












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌发布What-If工具:分析ML模型无需代码
2018年09月12日 由 浅浅 发表
501878
0

构建有效的ML系统意味着提出了很多问题。仅训练模型是不够的。相反,优秀的从业者像侦探一样,探索并更好地理解他们的模型:数据点的变化将如何影响我的模型的预测?它对不同的群体有不同的表现,例如,历史上被边缘化的人群?我正在测试我的模型的数据集多样化如何?
回答这些问题并不容易。探索“假设”场景通常意味着编写自定义的一次性代码来分析特定模型。这个过程不仅效率低下,而且非程序员很难参与塑造和改进ML模型的过程。一个焦点Google AI PAIR计划使广泛的人员可以更轻松地检查,评估和调试ML系统。
今天,谷歌推出What-If工具,这是开源TensorBoard Web应用程序的一项新功能,它允许用户在不编写代码的情况下分析ML模型。给定了一个TensorFlow模型和一个数据集的指针,这个假设工具提供了一个交互式的可视化界面来探索模型结果。
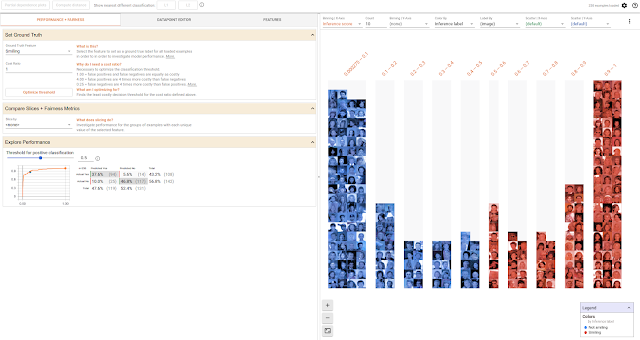
工具展示了一组250张人脸照片,以及从一个检测微笑的模型中得出的结果。
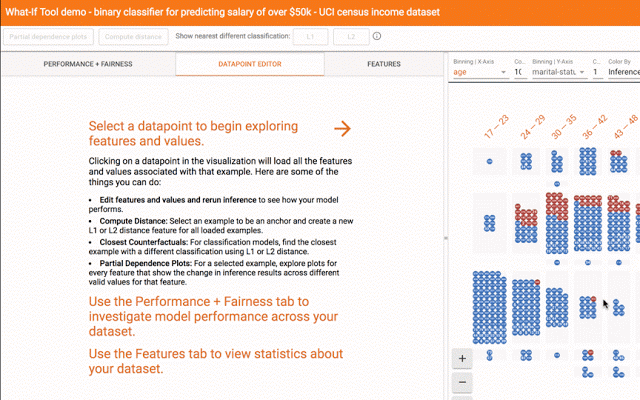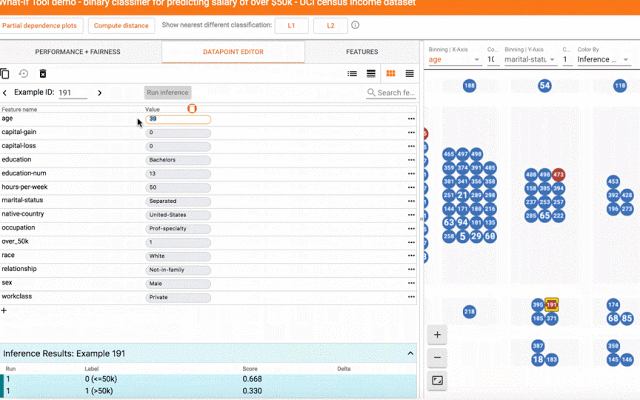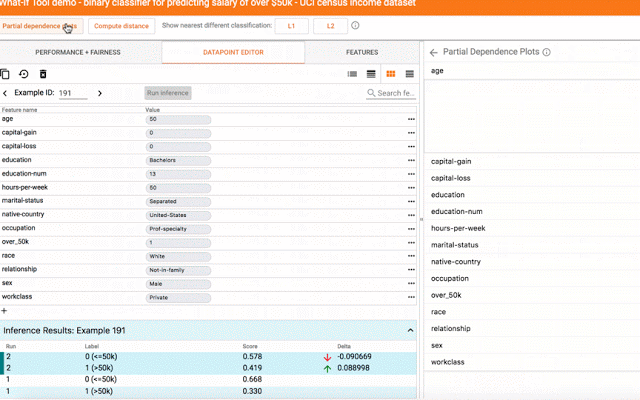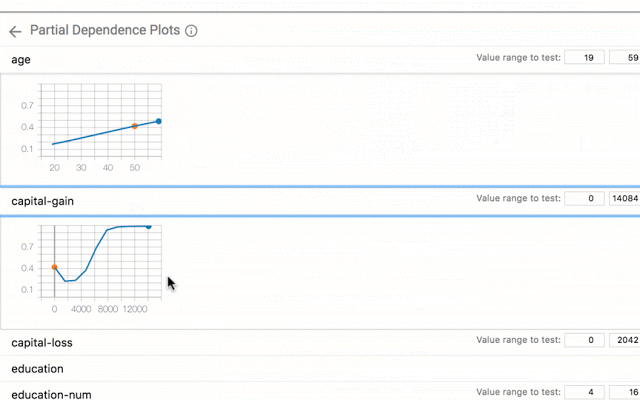
What-If工具具有大量功能,包括使用Facets自动显示数据集,从数据集手动编辑示例并查看这些更改的效果,以及自动生成部分依赖图,以显示模型的预测随着任何单个功能的更改而更改。
在一个数据点上探索假设场景。
反设事实
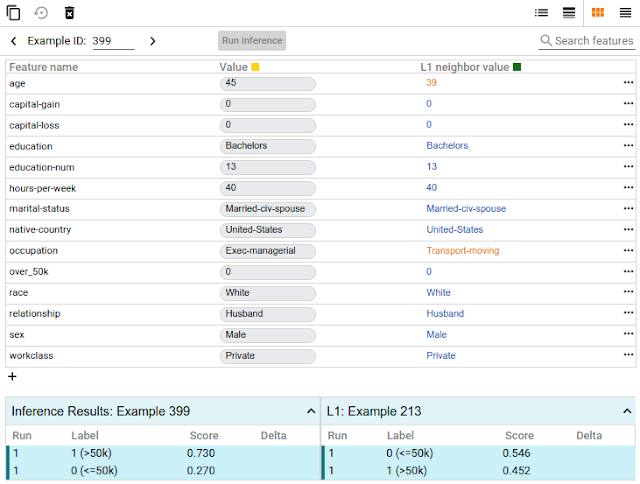
只需单击一个按钮,就可以将数据点与模型预测不同结果的最相似点进行比较。我们称这些点为“反事实”,它们可以揭示模型的决策边界。或者,你可以手动编辑数据点,并探索模型预测的变化。在下面的屏幕截图中,该工具用于二进制分类模型,该模型根据UCI人口普查数据集中的公共人口普查数据预测一个人是否收入超过5万美元。这是ML研究人员使用的基准预测任务,特别是在分析算法公平性时。在这种情况下,对于选定的数据点,模型预测该人获得超过5万美元的可信度为73%。该工具自动定位数据集中最相似的人,模型预测收益低于5千美元,并将两者并排比较。在这种情况下,只有年龄和职业变化的微小差异,模型的预测已经翻了。
性能和算法公平性分析
你还可以探索不同分类阈值的影响,同时考虑不同数值公平性标准等约束条件。下面的屏幕截图显示了微笑探测器模型的结果,该模型用开源CelebA数据集训练,该数据集由名人的注释面部图像组成。下面,数据集中的面被划分为是否有棕色头发,并且对于这两个组中的每一个都有一个ROC曲线和混淆矩阵预测,以及滑块,用于设定模型在确定面部微笑之前必须有多自信。在这种情况下,工具自动设置两组的置信度阈值,以优化机会均等。
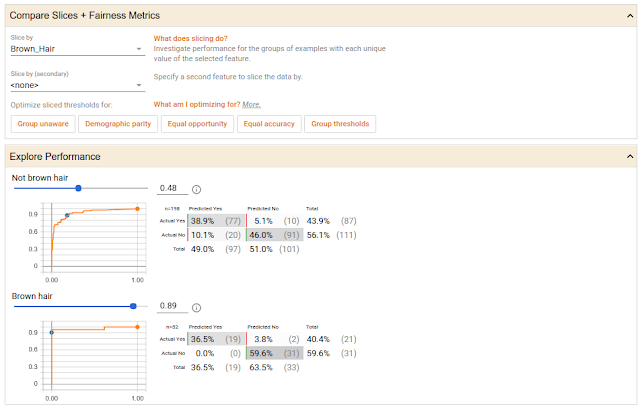
比较两组数据在微笑检测模型上的性能,并将其分类阈值设置为满足相等的机会约束。
演示
为了说明假设工具的功能,谷歌使用预先训练的模型发布了一组演示:
- 检测错误分类:一个多类分类模型,可以从花的四个测量值预测植物株型。该工具有助于显示模型的决策边界以及导致错误分类的原因。团队使用UCI虹膜数据集训练该模型。
- 评估二元分类模型的公平性:上面提到的用于微笑检测的图像分类模型。该工具有助于评估不同子组的算法公平性。该模型是有目的地训练而没有提供来自特定人群的任何示例,以显示该工具如何帮助揭示模型中的这种偏差。评估公平性需要仔细考虑整体背景,但这是一个有用的量化起点。
- 调查不同亚组的模型表现:回归模型,根据人口普查信息预测受试者的年龄。该工具有助于显示模型在子组中的相对性能以及不同特征如何单独影响预测。该模型使用UCI人口普查数据集进行训练。
实践中的假设
谷歌内部的团队中测试了What-If工具,并看到了这种工具的直接价值。一个团队很快发现他们的模型错误地忽略了他们数据集的整个特征,导致他们修复了以前未被发现的代码错误。另一个团队使用它在视觉上组织他们的示例,从最佳到最差的性能,导致他们发现他们的模型表现不佳的示例类型的模式。
谷歌期待人们使用此工具更好地了解ML模型并开始评估公平性。代码是开源的。
工具:pair-code.github.io/what-if-tool/

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消