











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






在Python中进行机器学习,随机数生成器的使用
2018年04月28日 由 浅浅 发表
541595
0

随机性一直是机器学习的重中之重。随机性一直作为工具或特征,出现在数据准备和学习算法中,将输入数据映射到输出数据以作出预测。为了理解机器学习中的统计方法,你必须了解机器学习中随机性的来源,即一种叫做伪随机数生成器的数学工具。
在本教程中,你将了解伪随机数生成器,以及何时在机器学习中控制随机性,或用随机性来进行控制。
学完这篇教程,你将会明白:
- 从算法角度解释应用机器学习中随机性的来源
- 伪随机数生成器是什么,如何在Python中使用它
- 何时控制实际数字序列和随机性,何时利用随机性进行控制
教程概述
本教程分为5部分,分别是:
- 机器学习的随机性
- 随机数生成器
- 如何建立随机数生成器
- 如何控制随机性
- 常见问题
机器学习的随机性
在应用机器学习中随机性的来源有很多。
随机性被视为一种工具,使学习算法更具鲁棒性,并最终得出更好的预测和更精准的模型。
让我们来看看一些随机性的来源。
数据的随机性
我们从域收集的数据样本中有一个随机的元素,我们将用它来训练和评估模型。数据可能会有错误或误差。更深入地说,这些数据包含的噪音可能模糊了输入和输出之间清晰的关系。
评估的随机性
我们无法获得所有来自域的观察结果。因此我们只处理一小部分数据。
我们在评估一个模型时利用随机性,例如使用k折交叉验证,基于不同可用数据集的子集,用来拟合及评估模型。
我们这样做是为了了解模型在通常情况下如何工作,而不是在一组特定数据的情况下。
算法的随机性
从数据样本中学习时,机器学习算法会使用随机性。在这样的特征中,随机性让算法实现的数据映射性能,比不使用随机性时更好。随机性是一种特征,让算法试图避免过拟合小的训练集,并将其推广到更广泛的问题。使用随机性的算法通常被称为随机算法,这并非无限随机的算法。这是因为尽管使用了随机性,但结果模型被限制在更窄的范围内(例如有限的随机性)。
在机器学习算法中使用随机性的例子包括:
- 在随机梯度下降中,每一个训练期前必先混排训练数据。
- 在随机森林算法中,为设定值选择随机的输入特征子集。
- 在人工神经网络中设定随机初始权值。
我们可以看到,这两种来源我们都必须进行控制,比如数据中的噪声,以及我们可以控制的随机性的来源(如算法评估和算法本身)。接下来,让我们看一下在算法和程序中使用的随机性的来源。
伪随机数生成器
在程序和算法中加入的随机性,主要通过一种叫做伪随机数生成器的数学工具。随机数生成器是从真实的随机性来源生成随机数的系统。通常与物理有关,比如盖革计数器,其结果会变成随机的数字。
在机器学习中,我们不需要真正意义上的随机性。相反,我们可以使用伪随机性。伪随机性是近似于随机的数字样本,但可用确定性过程生成。用伪随机数生成器生成的随机值来混排数据、初始化系数。这些小程序通常是你可以调用的函数,它会返回一个随机数。再次调用,他们就会返回一个新的随机数。包裹函数通常也是可用的,在一个特定的分布中,或在一个特定的范围内,让你得到以整数、浮点数形式出现的随机性。
这些数字是按一种序列生成的。这种序列是确定的,并以初始数编排好。如果你没有伪随机数生成器,那么它可能会像seed那样,在几秒或几毫秒中使用当前系统时间。seed值并不重要。选择任何你希望使用的值。真正重要的是,同样的seed进程会带来相同的随机数序列。
让我们用一些例子来说明这一点。
Python中的伪随机数生成器
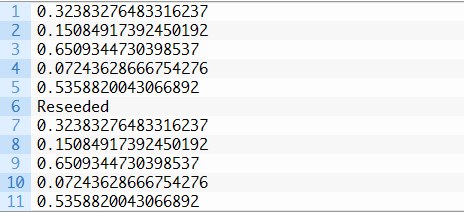
Python标准库提供了一个名为random的模块,其中包括生成随机数的一系列函数。Python使用了一个常见的、具有鲁棒性的伪随机数生成器,名为Mersenne Twister。伪随机数生成器可以调用random.seed()函数来建立。0和1之间的随机浮点值可以通过调用random.random()函数来生成。下面的例子是用伪随机数生成器,生成一些随机数,然后重新调用seed函数,以证明生成的是相同的数字序列。
下面的例子是用伪随机数生成器,生成一些随机数,然后重新调用seed函数,以证明生成的是相同的数字序列。

运行这个示例,举出了五个随机浮点值,而在伪随机数生成器被重新调用后,出现5个同样的浮点值。
NumPy中的伪随机数生成器
在机器学习中,您可能会使用诸如scikit-learn和Keras这样的库。这些库使用了NumPy,这种库使利用向量和数字矩阵的方法非常有效。NumPy也有自己的伪随机数生成器和方便使用的包裹函数。NumPy还配备了Mersenne Twister伪随机数生成器。
重要的是,在Python伪随机数生成器中的seed不会影响NumPy伪随机数生成器,它会单独使用并运行seed。下面的例子是用伪随机数生成器seed,生成5个随机浮点值的阵列,之后生成器再次调用seed,并且演示了生成相同的随机数序列。
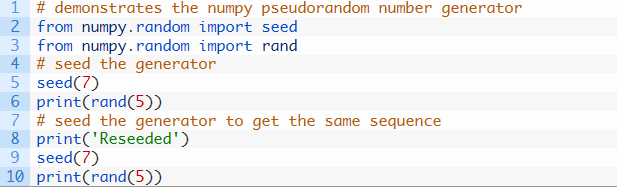
运行这个示例,列举了第一批数字,以及在生成器重新调用后,生成的完全相同的第二批数字。

既然我们知道了如何生成可控随机数,那么就让我们看看可以在哪里有效使用它们吧。
什么时候调用随机数生成器
在预测建模项目中,有一些你应该考虑调用随机数字生成器的时机。
让我们来看两种情况:
- 数据准备。数据准备过程可能需要使用随机性,例如数据编排或值的选择,数据准备必须是一致的,在安装、评估和对最终模型进行预测时,总是以相同的方式进行数据准备。
- 数据分割,例如,对于训练和测试数据分割或k折交叉验证,必须一致地进行。这是为了确保每个算法都基于相同的数据子样本,以相同的方式进行训练和评估。
你可能希望在执行每个任务或批任务之前,先将伪随机数生成器调用一次。一般来说,这样做并不重要。有时你可能希望一个算法能够一致地运行,因为它每次都是基于完全相同的数据进行训练的。如果在production环境中使用该算法,可能会发生这种情况。如果你在tutorial环境中演示了算法,那么这种情况也有可能发生。因此,在拟合算法之前初始化seed是必要的。
如何控制随机性
随机机器学习算法每次在相同的数据上运行时,学习的情况都会略有不同。这将导致模型在每次训练后表现出的性能略有不同。如前所述,我们可以每次使用相同的随机数序列来拟合模型。这样在评估一个模型时,会出现很糟的情况,因为它隐藏了模型固有的不确定性。
对算法进行评估,报告的性能包括对算法性能测量的不确定性,这是一种更好的方法。我们可以通过用随机数序列对算法进行多次重复评估。伪随机数生成器可以在评估开始时被调用一次,或者可以在每次评估开始时,用不同的seed进行调用。
这时需要考虑不确定性的两个方面:
- 数据不确定性。基于多重分割的数据对算法进行评估,有助于了解算法性能如何随训练和测试数据的变化而变化。
- 算法不确定性。基于相同的分割数据多次评估一个算法,会让我们了解算法性能是如何独立变化的。
一般而言,我推荐将这两个不确定因素来源结合之后再作报告。算法正是这样基于每个评估运行的不同数据分割进行拟合,并包含新的随机序列。评估过程可以在开始时对随机数生成器调用一次,而这个过程可以重复30次或更多,以给出可以进行总结的性能分数总体。这将在训练数据和学习算法本身中对模型性能进行合理的描述。而且这对于描述模型性能来说十分实用,而且训练数据和学习算法本身的变化都会考虑在内,
常见问题
我能预测随机数吗?
你无法预测随机数的序列,即使用深度神经网络也不行。
真随机数会带来更好的结果吗?
据我所知,在一般情况下使用真随机性是没有帮助的,除非你使用的是物理过程的模拟。
那么最终的模型呢?
最终的模型是选定的算法和配置,这些都已在所有可用的训练数据上训练过,可以用来进行预测。该模型的性能在评估模型结果的变化范围内波动。
扩展
本节列出了一些本教程的想法扩展,你可能希望进行深入探索。
- 确认在Python伪随机数生成器中的seed不会影响NumPy伪随机数生成器。
- 探索在一定范围和高斯随机数之间生成整数的例子。
- 确定能建立非常简单的伪随机数生成器的方程式。
总结
读完这篇教程,你明白了应用机器学习中随机性的作用,以及如何控制并利用它。
具体来说,你学会了:
- 机器学习中随机性的来源,如数据样本和算法本身所带来的随机性。
- 用伪随机数字生成器将随机性添加到程序和算法中。
- 有时需要谨慎控制随机性,有时利用随机性来进行控制。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消