












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






苹果WWDC2017 开发者大会,机器学习已得到广泛应用
2017年06月06日 由 nanan 发表
8728
0

苹果WWDC2017开发者大会低调宣布将在6月12日推出Core ML,用在移动设备上的机器学习编程框架,也可应用在苹果的Siri,Camera和 QuickType等终端产品上,Core ML允许研发人员将训练好的机器学习模型加载到 iPhone或 iPad上,它是开发者能够使用代码编写具有智能功能的应用程序,其中包括了从文本基础到面部识别的一切。苹果还表示,应用在iPhone上的图像识别速度将会比Google Pixel快六倍。
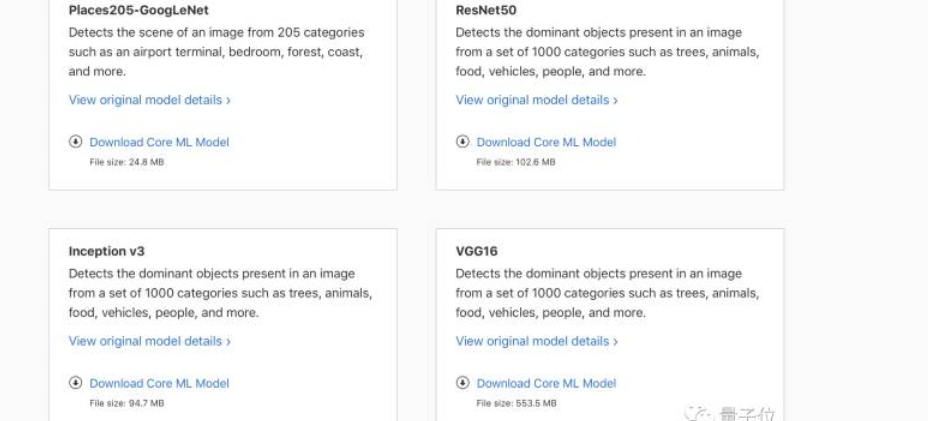
Core ML有一个很重要的特性是在本地处理机器学习数据,而不会将用户的隐私发送到云端。它对于本地的处理数据方面也会带来不少的好处,例如不需要连接网络的状态下,则不需要等待网络来传递信息;上传的数据不必离开设备,也更能得到更好的隐私权益。但同时对内存和功耗的要求也就更高了。Core ML建立在 Metal和 Accelerate底层技术之上,所以能最大限度的利用 CPU和 GPU来提供最高的性能和效率。
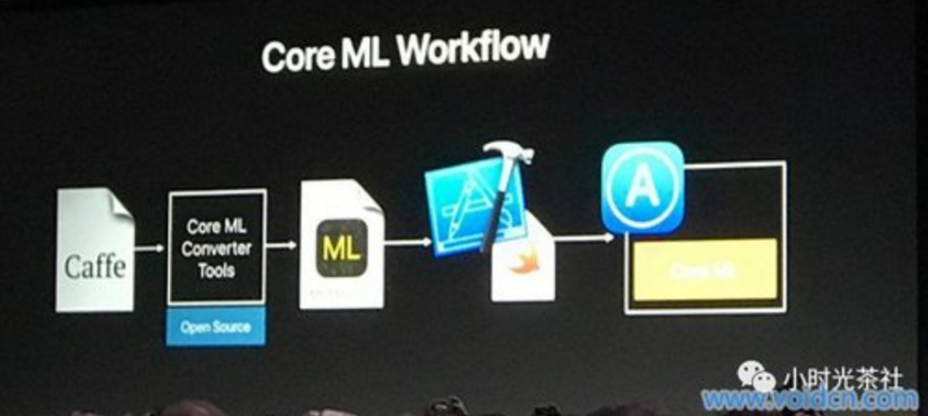
将机器学习带入移动设备的公司不只是苹果一家。Google在几周前的 I / O开发者大会上宣布推出了新的 TensorFlow Lite编程框架,为了让开发人员更方便的构建运行在低功耗的安卓设备模型中。如果使用该机器学习框架,开发人员必须将训练好的模型转换为兼容 Core ML的特殊格式。然后将模型加载到苹果的 Xcode开发环境中,并部署到 iOS设备上。苹果还发布了基于流行开源项目的四个预训练机器学习模型,而且还提供了一个转换器,以便研发人员自已进行使用。Caffe,Keras,scikit-learning,XGBoost和 LibSVM等框架都可用于该转换器。

在2017WWDC年度开发者大会上,苹果再三的提及AI术语及其机器的学习。苹果技术主管 Kevin Lynch、软件技术主管Craig Federighi和硬件工程师 John Ternus都强调了机器学习的重要性。
在这次大会中,苹果公司的高管多次提到机器学习,究竟是想要告诉我们什么呢?
苹果的人工智能产品:Siri
在2011年时,苹果就是第一批把人工智能应用到消费者群体中的公司,由创始人史蒂夫·乔布斯宣布的在iPhone上推出语音助手Siri。一直到现在,苹果才在人工智能领域再次推出新的产品。那么,这几年究竟是发生了什么事才导致苹果在时隔几年之后才推出新的人工智能产品呢?
早在2011年时,苹果就一直在研究Siri,但是直到2017年10月才聘请Ruslan Salakhutdinov(卡内基·梅隆大学教授深度学习知名人物)为人工智能研发的首席研究主管。
苹果一向是“以严格的保密制度”而闻名,它的安全制度可以延伸到博客、演讲的安排甚至是夫妻之间的对话等。人工智能研发到现在苹果都没有对外公布过它的具体情况,“保密制度”让苹果的人工智能研发变得十分的神秘,但神秘的同时还是带来了一定的麻烦,那就是很难招揽到相关方面的人才,如果想要在行业内取得关注和认可,其中的关键之一就是公开研究成果,与大家进行交流。在人工智能来临的形势下,有些巨头公司如Google、Facebook都有自己的机器学习的团队,并且可以发表一些文章且被行业内所熟知。同时还造成了苹果在人工智能申请专利的数量已被其他对手公司超越了。
在去年 NIPS大会上,苹果新聘请的人工智能研究主管Russ Salakhutdinov才宣布研究人员可以公开和分享人工智能方面的研究成果,并且在同年的12月,苹果发表了第一篇人工智能方面的研究论文:模拟 +无监督方法改善合成图像质量。众所周知,人工智能的发展是需要大量的数据进行收集和分析,但苹果却把更大的精力发挥在隐私保护这一层面上了,例如日历、浏览和餐厅预订、优化Siri等。从这一个方面来说,却让苹果在人工智能方面落后于其他的对手公司了。
在去年的苹果WWDC大会上,苹果还特地说明了它的差异隐私项目。苹果的软件主管Craig Federighi曾说:“需要明确的是,对于这些照片本身,其架构集以加密方式存储在云端,而元数据——包括用户创建的元数据以及我们深度学习后分类得出的元数据——同样经过加密,苹果无法进行读取”。差异隐私的基本思路是:如果有大量用户输入某个并不存在的单词,那么我们就不会认为它是拼写错误了,甚至可能会将其纳入拼写的补全推荐。在这样的一种情况下,我们希望用户可以理解该单词,但我们又不希望知道具体是有哪些用户输入过这个单词,我们是可以的回避与用户直接挂钩的信息。
但只要给提供的“小样”充足,这种不符合的问题将自行得到解决。为此如果我们希望学习新的单词的话,我们就会对其进行相关处理,并从处理中提取单一bit,例如将其称为 1。与此同时,手机设备会对其数据进行混淆,使其读取到的新数据称为1,或者在通过其算法之后的表达式为其他数字。苹果所获得的数据正是这种混淆之后的数据。因为有充足的数据量,苹果公司还是可以建立起宏观的视角,并同时了解到大部分人们真实的的思想。简单的说,就是可以了解到大部分人的倾向,但不会知道具体是哪个人的倾向。
如果是涉及到个人的信息时,苹果公司的对策是其只能在内部进行模拟训练。数据缺乏的问题也限制了个人的深度学习。根据 Jeff Dean的说法,整套神经网络是由成千上万的参数构成,而非单纯参考设备内运行的信息。对于这种个性化能力的缺失是否是致命的呢?至少对于谷歌而言是的。谷歌在去年的I/O大会上发不了机器学习的战略,其中的典型就是 Google Assistant个人 AI服务。可以看出,谷歌更倾向于深度学习,而苹果倾向于通过深度学习研发出更多的技术产品。每只技术团队都希望建立深度学习系统,直到目前为止,苹果公司的设想提供了不同的实现模式。
而今年的Siri,对比去年有了很大的提升。在今年的WWDC大会上,苹果公司发布了11款硬件升级,智能音箱 Homepod当属这次发布会的一大亮点。除了播放音乐基础功能之外,Homepod还可以播报交通信息、新闻、天气、股票、发送信息等,而且可以通过语音操控 Siri控制整个智能家居设备,真可谓是“多才多艺”。不仅如此,Siri还可以识别用户声音是否与ID相符,严格保护用户的隐私。新版的Siri利用语音合成,听起来更自然。同时还具体了翻译的功能,目前支持英语翻译中文、法语、德语、意大利语和西班牙语。苹果将Siri作为重大亮点来宣传,是想给用户带来更多的智能体验。那么,苹果所做的这一切,会使苹果成为领域内重点人工智能企业吗?


欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消