使用CNN和Deep Learning Studio进行自然语言处理
当我们听说卷积神经网络(CNN)时,我们通常会想到计算机视觉。从Facebook的自动标记照片到自驾车,CNN使图像分类领域发生重大突破,它是当今大多数计算机视觉系统的核心。
最近我们也开始将CNN应用于自然语言处理中的问题,并得到了一些有趣的结果。
在这篇文章中,我将实现一个类似于Kim Yoon的句子分类CNN。本文提出的模型在一些文本分类任务(如情感分析)中实现了良好的分类性能,并从此成为新的文本分类体系结构的标准基准。
论文:http://arxiv.org/abs/1408.5882
NLP简介
语言将人类联系在一起,它是一种让我们将我们的思想和感受传达给另一个人的工具,并且借助这个工具,我们也能够理解他们的思想和感受。我们大多数人从大约18个月到2岁之间学会讲话。人类的大脑是如何在如此幼小的年纪就掌握如此大量知识的,我们至今也无法完全理解。但是,已经发现大多数语言处理功能发生在大脑的大脑皮层内。
什么是句子分类
情感分析是自然语言处理(NLP)方法的常见应用,特别是分类方法,其目的是提取文本中的情感内容。情感分析可以被看作是为情绪得分量化定性数据的一种方法。尽管情感或者说情绪主要是主观的,但情感量化已经有了许多有用的实现,例如企业获得对消费者对产品的反应的理解,或者在网上评论中发现仇恨言论。
最简单的情感分析形式是使用好词和坏词的词典。句子中的每个单词都有一个分数,正面情绪通常为+1,负面情绪为-1。然后,我们简单地将句子中所有单词的分数相加,得到最终的情感总分。显然,这有很多限制,最重要的是它忽略了上下文和词汇环境。例如,在我们的简单模型中,短语“not good”可以被归类为0,因为“not”具有-1的分数,“good”的分数为+1。而一个人可能会将“not good”归类为负面,尽管里面有“good”存在。
另一种常用方法是将文本视为“词袋”。我们将每个文本视为1xN矢量,其中N是我们词汇表的大小。每列都是一个单词,值是该单词出现的次数。例如,短语“bag of bag of words”可能被编码为[2,2,1]。然后可以将它馈送到用于分类的机器学习算法中,例如逻辑回归或SVM,以预测数据隐藏的情绪。请注意,这需要具有已知情感的数据以监督的方式进行训练。虽然这是对先前方法的改进,但仍会忽略上下文,并且数据的大小随着词汇的大小而增加。
数据集
IMDB电影评论情绪问题描述
数据集是大型电影评论数据集(Large Movie Review Dataset),通常称为IMDB数据集。
IMDB数据集包含25,000个极端评论(好的或坏的)用于训练和测试。问题是要确定一个给定的评论是否具有积极或消极的情绪。
这些数据由斯坦福大学的研究人员收集并用于2011年的论文的(http://ai.stanford.edu/~amaas/papers/wvSent_acl2011.pdf),其中50/50的数据用于训练和测试。达到了88.89%的准确度。
2014年末至2015年初,一项名为“ Bag of Words Meets Bags of Popcorn ”的Kaggle竞赛也以这些数据为基础。准确率达到97%以上,获奖者达到99%。
那么,CNN如何应用于NLP?
大多数NLP任务的输入不是图像像素,而是以矩阵表示的句子或文档。矩阵的每一行对应一个标记,通常是一个单词,或者一个字符。也就是说,每行是表示单词的向量。通常,这些向量是词嵌入(低维表示),如word2vec或GloVe,但它们也可以是将单词索引为词汇表的独热向量。对于使用100维嵌入的10个单词的句子,我们将有一个10×100的矩阵作为我们的输入。这是我们的“图像”。
在视觉识别中,我们的过滤器会滑过图像的局部色块,但在NLP中,我们通常使用在矩阵的整行上滑动的过滤器(单词)。因此,我们的滤波器的“宽度”通常与输入矩阵的宽度相同。高度或区域大小可能会有所不同,但通常一次只能滑动2-5个单词的窗口。综合以上所述,用于NLP的卷积神经网络可能看起来像如下:
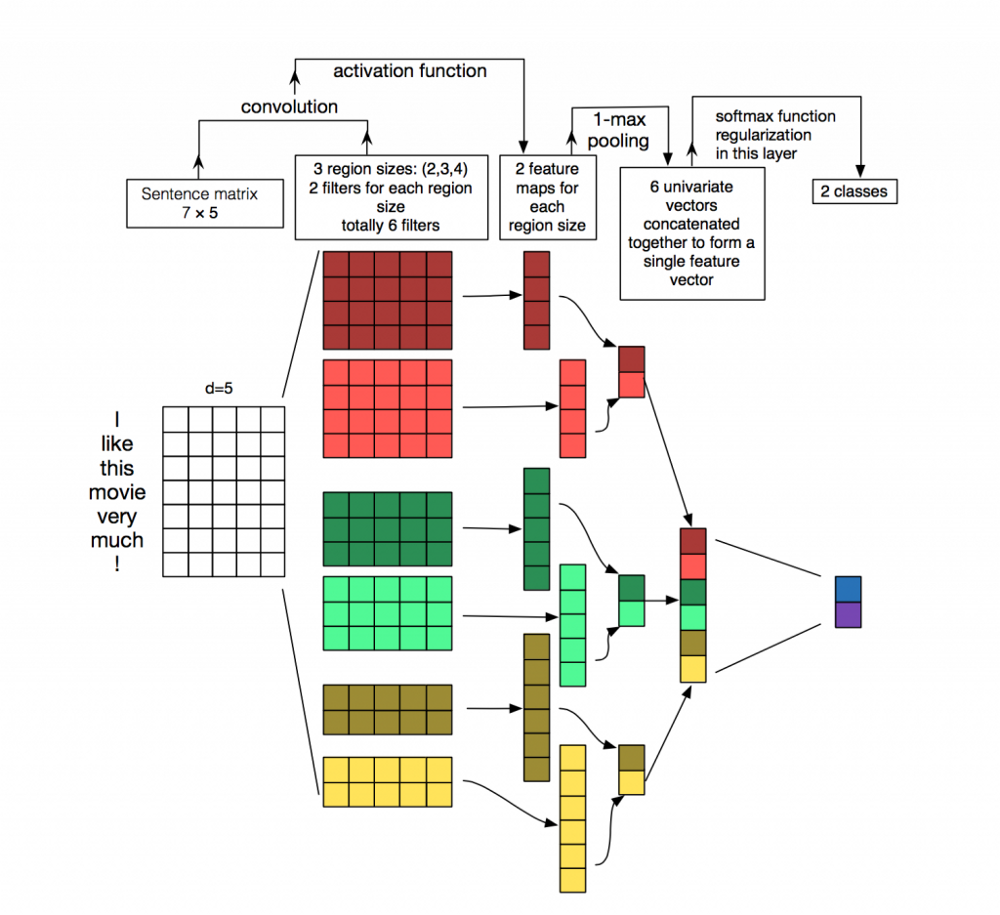
应用于NLP问题的CNN表现相当不错。简单的单词袋模型是一个明显带有错误假设的过度简化,但它仍然是多年来的标准方法,并带来了相当不错的结果。
使用CNN很重要的理由是它们很快,非常快。卷积是计算机图形的核心部分,它在GPU硬件层上实现。与n-grams相比,CNN 在表示方面也很有效。拥有大量词汇量,计算超过3-grams的任何东西都会很快变得昂贵。即使谷歌很难提供超过5-grams的东西。卷积滤波器自动学习好的表示,而不需要表示整个词汇表。使用尺寸大于5的过滤器是完全合理的。
模型
我们将在这篇文章中构建的网络大致如下:
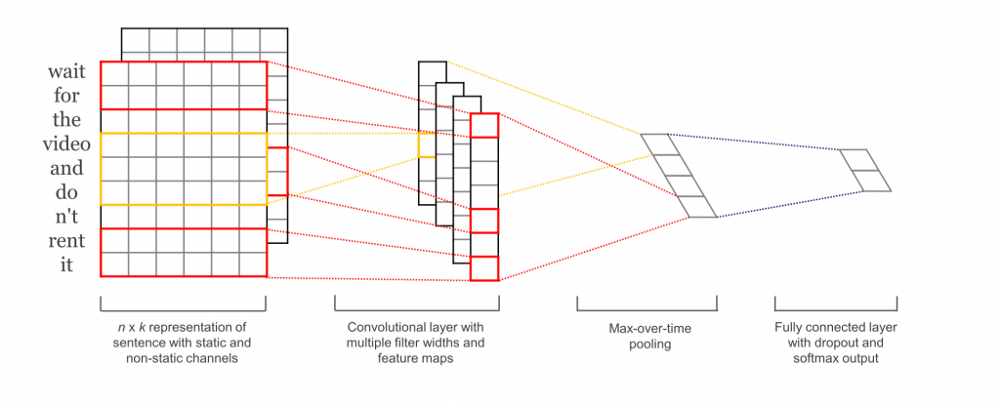
第一层将单词嵌入到低维矢量中。下一层使用多个滤波器大小对嵌入的词向量执行卷积。例如,一次滑动3个,4个或5个词。接下来,我们将卷积层的结果最大池化为长特征向量,添加dropout正则化,并使用softmax层对结果进行分类。
- 像素由句子中每个单词的嵌入矢量组成
- 卷积基于单词的层级进行
- 将每个句子分类为正(1)或负(0)
所以现在我们将看到实现部分。我将使用两种方法实现它:
1)使用1D卷积和池化的CNN
2)使用2D卷积和池化的CNN
我们将使用Deep Learning Studio实现此功能
如果你不熟悉如何使用Deep Learning Studio,可以查看:
https://www.atyun.com/19463.html
完整使用指南:https://towardsdatascience.com/deep-learning-made-easy-with-deep-learning-studio-complete-guide-a5c5ae58a771
比赛:https://medium.com/@rgrgrajat1/how-to-win-a-deep-learning-competition-without-coding-e1e7230efb46
1)项目创建:
登录到本地或在云中运行的Deep Learning Studio后,创建一个新项目。
2)上传数据集:
你无需上传Deep Learning Studio中提供的数据集。
3)数据集摄入量:
然后在Data选项卡中为这个项目设置数据集。通常,80% - 20%是训练和验证之间很好的分割,但如果你愿意,也可以使用其他设置。如果你的机器有足够的RAM可以将完整数据集加载进RAM,请将内存中的Load Dataset设置为Full Dataset。
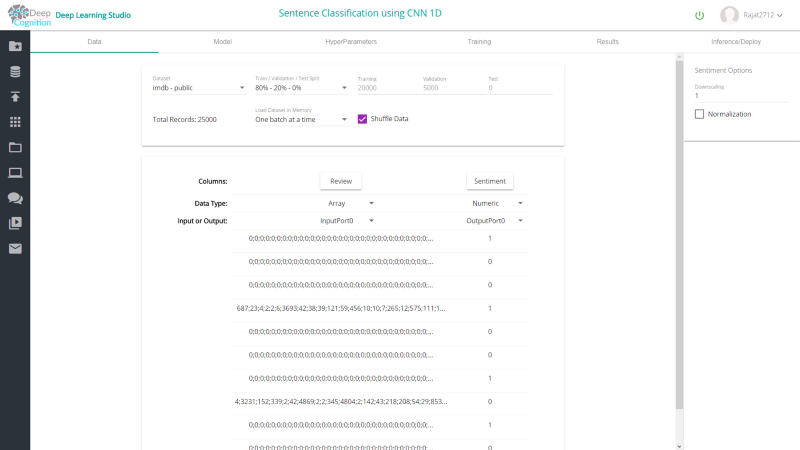
4)创建神经网络
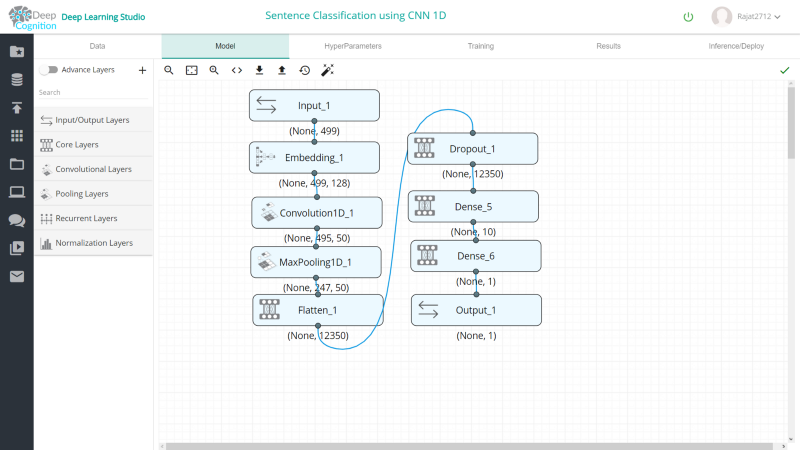
1)使用1维卷积层
你可以通过拖放层来创建如下所示的神经网络。
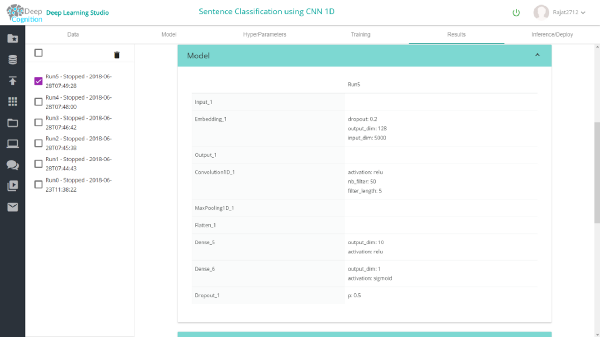
网络配置:
2)使用2维卷积层
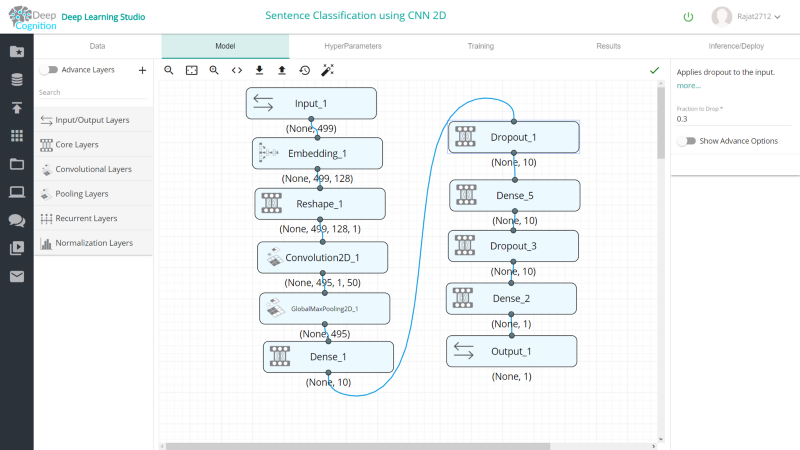
网络配置:
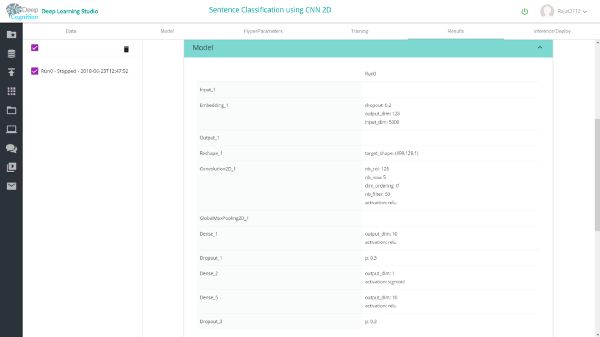
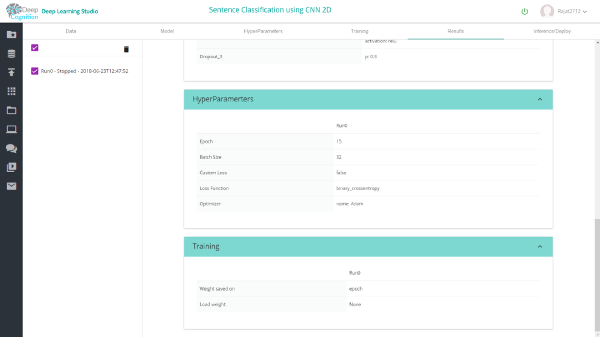
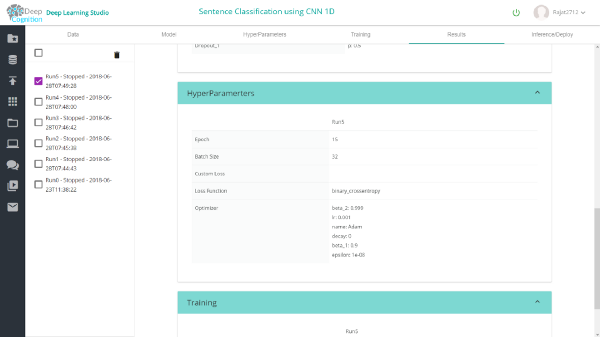
5)超参数和训练:
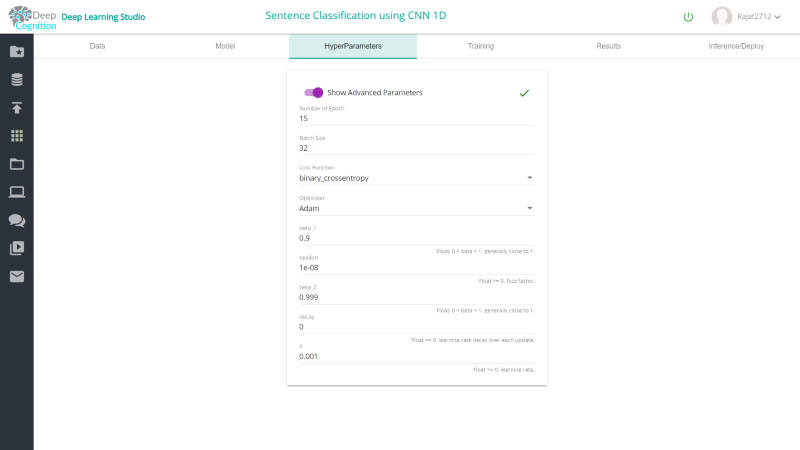
我已经使用的超参数如下所示。随意更改和尝试。
- 对于一维卷积层
2.对于2维卷积层
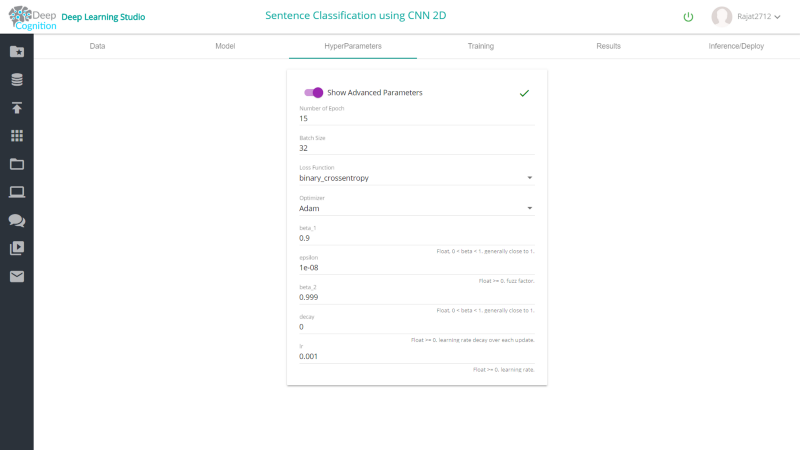
最后,您可以从Training选项卡开始训练,并使用训练仪表盘监控进度。
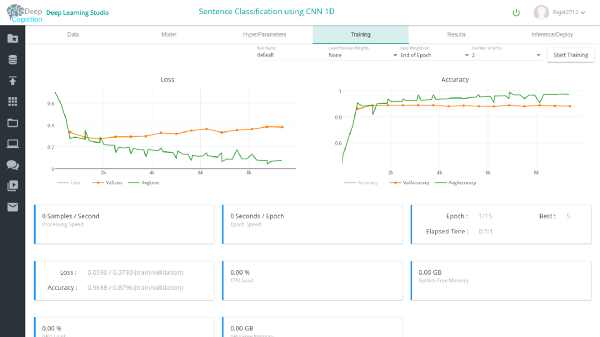
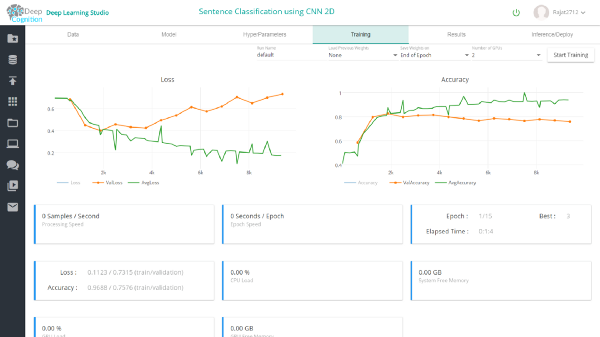
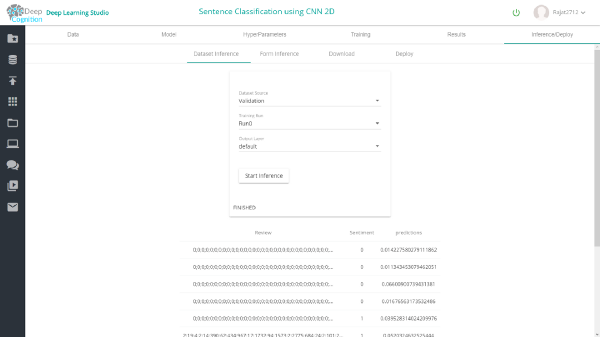
完成训练后,你可以在results选项卡中查看结果。在验证数据集中,1维和2维conv模型的准确率分别为约87%和75%。
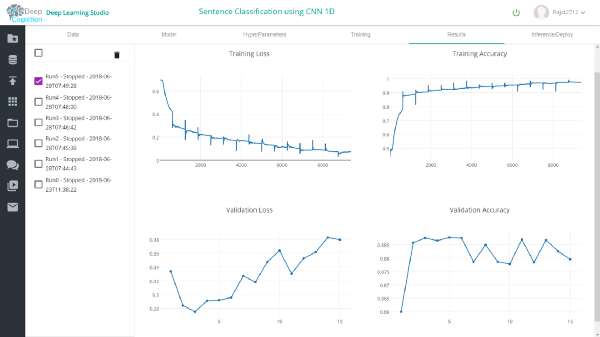
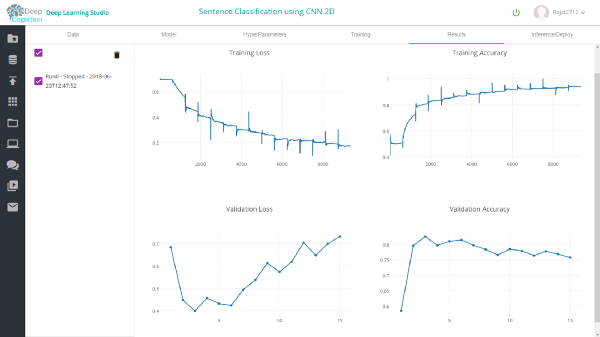
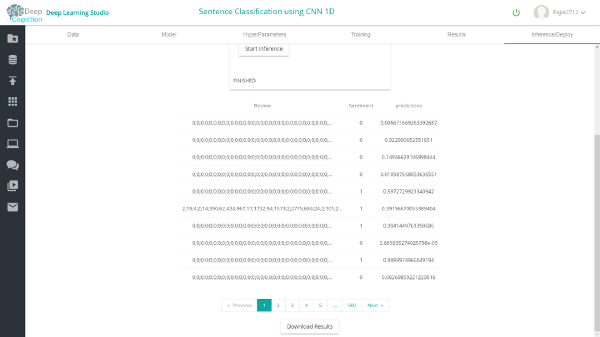
借助Deep Learning Studio,你可以轻松检查网络不同层上的验证和测试数据集的推理。
1维Conv
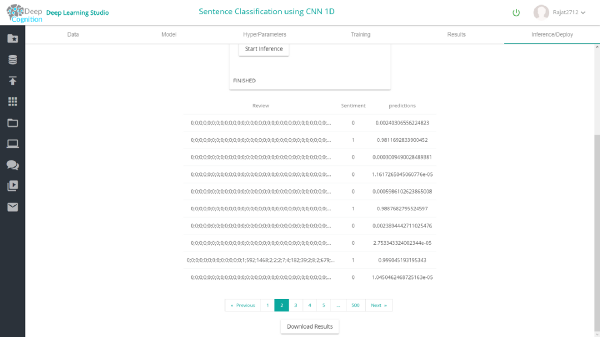
2维Conv