分利用,为了改善这一点,我们可以使用融合版本的转换操作(如,shuffle_and_repeat),而不是两个单独的操作,但是我在这里保留了简单的情况。
def input_fn(images, labels, epochs, batch_size):
# Convert the inputs to a Dataset. (E)
ds = tf.data.Dataset.from_tensor_slices((images, labels))
# Shuffle, repeat, and batch the examples. (T)
SHUFFLE_SIZE = 5000
ds = ds.shuffle(SHUFFLE_SIZE).repeat(epochs).batch(batch_size)
ds = ds.prefetch(2)
# Return the dataset. (L)
return ds
训练Estimator
让我们首先定义一个SessionRunHook类来记录随机梯度下降的每次迭代的次数:
class TimeHistory(tf.train.SessionRunHook):
def begin(self):
self.times = []
def before_run(self,run_context):
self.iter_time_start = time.time()
def after_run(self,run_context,run_values):
self.times.append(time.time() - self.iter_time_start)
现在好了!我们可以调用我们Estimator上的train函数,通过它的hooks参数给赋予它我们定义的input_fn(带批量大小和我们希望训练的次数)和一个TimeHistory实例:
time_hist = TimeHistory()
BATCH_SIZE = 512
EPOCHS = 5
estimator.train(lambda:input_fn(train_images,train_labels,
epochs
= EPOCHS,
batch_size = BATCH_SIZE),
hooks = [time_hist])
性能
由于我们的计时了hook,我们现在可以用它来计算训练的总时间以及我们每秒训练的平均图像数(平均吞吐量):
total_time = sum(time_hist.times)
print(f"total time with {NUM_GPUS} GPU(s): {total_time} seconds")
avg_time_per_batch = np.mean(time_hist.times)
print(f"{BATCH_SIZE*NUM_GPUS/avg_time_per_batch} images/second with
{NUM_GPUS} GPU(s)")
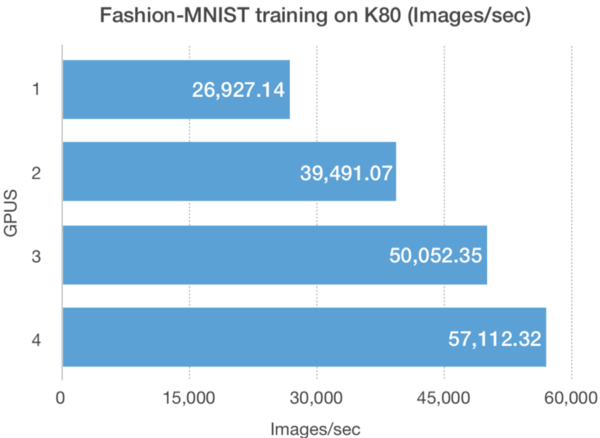
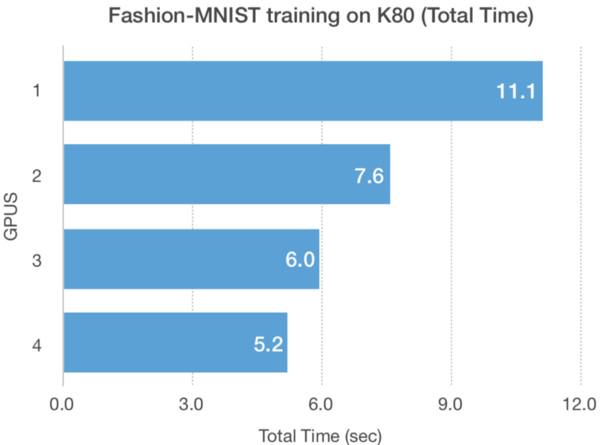
两个不同的NUM_GPUS的K80 GPU上Fashion-MNIST训练的吞吐量和总时间表现较少扩展。
评估Estimators
为了检查我们模型的性能,我们在Estimator上调用evaluate方法:
estimator.evaluate(lambda:input_fn(test_images,
test_labels ,epochs
= 1,
batch_size = BATCH_SIZE))
视网膜OCT(光学相干断层扫描)图像示例
为了测试更大数据集的缩放性能,我们使用视网膜OCT图像数据集,这是Kaggle的数据集之一。数据集由活人视网膜的横截面X射线图像组成,分为四类:NORMAL,CNV,DME和DRUSEN:
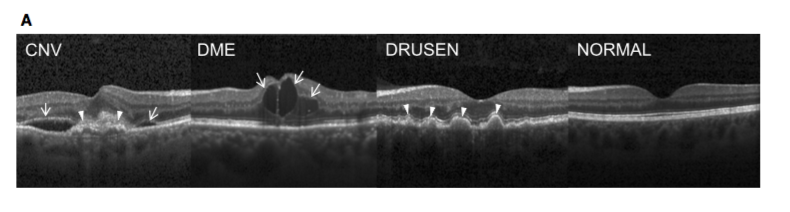
数据集通常共有84,495个X射线JPEG图像,512x496可以通过kaggle CLI下载(https://github.com/Kaggle/kaggle-api):
#!pip install kaggle
#!kaggle datasets download -d paultimothymooney/kermany2018
下载后,训练和测试集图像类位于各自的文件夹中,因此我们可以将模式定义为:
labels = ['CNV','DME','DRUSEN','NORMAL']
train_folder = os.path.join('OCT2017','train','**','*。jpeg')
test_folder = os.path.join('OCT2017','test','**','* .JPEG“)
接下来我们编写Estimator的输入函数,它接受任何文件模式并返回调整好大小的图像和独热编码标签作为tf.data.Dataset。这次我们遵循Input Pipeline Performance Guide。请特别注意,如果prefetch的buffer_size为None,那么TensorFlow将自动使用最优的预取缓冲大小:
def input_fn(file_pattern, labels,
image_size=(224,224),
shuffle=False,
batch_size=64,
num_epochs=None,
buffer_size=4096,
prefetch_buffer_size=None):
table = tf.contrib.lookup.index_table_from_tensor(mapping=tf.constant(labels))
num_classes = len(labels)
def _map_func(filename):
label = tf.string_split([filename], delimiter=os.sep).values[-2]
image = tf.image.decode_jpeg(tf.read_file(filename), channels=3)
image = tf.image.convert_image_dtype(image, dtype=tf.float32)
image = tf.image.resize_images(image, size=image_size)
return (image, tf.one_hot(table.lookup(label), num_classes))
dataset = tf.data.Dataset.list_files(file_pattern, shuffle=shuffle)
if num_epochs is not None and shuffle:
dataset = dataset.apply(
tf.contrib.data.shuffle_and_repeat(buffer_size, num_epochs))
elif shuffle:
dataset = dataset.shuffle(buffer_size)
elif num_epochs is not None:
dataset = dataset.repeat(num_epochs)
dataset = dataset.apply(
tf.contrib.data.map_and_batch(map_func=_map_func,
batch_size=batch_size,
num_parallel_calls=os.cpu_count()))
dataset = dataset.prefetch(buffer_size=prefetch_buffer_size)
return dataset
这次训练这个模型,我们将使用预训练的VGG16,并对它的最后5层进行再训练:
keras_vgg16 = tf.keras.applications.VGG16(input_shape=(224,224,3),
include_top=False)
output = keras_vgg16.output
output = tf.keras.layers.Flatten()(output)
prediction = tf.keras.layers.Dense(len(labels),
activation=tf.nn.softmax)(output)
model = tf.keras.Model(inputs=keras_vgg16.input,
outputs=prediction)
for layer in keras_vgg16.layers[:-4]:
layer.trainable = False
现在我们拥有了我们所需要的一切,可以按照上面的步骤进行操作,并使用NUM_GPUS GPU在几分钟内训练我们的模型
model.compile(loss ='categorical_crossentropy',
optimizer = tf.train.AdamOptimizer(),
metrics = ['accuracy'])
NUM_GPUS = 2
strategy = tf.contrib.distribute.MirroredStrategy(num_gpus = NUM_GPUS)
config = tf.estimator.RunConfig(train_distribute = strategy)
estimator = tf.keras.estimator.model_to_estimator(model,
config = config)
BATCH_SIZE = 64
EPOCHS = 1
estimator.train(input_fn = lambda:input_fn(train_folder,
labels,
shuffle = True,
batch_size = BATCH_SIZE,
buffer_size = 2048,
num_epochs = EPOCHS,
prefetch_buffer_size = 4),
hooks = [time_hist])
训练完成后,我们可以评估测试集的准确性,应该在95%左右(对于初始基线来说还不错):
estimator.evaluate(input_fn = lambda:input_fn(test_folder,
labels,
shuffle = False,
batch_size = BATCH_SIZE,
buffer_size = 1024,
num_epochs = 1))
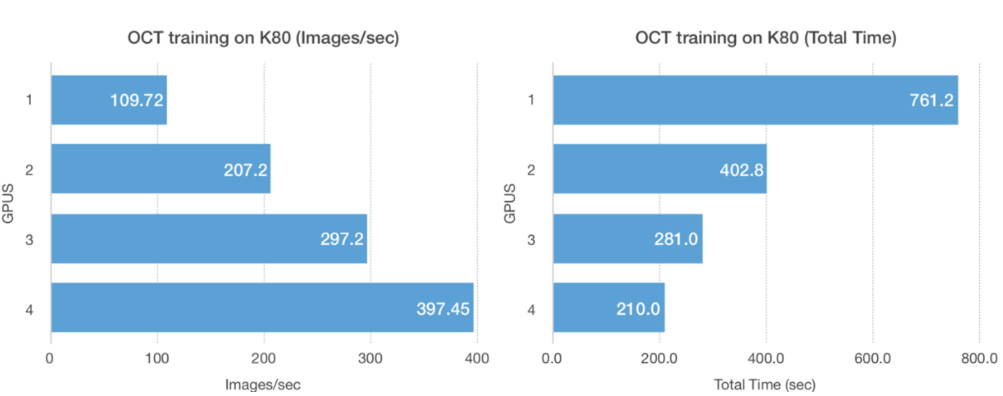
两个不同的NUM_GPUS的K80 GPU上FRetinal OCT训练的吞吐量和总时间表现线性扩展
总结
我们在上面展示了使用Estimators API在多个GPU上训练深度学习Keras模型,如何编写一个遵循最佳实践的输入管道来充分利用我们的资源(线性扩展)以及如何通过hook计时训练吞吐量。
请注意,最后我们关心的主要问题是测试集误差。你可能会注意到,随着num_gpu的增加,测试集的准确性会降低。可能的原因是,当我们使用更多GPU时,批量大小的BATCH_SIZE*NUM_GPUS有效训练MirroredStrategy可能需要调整BATCH_SIZE或学习率。在这里,为了绘图,我保持NUM_GPUS所有其他超参数不变,但实际上需要对它们进行调优。
数据集的大小以及模型大小也会影响这些方案的扩展程度。GPU在读取或写入小数据时带宽较差,对于像K80这样的旧GPU尤其如此。
GitHub:https://github.com/kashif/tf-keras-tutorial/blob/master/7-estimators-multi-gpus.ipynb

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消