











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






如何用pycococreator将自己的数据集转换为COCO类型
2018年05月07日 由 浅浅 发表
21396
0

在如今深度学习的领域中,如果把数据比作老K,用以确保数据格式正确的就是Q,或者至少也得是J或者10,由此你可以看出它相当重要。在努力收集图像并注释所有的对象之后,你需要决定用什么格式来存储所有的信息。与其他你需要担心的事情相比,做这个决定似乎不算困难,但如果你想看到不同模型在数据上的表现差异多大,这一步是至关重要的。
早在2014年,微软就创建了一个名为COCO的数据集(Common Objects in COntext),用来推进物体识别和场景理解的研究。COCO是最早出现的不只用边界框来注释对象的大型数据集之一,因此它成了用于测试新的检测模型的普遍基准。用于储存注释、格式固定的COCO成为了业界标准,如果你能将数据集转换成COCO类型,那么最先进的模型都可为你所用。
接下来就该pycococreator接手了,它负责处理所有的注释格式化细节,并帮你将数据转换为COCO格式。让我们以用于检测正方形、三角形和圆形的数据集为例,来看看如何使用它。

形状图片和对象掩码示例
这些形状数据集包含500张128x128像素的jpeg图像,其中颜色和大小随机的圆形、正方形和三角形分布在颜色随机的背景上。其二进制掩码注释在每个png格式的形状中进行编码。这种二进制掩码很容易理解并创建。这就是为什么在你使用pycococreator创建COCO类型的版本之前,你需要转换数据集格式。你可能会想,为什么不使用png二进制掩码格式?它不是更好理解吗?请记住,我们制作COCO数据集,并不是因为它是表示注释图像的最佳方式,而是因为所有人都使用它。
下面我们用来创建COCO类型数据集的示例脚本,要求你的图像和注释符合以下结构:
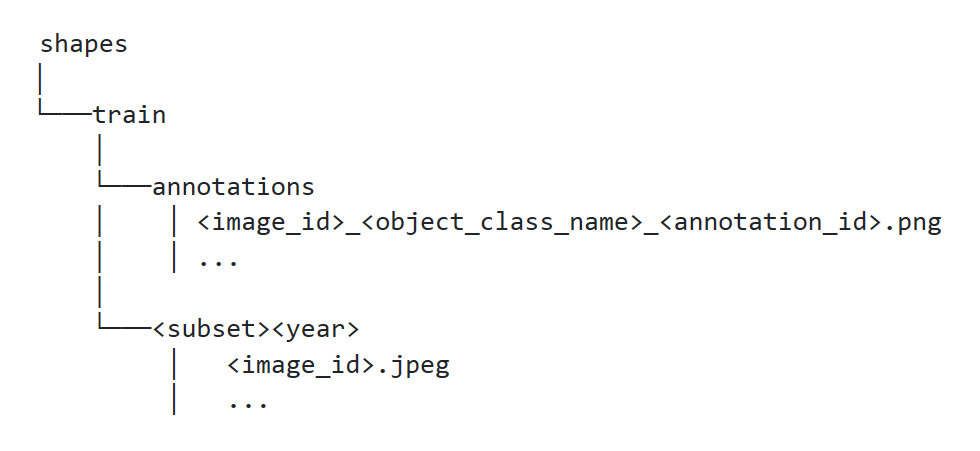
以形状为例,subset代表“shapes_train”,year为“2018”,object_class_name是“square”, “triangle”或“circle”。一般你还需要单独用于验证和测试的数据集。
COCO使用JSON (JavaScript Object Notation)对数据集的信息进行编码。COCO也有多种形式变化,取决于是否被用于对象实例、对象关键点或插图说明。我们要研究的对象实例格式如下:

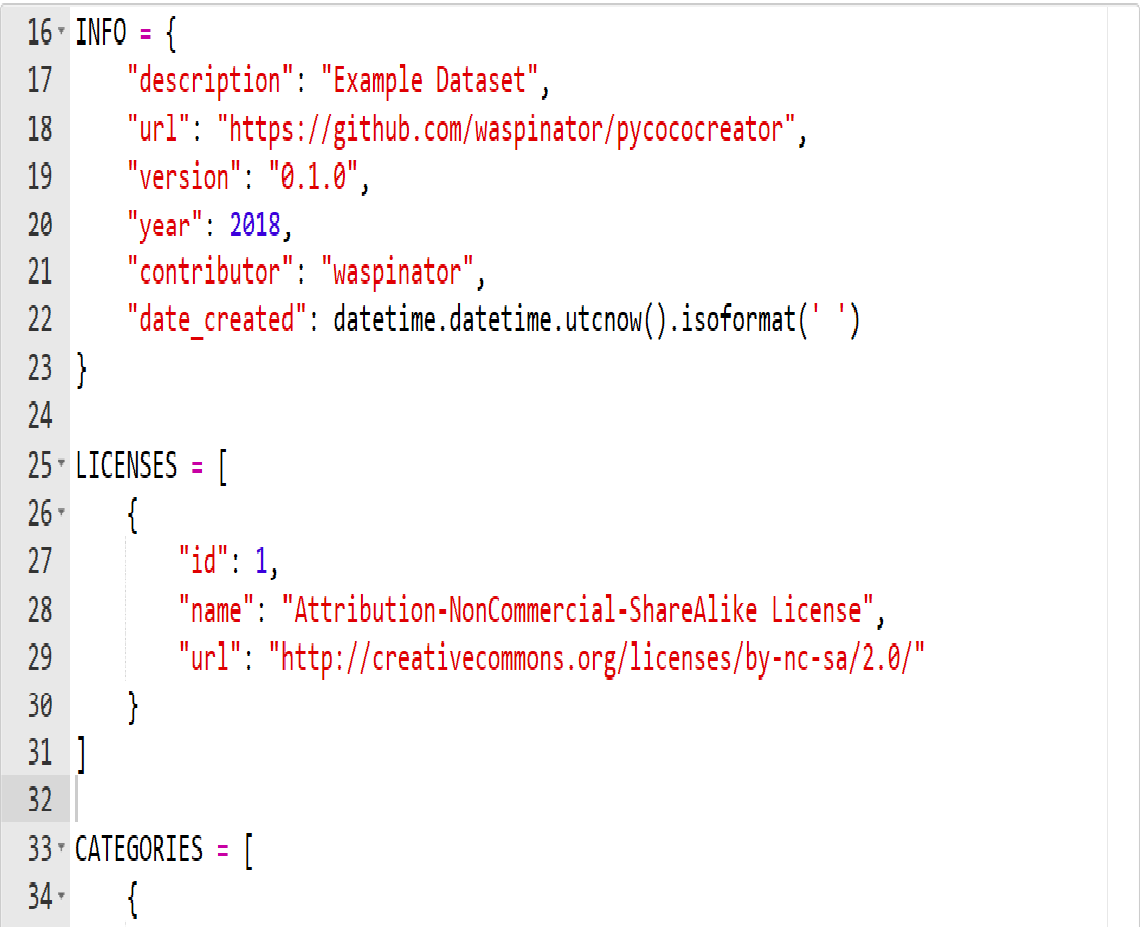
下面的“info”,“licenses”,“categories”和“images”列表都可以直接创建,不过创建“annotations”有点麻烦。但我们可以用pycococreator来解决这部分问题。让我们首先把简单的问题解决掉,我们使用python列表和字典库来描述我们的数据集,然后将它们导出为json格式。
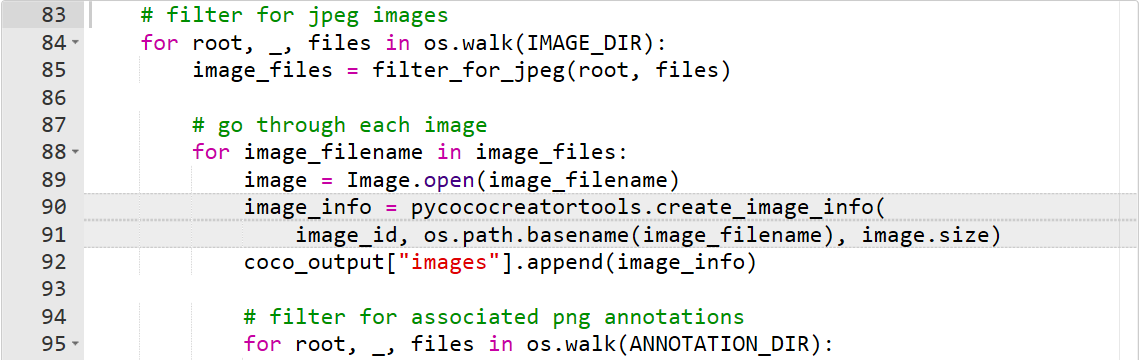
那么前三种完成后,我们可以继续处理图像和注释。我们要做的就是循环遍历每个jpeg图像及其对应的pngs注释,并让pycococreatorpy生成格式正确的条目。在第90和91行创建了图像条目,而在第112-114行进行了注释处理。
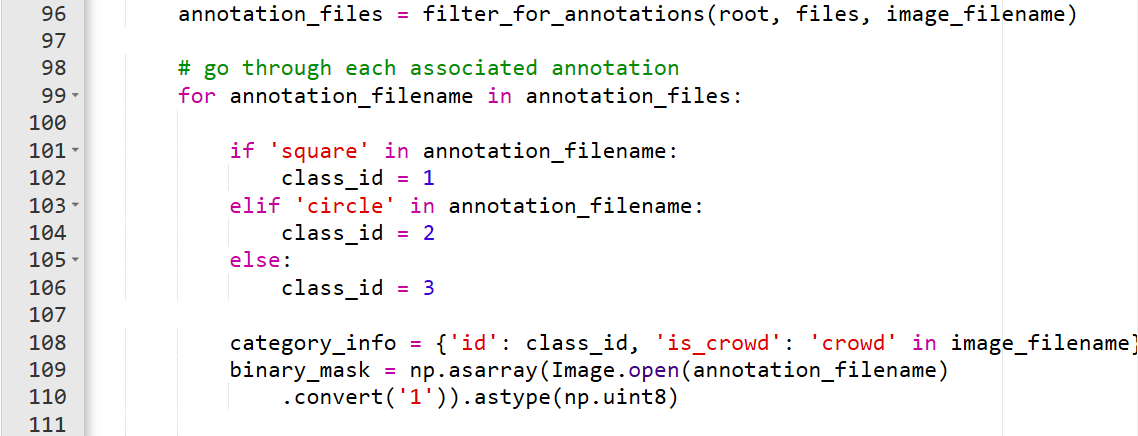

COCO支持的注释有两种类型,它们的格式取决于注释是单个对象还是多个对象。单个对象用沿着轮廓的点的列表进行编码,而多个对象则使用列优先的RLE(Run Length Encoding)进行编码。RLE用重复的数字代替数值的重复,是一种压缩算法。例如0 0 1 1 1 0 1转换成2 3 1 1。列优先意味着我们顺着列自上而下读取二进制掩码数组,而不是按照行从左到右读取。
pycococreatortools.create_annotation_info()函数中的tolerance改变了单个对象轮廓记录的精准度。数字越大,注释的质量越低,但文件相对也变小。通常从2开始比较合适。
在创建了COCO类型的数据集之后,你可以使用COCO API将其可视化来测试它。以pycococreator中的Jupyter Notebook为例,你应该会看到类似的情况:

使用COCO API的输出示例
你可以在github上找到用于转换形状数据集的完整脚本以及pycococreato。如果你想自行尝试形状数据集,可访问下方shape_strain_dataset的链接下载。
https://patrickwasp.com/wp-content/uploads/2018/04/shapes_train_dataset.zip
Github:https://github.com/waspinator/pycococreator/
现在,你可以尝试将自己的数据集转换为COCO格式,并用计算机视觉领域的最新进展进行试验。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com
下一篇
P值已死?统计假设检验的简介


OpenAI首款推理芯片亮相,年底开始部署







OpenAI GPT-Live:实时语音模型再升级

写评论取消
回复取消