












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






谷歌发布MobileNetV2:新一代移动端计算机视觉网络
2018年04月04日 由 yuxiangyu 发表
887545
0
去年,谷歌发布了MobileNetV1,这是一个通用的计算机视觉神经网络,用于支持在移动设备上分类,检测等等。在个人移动设备上运行深度神经网络的能力改善了用户体验,可以随时随地访问,并为安全、隐私和能耗带来了额外的优势。随着新应用的出现,用户可以与真实世界进行实时交互,因此需要更高效的神经网络。
今天,我们很高兴地宣布,MobileNetV2将助力下一代移动视觉应用。MobileNetV2相对于MobileNetV1的重大改进,并推动了移动视觉识别技术的发展,包括分类,对象检测和语义分割。MobileNetV2作为TensorFlow-Slim图像分类库的一部分发布 ,你可以立即开始在Colaboratory中探索它 。或者,你也可以使用Jupyter下载,并在本地探索它。MobileNetV2也可作为TF-Hub上的模块使用,预训练检查点可在Github上找到。
Github:https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet
MobileNetV2继承了MobileNetV1的思想,使用深度可分离卷积结构作为构建模块。而MobileNetV2引入了两种新的功能:层之间的线性瓶颈;瓶颈之间的连接捷径(shortcut)。基础架构如下所示:
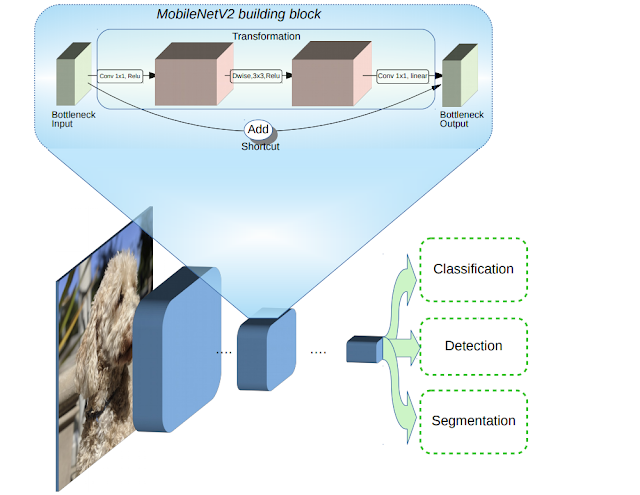
MobileNetV2架构,蓝色块表示复合卷积构建块。
直觉是,瓶颈对模型的中间输入和输出进行编码,而内层封装了模型从低级概念(如像素)转换为更高级别描述符(如图像类别)的能力。最后,与传统的残差连接(residual connections)一样,而这个“捷径”可实现更快的训练和更高的准确性。
更多细节:https://arxiv.org/abs/1801.04381
与第一代MobileNets比较
总体而言,MobileNetV2模型在整个延迟范围中实现相同精度更快。特别是,新模型使用的运算(operation)减少了2倍,所需参数减少了30%,在Google Pixel手机上的速度比MobileNetV1机型快30%至40%,同时实现了更高的精度。
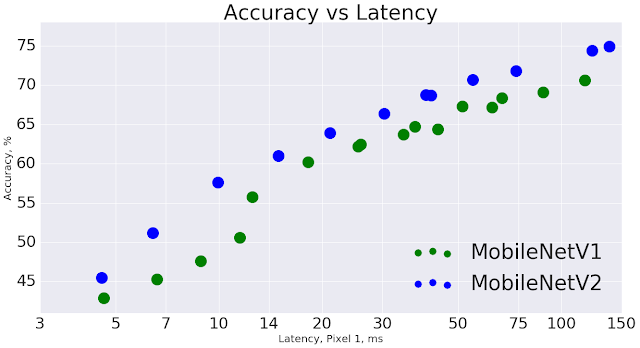
MobileNetV2提高了速度(缩短了延迟)并提高了ImageNet Top 1的准确性
MobileNetV2是对目标检测和分割的非常有效的特征提取器。例如,对于检测任务来说,与新推出的SSDLite搭配时,同等准确性,新模型要比MobileNetV1快大约35%。我们已经在Tensorflow对象检测API中开源了这个模型。
地址:https://github.com/tensorflow/models/tree/master/research/object_detection

为了实现设备级的语义分割,我们使用MobileNetV2作为近期发布的DeepLabv3简化形的特征提取器。使用语义分割的基准PASCAL VOC 2012,我们最终的模型获得了与使用MobileNetV1作为特征提取器相似的性能,但使用参数少5.3倍,运算减少5.2倍。

正如我们所看到的,MobileNetV2提供了一个非常高效的移动端模型,可以用作许多视觉识别任务的基础。我们希望通过将它分享给更广泛的学术和开源社区,携手推进研究和应用程序的开发。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消