











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






了解和辨别高斯分布,计算从中抽取的概要统计数据
2018年05月03日 由 浅浅 发表
43107
0

数据样本是从总体数据中抽取出来的快照(总体则包含了所有可能的观察结果),这些观察结果可应用到域或从程序中生成。
有趣的是,许多观察值都符合一种叫正态分布的常见分布(更正式的名称为高斯分布)。对于高斯分布来说很多东西都是已知的,因此,统计和统计方法的各个子领域也可与高斯数据一并使用。
在这篇教程中,你将了解高斯分布,如何分辨高斯分布,以及如何计算从分布中抽取的数据的关键性概要统计数据。
学完这篇教程,你会明白:
- 高斯分布描述了许多观察结果,包括在应用机器学习过程中得到的观察结果。
- 观察结果最有可能按集中趋势分布,这可以通过数据样本的平均数或中位数进行估计。
- 方差是分布中平均数的平均差,可以通过数据样本中的方差和标准差进行估计。
教程概述
本教程分为6个部分,分别是:
- 高斯分布
- 样本与总体
- 测试数据集
- 集中趋势
- 方差
- 描述高斯分布
高斯分布
数据的分布指的是你绘制图形时的形状,比如直方图。最常见的,众所周知的连续值分布是钟形曲线。它是正态分布,因为大量数据落入其间。它也被称为高斯分布,是以Carl Friedrich Gauss命名的。
同样,你将看到涉及的数据符合正态或高斯分布,这两种概念是相通的,都是指数据分布形态为高斯分布。
一些符合高斯分布的观察结果的例子如下:
- 身高
- IQ
- 体温
让我们来具体探索正态分布,下面是一些代码,可以生成和绘制理想化的高斯分布。
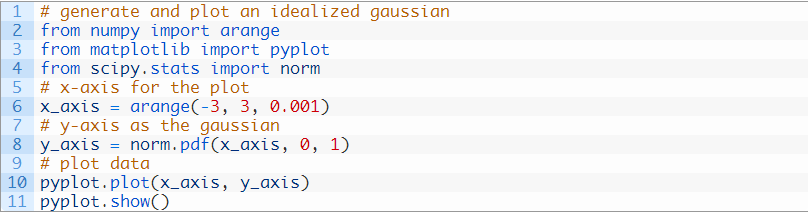
运行这个示例会生成一个理想化的高斯分布图。x轴是观察结果,y轴是每个观察结果出现的频率。
在这种情况下,观察结果出现在0.0附近是最常见的,观察结果在-3.0和3.0之外很少见,基本不太可能出现。
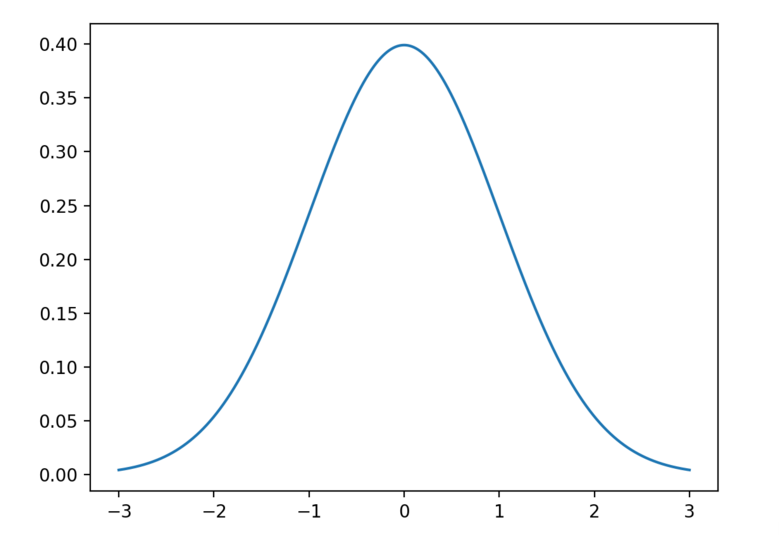
高斯分布线条图
当数据符合高斯分布,或当我们假定分布为高斯分布来计算统计数据时,这是非常实用的。因为高斯分布很容易理解。因此,统计学中很大一部分都会用到这一分布的方法。
所幸我们在机器学习中处理的数据通常都符合高斯分布,比如我们用来拟合模型、以及基于不同训练数据样本的重复评估模型的输入数据。并不是所有的数据都符合高斯分布,因此,通过查看数据的直方图或使用统计检验来进行检查是很重要的。
一些不符合高斯分布的观察结果的例子包括:
- 收入
- 城市人口
- 图书销量
样本与总体
经由一些未知的处理可能会得出数据。我们将收集的数据称为数据样本,所有可能收集到的数据称为总体。
数据样本:来自一个群体的观察结果的子集。
数据总体:来自一个群体的所有可能的观察结果。
这之间的区别很重要,因为样本和总体使用不同的统计方法,在应用机器学习中,我们经常处理很多数据样本。
如果谈到机器学习中的数据时,读到或使用“总体”(Population)这个词,在统计方法的领域中,它很可能是指样本。
在机器学习中,你会遇到的两种数据样本实例:
- 训练和测试数据集
- 模型性能分数
使用统计方法时,我们经常想要只用样本的观察数据来证明总体。
两个明显的例子是:
- 训练样本必须代表观察结果的总体,这样我们才能拟合有用的模型。
- 测试样本必须代表观察结果的总体,这样我们才能公正地评估模型技能。
因为我们研究的是样本,并且同时证明总体,这意味着总会有一些不确定性,理解和报告这种不确定性非常重要。
测试数据集
在我们研究符合高斯分布的重要的概要统计数据之前,先来生成一个有效的数据样本。我们可以使用NumPy的randn()函数,生成从高斯分布中抽取的随机数的样本。有两个关键参数定义了高斯分布,即平均数和标准差。我们稍后会详细讨论这些参数,它们也是在预测未知高斯分布中提取出的数据时,会用到的关键统计数据。
randn()函数会生成特定的数字,用到的随机数是从平均数为0标准差为1的高斯分布中抽取的。然后我们可以通过重新调整数字,将这些数字按比例输入到我们选择的高斯函数中。
可以通过添加期望的平均值(例如50),或乘以标准差(5)来保持一致性。
然后,我们可以使用直方图绘制数据集,并探索绘制数据的预期形状。下面是一个完整的例子。
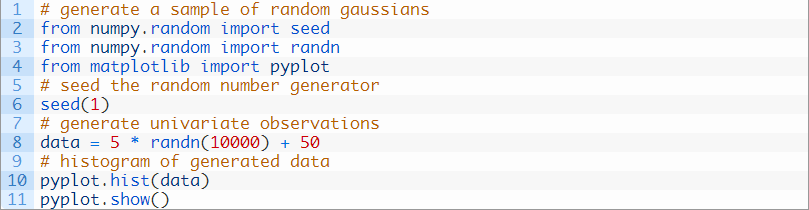
运行这个例子会生成数据集,并给出直方图。我们几乎可以看到数据呈高斯的形状分布,但它是块状的。这也突显了一些重要的点。
有时数据并不符合完美的高斯分布,但是仍属于类高斯分布。它近似高斯分布,但如果用不同的方法绘制,或是不同的方法测量,或收集更多数据,那样可能会更近似高斯分布。
通常,处理类高斯数据时,我们可以把它当做高斯数据,使用相同的统计工具得到可靠的结果。
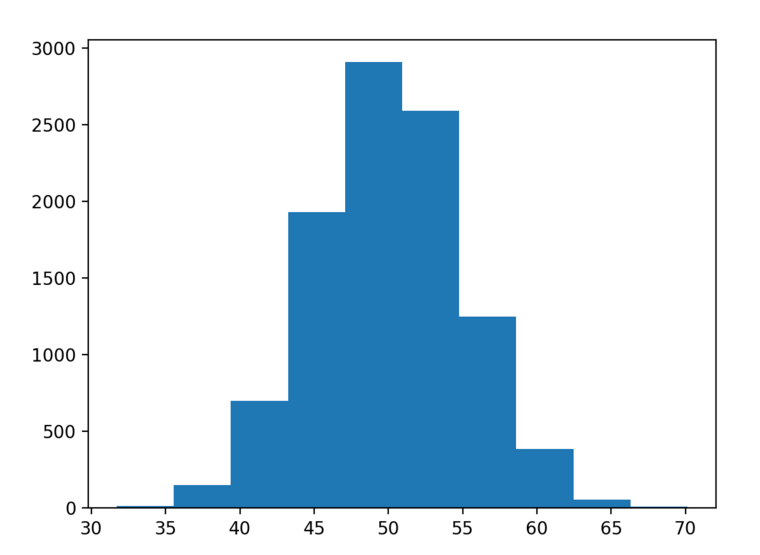
高斯分布直方图
在这个数据集的例子中,我们处理了足够的数据,绘制的图是块状的,因为用于绘制的函数将数据随机分割成任意大小的部分。我们可以选择不同的、更为细致的方法分割数据,以便更好地显示出潜在的高斯分布。
下面新的例子生成了更为精细的图。
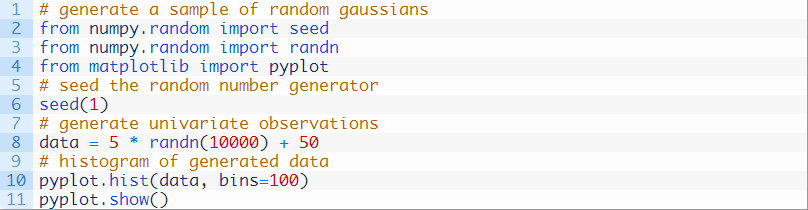
运行这个示例,我们可以看到,选择100个已分割的数据可以绘制出更好的图,清晰地显示出数据的高斯分布。数据集是从完美的高斯函数抽取的,但是这些数字是随机选择的,我们只为样本选择了10000个观察结果。你可以观察到,即使进行了有效的控制,数据样本中还是存在明显的噪声。
这突出了另一个重要的观点:在我们的预期中不应该忽视数据样本中存在噪声或限制。与真正的潜在分布相比,数据样本中总是包含误差。
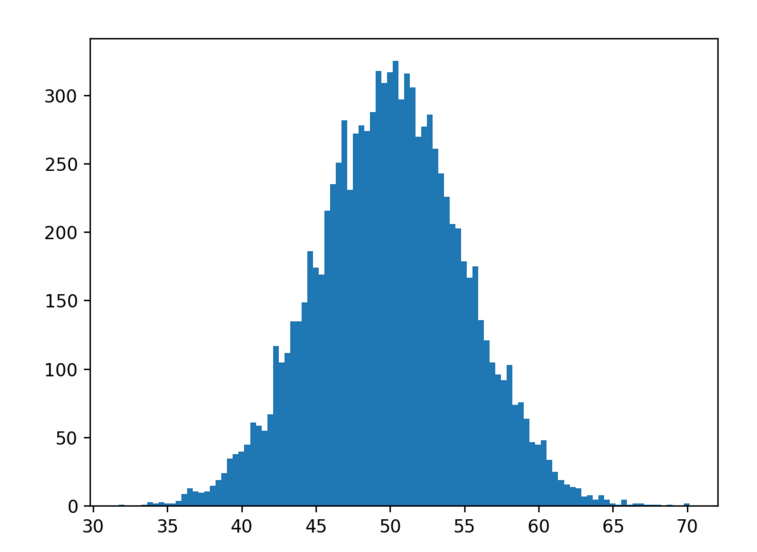
包含更多数据的高斯分布直方图
集中趋势
分布的集中趋势是指分布的中间值或典型值。这是最常见或最有可能出现的值。在高斯分布中,集中趋势被称为平均数,或更正式地说,是算术平均数,是定义高斯分布的两个主要参数之一。
样本的平均数的计算方法是,用观察结果的总和除以样本中观察结果的总数。
简写形式如下:
我们可以在数组中通过NumPy的mean()函数来计算样本平均数。
下面的例子使用上一节开发的测试数据集展示了这个方法。
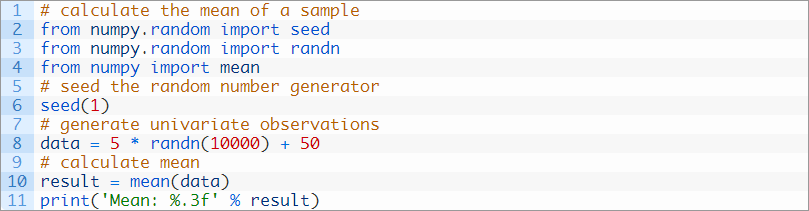
运行示例,计算并打印样本平均数。计算样本的算术平均数,用来估计符合潜在高斯分布的总体的参数,而样本是从这一总体中抽取的。作为估计,计算结果会包含误差。
因为我们知道潜在分布的真实平均数是50,我们可以看到,使用包含10000个观察结果的样本进行估计,结果是相当准确的。
平均数很容易受到离群值(少数远离平均数的值)的影响。这些离群值可能是分布边缘出现的罕见的观察结果或是误差。此外,平均数可能有误导性,在其他分布上计算平均数,例如uniform distribution或power distribution,可能没有多大意义,它将引出一个看似随机的期望值,而不是分布真正的集中趋势。
在存在离群值或非高斯分布的情况下,考察集中趋势的另一种常用方法是计算中位数。
中位数的计算方法是,首先对所有数据进行排序,然后确定样本中的中间值。
如果观察结果个数是奇数,那么计算起来很简单。
而如果观察结果个数是偶数,中位数就是中间两个观测结果的平均数。我们可以调用NumPy的median()函数来计算样本的中位数。
下面的例子就是基于测试数据集计算中位数:
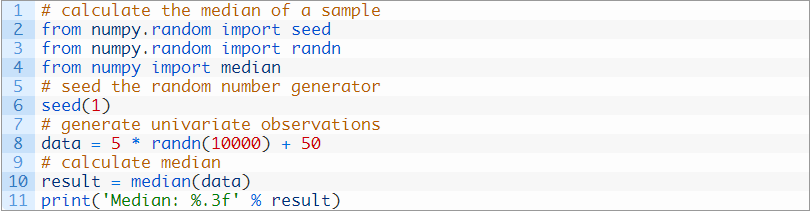
运行这个示例,计算并打印样本中位数。
结果与平均数没有太大的区别,因为样本符合高斯分布。如果数据是其他(非高斯分布)分布,中位数可能与平均值大不相同,也许更能反映出潜在总体的集中趋势。
方差
分布中的方差指的是,平均来说观察结果与平均数有多大差异或区别。可以把方差看作是分布范围的尺度。
方差小,数值会聚在平均值周围(例如窄的钟形);而方差大,数值会以平均数为中心分散开来(例如宽的钟形)。
我们可以举个例子,通过绘制理想化的高斯分布,其方差或大或小,用这两种图来证明这一点。下面是完整的示例。

运行这个示例,绘制两个理想化的高斯分布:蓝色的曲线代表方差小,数值分布聚集在平均数周围,而橙色曲线方差大,数值以平均数为中心分散开来。
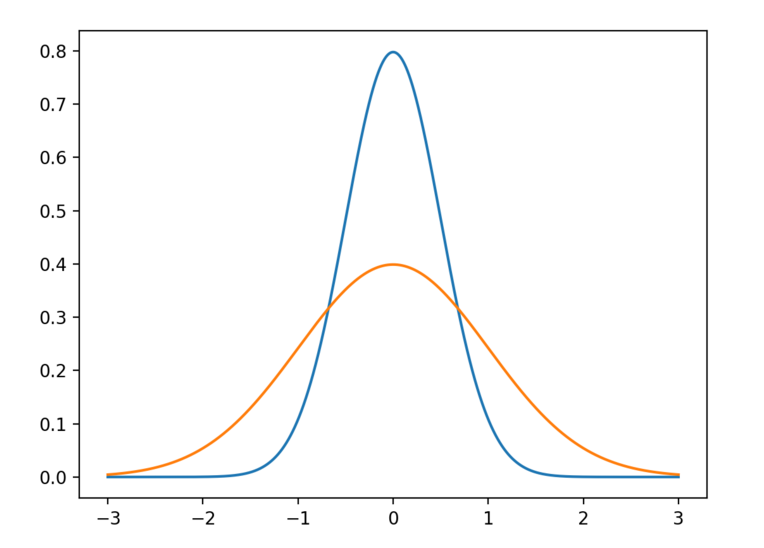
高斯分布线条图,橙色曲线方差大;蓝色曲线方差小
![]()
方差通常表示为s^2,清楚地显示了测量的平方单位。
你可能会发现,方程式没有对观察结果的数量(-1),因为这是计算总体方差,而不是样本方差。我们可以使用var()函数计算NumPy中数据样本的方差。
下面的例子演示了测试问题中的方差计算。

运行示例,计算并打印方差。
我们很难解释方差,因为使用的单位是观察结果的平方。我们可以计算结果的平方根,使单位变回观察结果的原始单位。例如,24.939的平方根约等于4.9。
总结高斯分布的范围时,通常是用方差的平方根。这被称作标准差。它与平均数一起作为规定高斯分布的两个重要参数。我们可以看到,为测试问题创建样本时,标准差4.9非常接近于规定的标准差值5。
我们可以直接对方差进行开方,计算出标准差。
通常将标准差写作s或希腊小写字母sigma。
可以调用std()函数直接在NumPy中计算出标准差。下面的例子演示了测试问题中计算标准差的过程。

运行这个示例,计算并打印出样本的标准差。该值与方差的平方根匹配,非常接近问题定义中指定的值5.0。
非高斯分布的方差也可以计算,不过通常还是要求确定分布,以便计算该分布特定的方差。
描述高斯分布
在应用机器学习中,你经常需要报告算法的结果,也就是说,基于样本外的数据报告估计的模型技能。这要通过k折交叉验证得出的平均性能,或一些其他的重复抽样程序来进行报告。在报告模型技能时,你实际上是在总结技能得分的分布,这些技能分数很可能是从高斯分布中抽取出来的。
只报告模型的平均性能是很普遍的。但这会隐藏另外两个关于模型技能分布的重要细节。作为最低限度,我建议报告模型分数(符合高斯分布)的两个参数,以及样本容量。理想情况下,确认模型技能分数是高斯分布,或足以接近高斯分布,使其能够证明报告中高斯分布的参数,也是个很好的方法。
这一点很重要,因为读者可以重新构建技能分数的分布,而且可与未来存在相同问题的模型技能相比较。
扩展
这节列出了一些你可能会想要探索的扩展问题。
- 开发你自己的测试问题,计算集中趋势和方差尺度。
- 开发函数,基于给定的数据样本,计算总结报告。
- 为标准机器学习数据集加载并总结变量。
总结
学完这篇教程,你了解了高斯分布,如何分辨高斯分布,以及如何计算从中抽取的重要的概要统计数据。
具体来说,你学会了:
- 高斯分布描述了许多观察结果,包括在应用机器学习过程中得到的观察结果。
- 观察结果最有可能按集中趋势分布,这可以通过数据样本的平均数或中位数进行估计。
- 方差是分布中平均数的平均差,可以通过数据样本中的方差和标准差进行估计。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消