











请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






Scikit-learn中文文档发布,Python爱好者们准备好了吗?
2018年04月09日 由 nanan 发表
832819
0

近日,Scikit-Learn中文文档已由开源组织ApacheCN完成校对,这对于国内机器学习用户有非常大的帮助。该中文文档依然包含了Scikit-Learn基本功能的六大部分:分类、回归、聚类、数据降维、模型选择和数据预处理,并提供了完整的使用教程与API注释。入门读者也可以借此文档与教程从实践出发进入数据科学与机器学习的领域。
中文文档地址:http://sklearn.apachecn.org
Scikit-learn是以Python的开源机器学习库和NumPy和SciPy等科学计算库为基础,支持SVM(支持向量机)、随机森林、梯度提升树、K均值聚类等学习算法。Scikit-learn目前主要由社区成员自发进行维护,且专注于构建机器学习领域内经广泛验证的成熟算法。
Scikit-Learn项目最早由数据科学家David Cournapeau在2007年发起,是Python语言中专门针对机器学习应用而发展起来的一款开源框架。Scikit-learn大部分都是由Python构建,但还是有很多核心算法是由Cython完成而实现更好的效果,例如支持向量机就是由Cython构建。

在监督学习部分,Scikit-learn提供了广义线性模型、支持向量机、最近邻算法、高斯过程、朴素贝叶斯、决策树和集成方法等算法教程,同时还介绍了特征选择、随即梯度下降算法、线性与二次判别分析等在监督学习中非常重要的概念。
除了监督学习,半监督学习中的标签传播算法和无监督学习中的聚类与降维算法都有非常多的教程。此外,在模型选择中,文档教程描述了交叉验证的使用、估计器超参数的调整、模型评估方法和模型持久化概念等。
以下选取了SVM的部分使用教程,你可以借此了解Scikit-Learn中文文档的组织形式与基本内容。
SVC、NuSVC和LinearSVC能在数据集中实现多元分类:
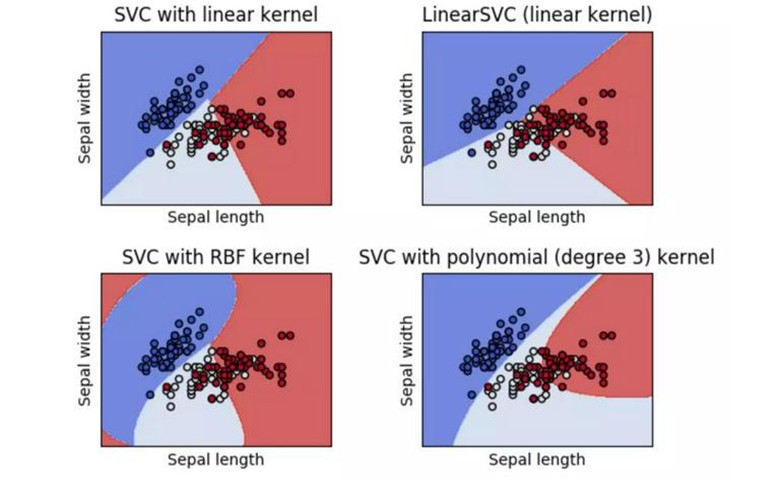
SVC和NuSVC是相似的方法,但是接受稍许不同的参数设置并且有不同的数学方程。另一方面,LinearSVC是另一个实现线性核函数的支持向量分类。记住LinearSVC不接受关键词kernel,因为它被假设为线性的。它也缺少一些SVC和NuSVC的成员(members)比如support_。
和其他分类器一样,SVC、NuSVC和LinearSVC将两个数组作为输入:[n_samples, n_features]大小的数组X作为训练样本,[n_samples]大小的数组y作为类别标签(字符串或者整数):
>>> from sklearn import svm
>>> X = [[0, 0], [1, 1]]
>>> y = [0, 1]
>>> clf = svm.SVC()
>>> clf.fit(X, y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovr', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
在拟合后, 这个模型可以用来预测新的值:
>>> clf.predict([[2., 2.]])
array([1])
SVMs 决策函数取决于训练集的一些子集, 称作支持向量. 这些支持向量的部分特性可以在support_vectors_、support_和n_support找到:
>>> # 获得支持向量
>>> clf.support_vectors_
array([[ 0., 0.],
[ 1., 1.]])
>>> # 获得支持向量的索引get indices of support vectors
>>> clf.support_
array([0, 1]...)
>>> # 为每一个类别获得支持向量的数量
>>> clf.n_support_
array([1, 1]...)
以上是SVM简单的介绍,更完整的内容前查看原文档。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com








广告


写评论取消
回复取消