












请先登录您的atyun账户,方可使用该功能

审核通过后即可使用此功能,请耐心等待~






2018年你应该知道的十大机器学习算法
2018年04月02日 由 nanan 发表
355406
0
本文简要介绍一些最常用的机器学习算法,没有代码,没有抽象理论,只有图片和一些如何使用它们的例子。
本文涵盖的算法列表包括:
1.决策树
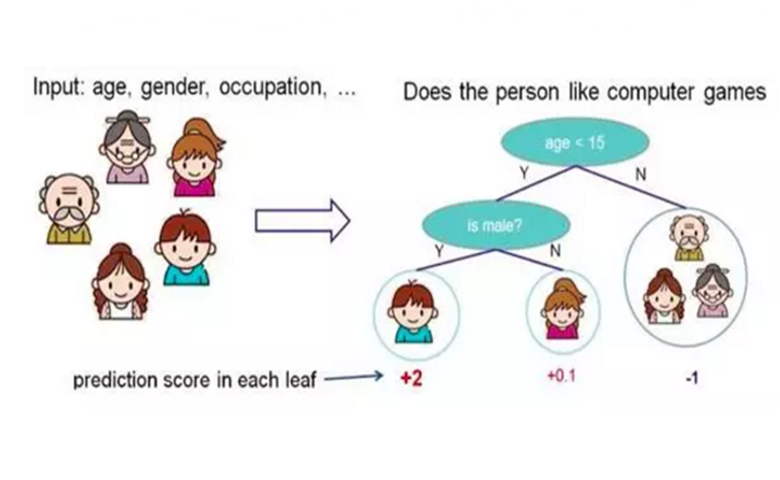
使用某些属性将一组数据分类为不同的组中,在每个节点上执行测试,通过brach判断,进一步将数据拆分两个不同的组,此次等等。测试是基于现有的数据进行的,当添加新数据时,可以将其分类为相应的组。
根据某些特征对数据进行分类,每当过程进入下一步时,就会有一个判断分支,并且判断将数据分为两部分,然后过程继续。当对现有数据进行测试时,新数据可以通过现有数据了解这些问题,当有新的数据出现时,计算机可以将数据归类到正确的分支中。
2.随机森林
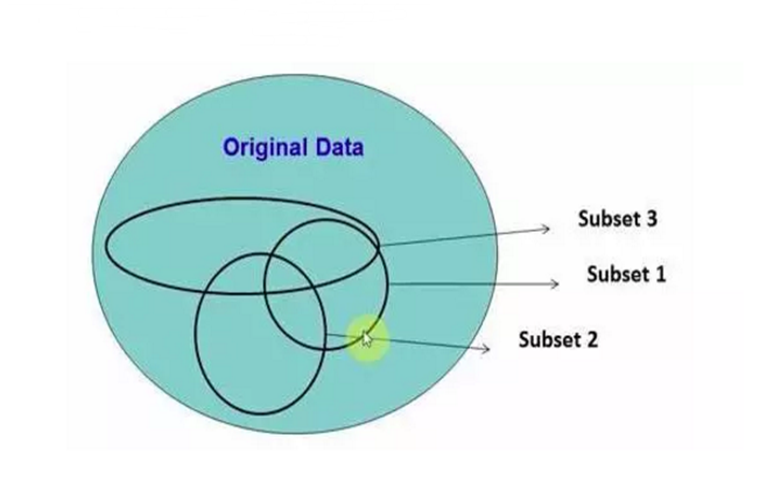
从原始数据中随机选择,并形成不同的子集。
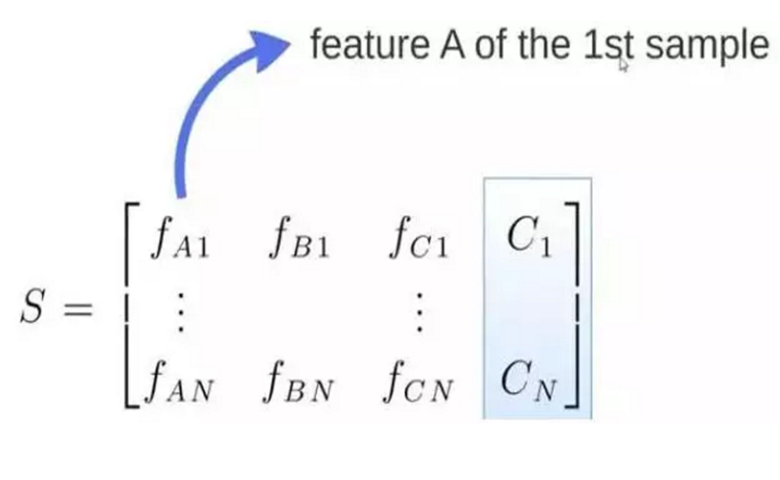
矩阵S是原始数据,它包含1-N数据行,而A,B,C是特征,最后一个C代表类别。
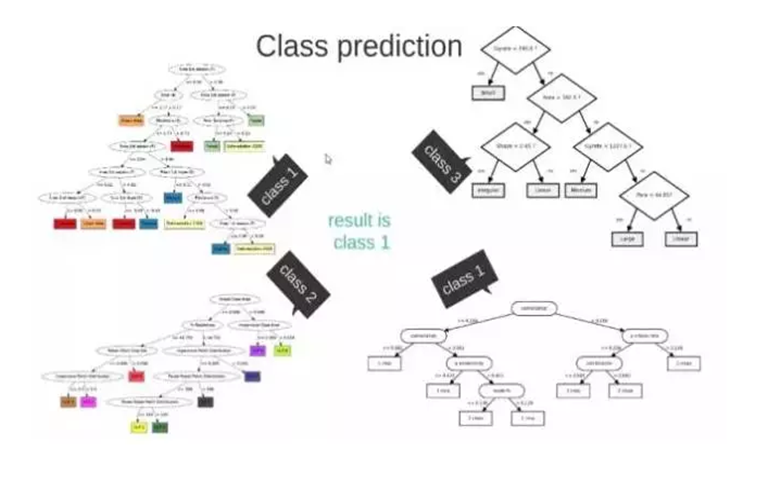
从S中创建随机子集,假设我们有M组子集。

我们从这些子集得到M组决策树:将新的数据放入这些树中,我们可以得到M组的结果,并且我们计算出在所有M组中哪个结果是最多的,我们可以把这看作是最终结果。
 3.逻辑回归
3.逻辑回归
当预测目标的概率大于0且小于或等于1时,简单的线性模型不能满足预测目标的概率。因为当定义的域不在一定级别时,范围将超过指定的间隔。
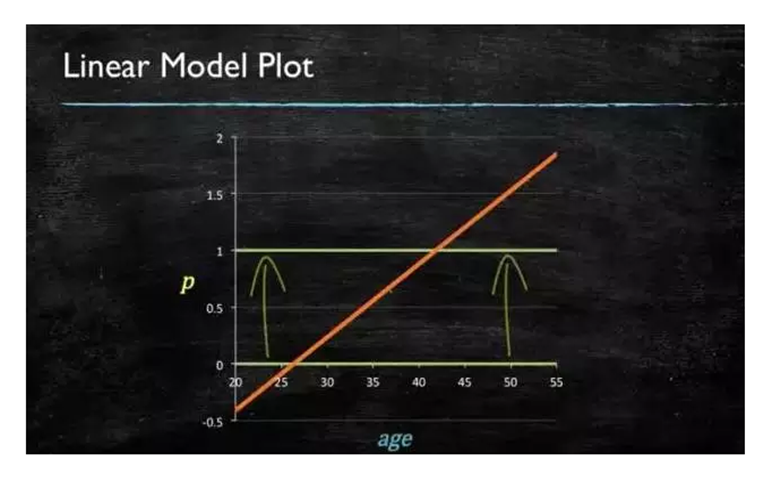
我们最好使用这种模型。
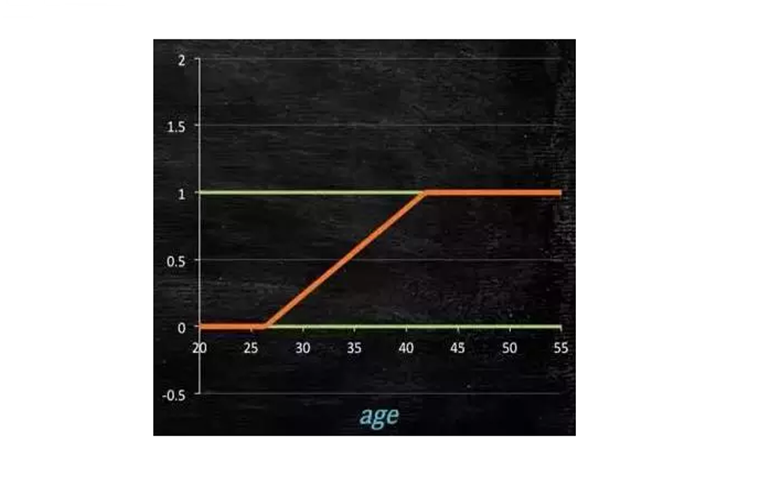
那么我们如何得到这个模型呢?
这个模型需要满足两个条件:“大于或等于0”,“小于或等于1”。
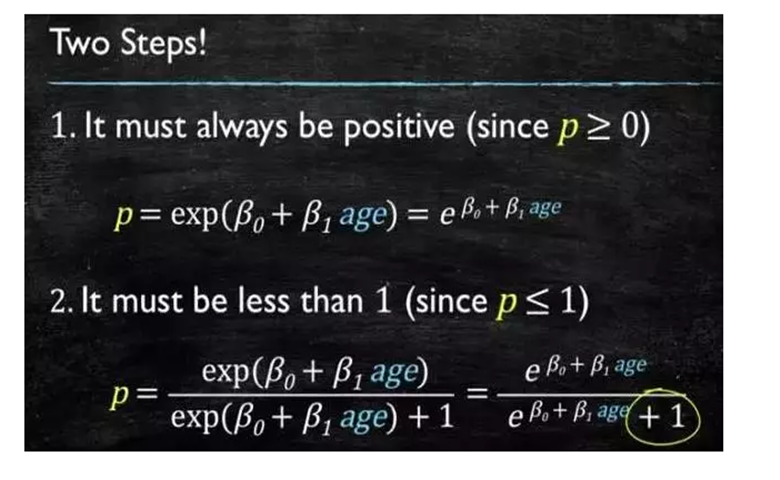
我们变换公式,得到逻辑回归模型:

通过计算原始数据,我们可以得到相应的系数。
我们得到逻辑模型图:
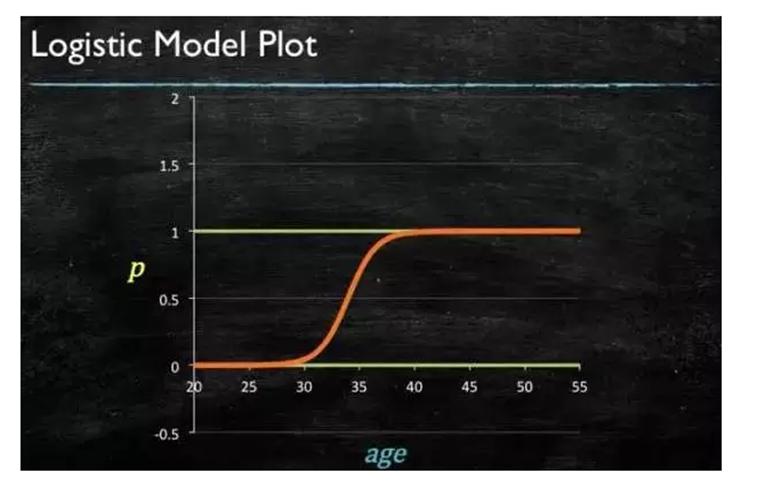 4.支持向量机
4.支持向量机
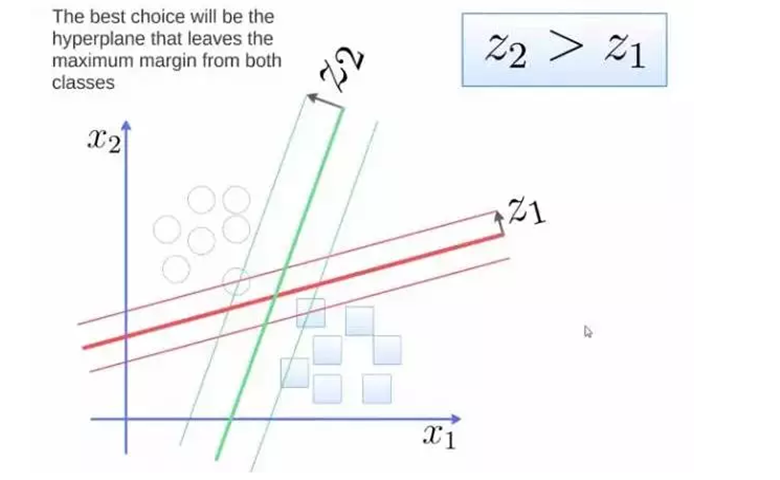
为了将这两个类从超平面中分离出来,最好的选择是在两个类中最大限度地保留最大边距的超平面。因为Z2>Z1,所以绿色的更好。
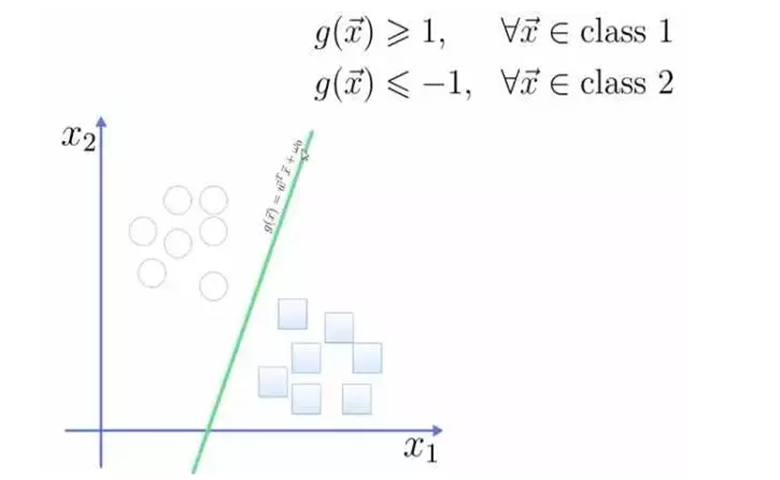
使用线性方程表示超平面,线上方的类大于或等于1,另一个类小于或等于-1。
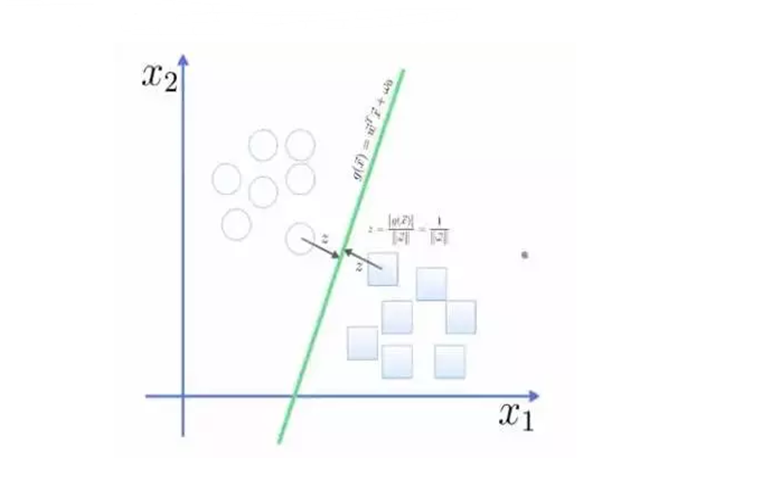
利用图中的方程计算出点到曲面之间的距离:
所以我们得到了下面的总边际的表达式,目的是最大化边际,我们需要做的是最小化分母:

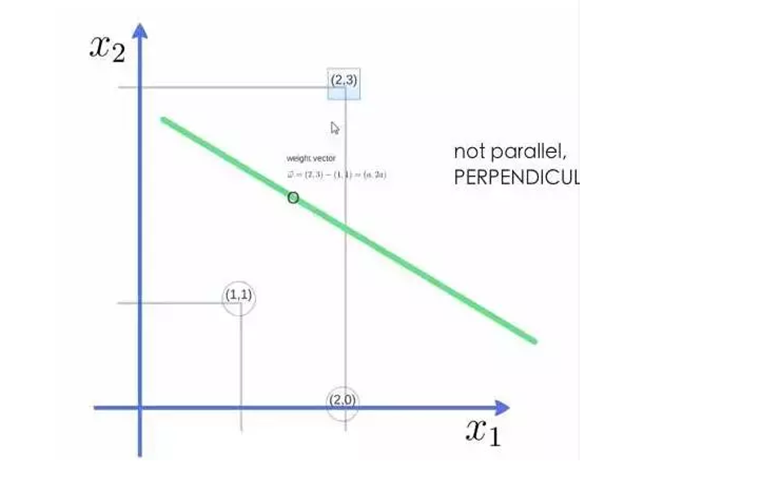
例如,我们用3个点来找到最优的超平面,定义权向量=(2,3)- (1,1):
并获得权重向量(a,2a),将这两个点代入方程:
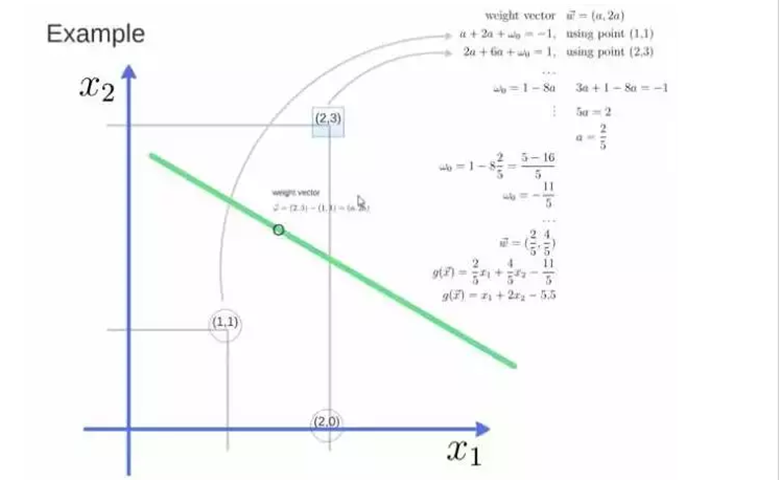
当a被确认时,使用(a,2a)的结果为支持向量,代入a和w0的方程为支持向量机。
5.朴素贝叶斯
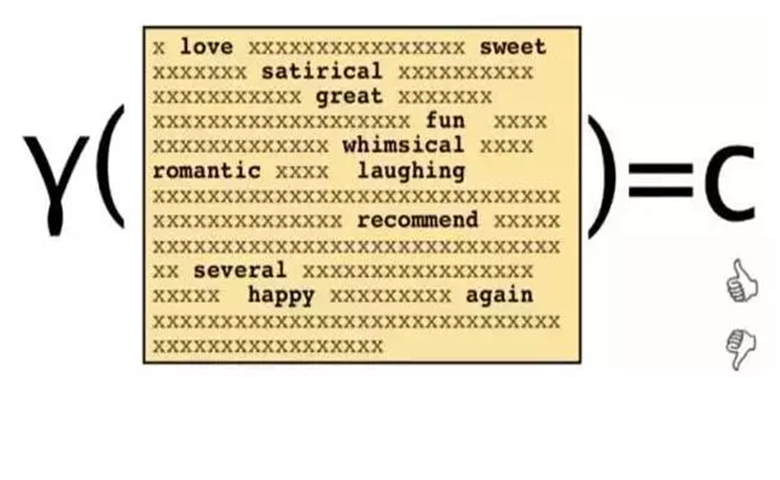
下面是NLP的一个例子:给出一段文字,检查文本的态度是积极的还是消极的,

为了解决这个问题,我们只能看一些单词:
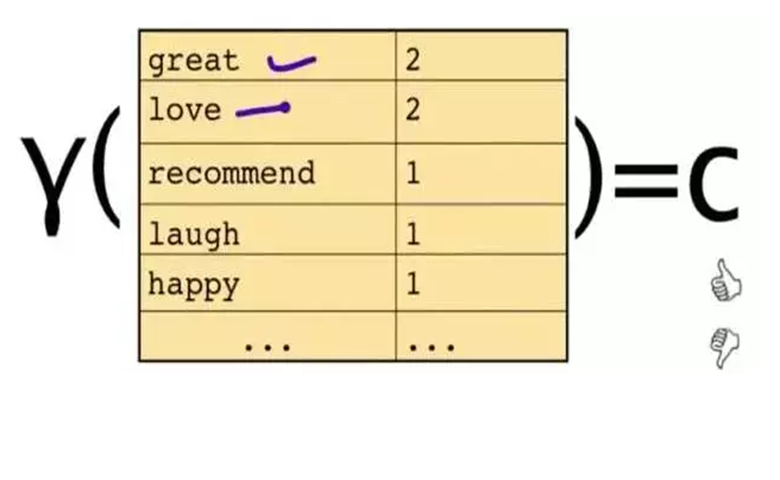
而这些话,只会代表一些单词和它们的数量:
原来的问题是:给你一个句子,它属于哪一类?
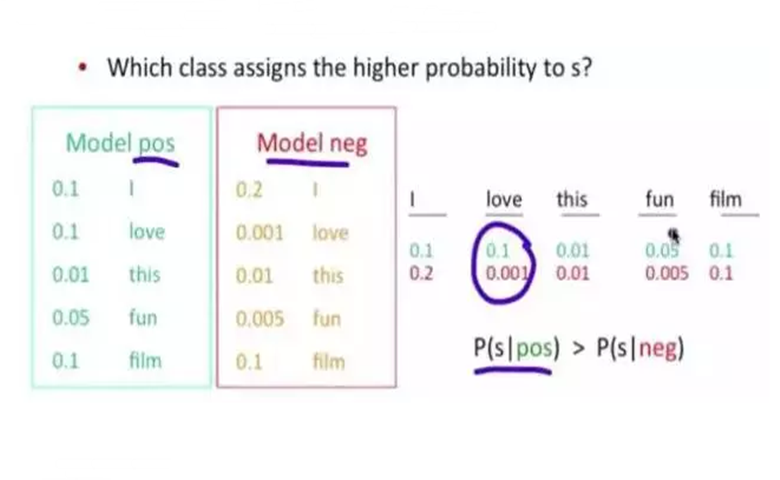
通过使用贝叶斯规则,这将是一个简单的问题。

问题是,在这个课堂上,这个句子出现的概率是多少?记住不要忘记方程中的其它两个概率。
例如:“爱”一词的出现概率在正类中为0.1,在负类中为0.001。
6.k-最近邻
当出现一个新的数据时,哪个类别有最接近它的点,它属于哪个类别。
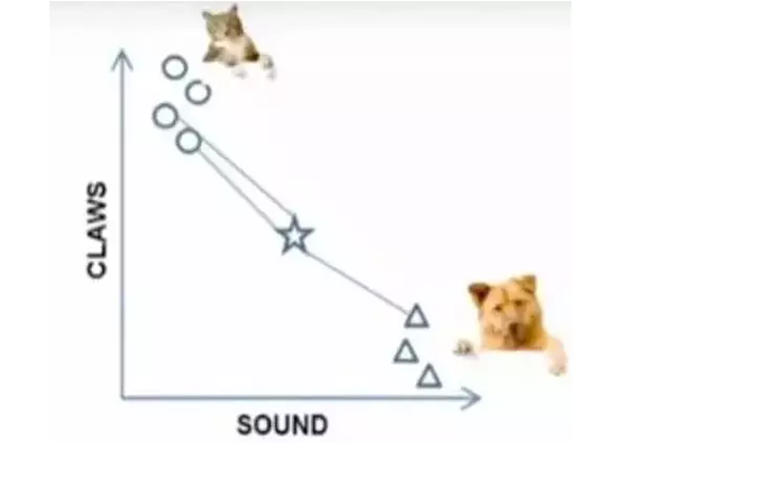
例如:为了区分“狗”和“猫”,我们从“爪子”和“声音”两个特征来判断。圆圈和三角形是已知的类别,“星星”代表疑问:

当K = 3时,这三条线连接最近的3个点,圆圈更多,所以“星”属于“猫”。
7.k-均值
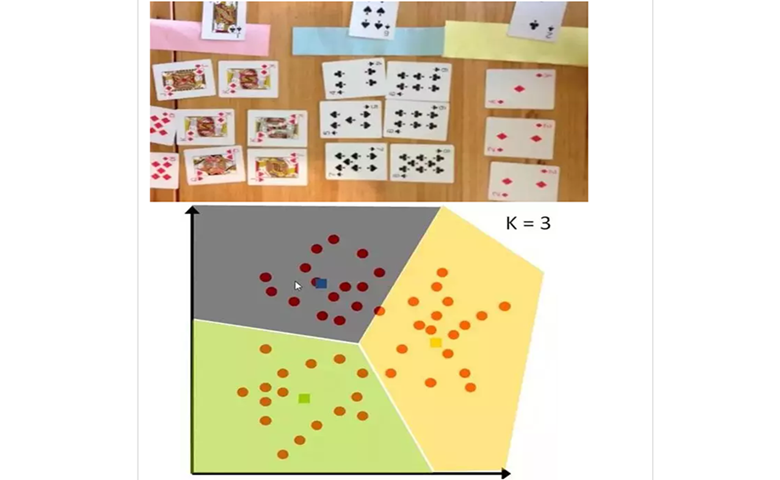
将数据分为3类,粉色部分最大,黄色最小。
选择3、2、1作为默认值,并计算其余数据与默认值之间的距离,并将其分类为具有最短距离的类。

分类后,计算每个类的方法,并将其设置为新中心。

经过几轮之后,我们可以在类不再更改时停止。
8.Adaboost
Adaboost是提高的一种方法。
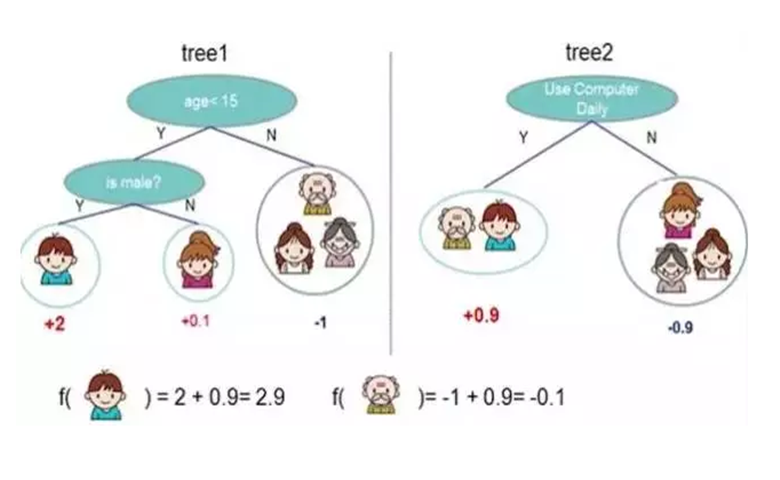
促进是收集没有得到满意结果的分类器,并生成一个可能具有更好效果的分类器。
如下图所示,树1和树2分别没有好的效果,但是如果我们输入相同的数据,并对结果进行总结,最终的结果会更有说服力。
以adaboost为例,在手写识别中,面板可以提取许多特征,例如开始方向,起点和终点之间的距离等。
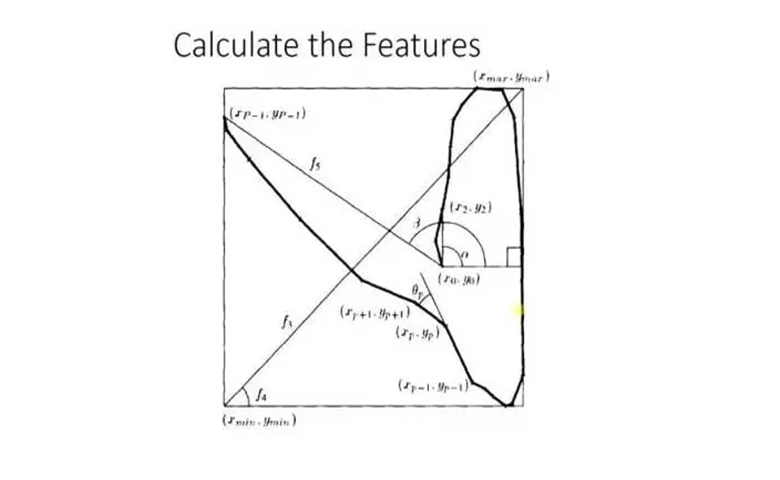
在训练机器时,它会得到每个特征的重量,比如2和3,它们的起始点非常相似,所以这个特征对分类没有什么影响,因此它的重量很小。

但是这个角度有很大的可识别性,所以这个特征的重量是很大的。最后的结果将是考虑所有这些特性的结果。
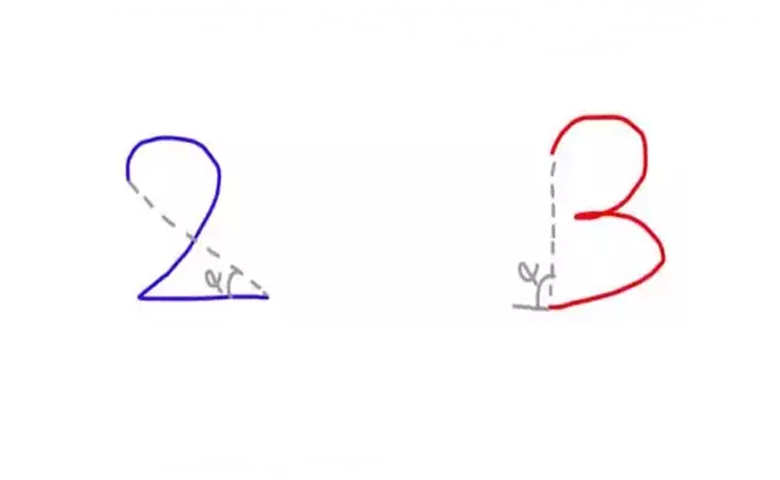
9.神经网络
在NN中,输入可能会被至少分成两个类。
神经网络是由网络和网络连接形成的。
第一层是输入层,最后一层是输出层。
在隐藏层和输出层中,它们都有自己的分类器。
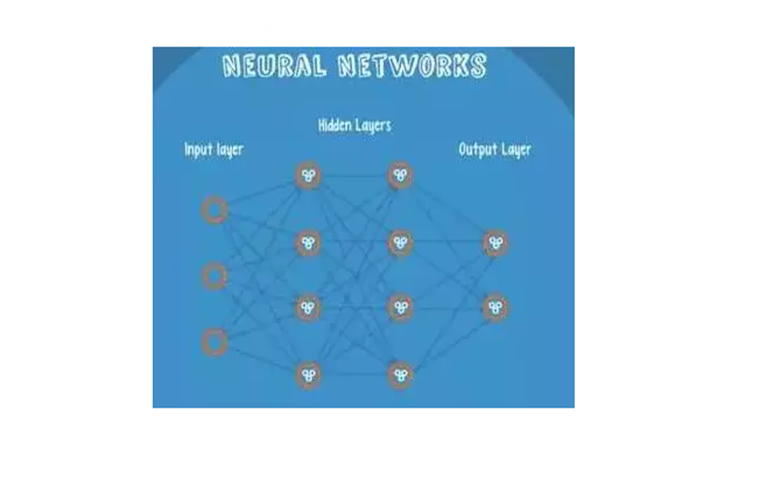
当输入进入网络并被激活时,计算得分将传递到下一层。输出层显示的分数是每个班级的分数。下面的例子得到第1类的结果:
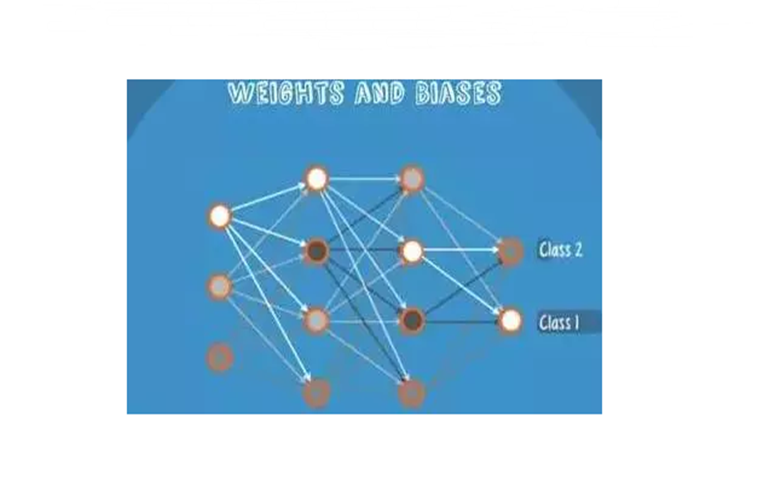
传递给不同节点的相同输入产生不同的分数,这是因为在每个节点中,它具有不同的权重和偏差,这是传播。
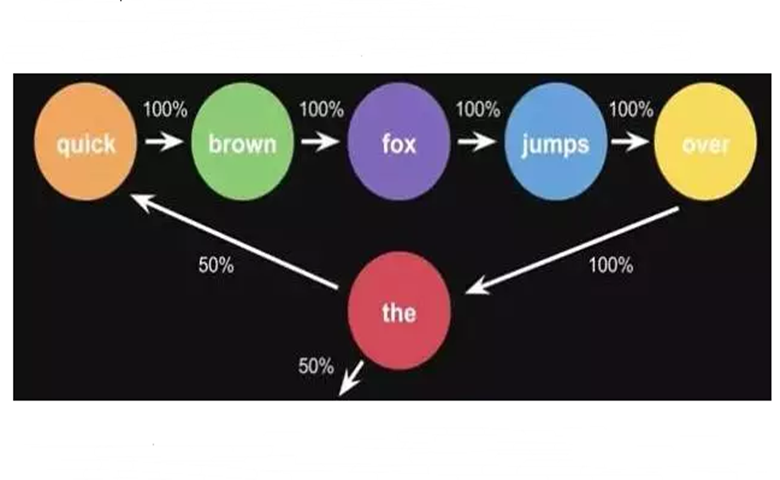
10.马尔可夫链
马尔可夫链由状态和转换组成。
例如,基于“快速的棕色狐狸跳过懒狗”获得马尔可夫链。
首先,我们需要将每个单词设置在一个状态下,并且我们需要计算状态转换的概率。
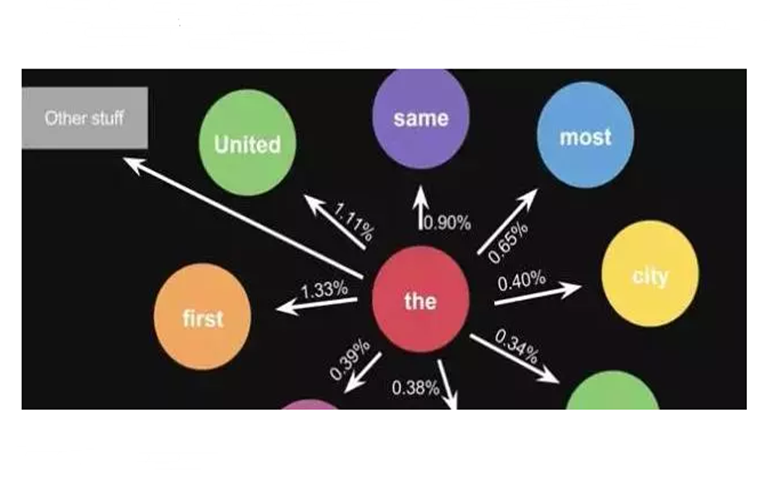
这些是由一个句子计算出来的概率。当你使用大量的文本数据来训练计算机时,你会得到一个更大的状态转换矩阵,比如可以跟随“the”的单词,以及它们对应的概率。
本文涵盖的算法列表包括:
- 决策树
- 随机森林
- 逻辑回归
- 支持向量机
- 朴素贝叶斯
- k-最近邻
- k-均值
- Adaboost
- 神经网络
- Markov
1.决策树
使用某些属性将一组数据分类为不同的组中,在每个节点上执行测试,通过brach判断,进一步将数据拆分两个不同的组,此次等等。测试是基于现有的数据进行的,当添加新数据时,可以将其分类为相应的组。
根据某些特征对数据进行分类,每当过程进入下一步时,就会有一个判断分支,并且判断将数据分为两部分,然后过程继续。当对现有数据进行测试时,新数据可以通过现有数据了解这些问题,当有新的数据出现时,计算机可以将数据归类到正确的分支中。
2.随机森林
从原始数据中随机选择,并形成不同的子集。
矩阵S是原始数据,它包含1-N数据行,而A,B,C是特征,最后一个C代表类别。
从S中创建随机子集,假设我们有M组子集。
我们从这些子集得到M组决策树:将新的数据放入这些树中,我们可以得到M组的结果,并且我们计算出在所有M组中哪个结果是最多的,我们可以把这看作是最终结果。
3.逻辑回归当预测目标的概率大于0且小于或等于1时,简单的线性模型不能满足预测目标的概率。因为当定义的域不在一定级别时,范围将超过指定的间隔。
我们最好使用这种模型。
那么我们如何得到这个模型呢?
这个模型需要满足两个条件:“大于或等于0”,“小于或等于1”。
我们变换公式,得到逻辑回归模型:
通过计算原始数据,我们可以得到相应的系数。
我们得到逻辑模型图:
4.支持向量机为了将这两个类从超平面中分离出来,最好的选择是在两个类中最大限度地保留最大边距的超平面。因为Z2>Z1,所以绿色的更好。
使用线性方程表示超平面,线上方的类大于或等于1,另一个类小于或等于-1。
利用图中的方程计算出点到曲面之间的距离:
所以我们得到了下面的总边际的表达式,目的是最大化边际,我们需要做的是最小化分母:
例如,我们用3个点来找到最优的超平面,定义权向量=(2,3)- (1,1):
并获得权重向量(a,2a),将这两个点代入方程:
当a被确认时,使用(a,2a)的结果为支持向量,代入a和w0的方程为支持向量机。
5.朴素贝叶斯
下面是NLP的一个例子:给出一段文字,检查文本的态度是积极的还是消极的,
为了解决这个问题,我们只能看一些单词:
而这些话,只会代表一些单词和它们的数量:
原来的问题是:给你一个句子,它属于哪一类?
通过使用贝叶斯规则,这将是一个简单的问题。
问题是,在这个课堂上,这个句子出现的概率是多少?记住不要忘记方程中的其它两个概率。
例如:“爱”一词的出现概率在正类中为0.1,在负类中为0.001。
6.k-最近邻
当出现一个新的数据时,哪个类别有最接近它的点,它属于哪个类别。
例如:为了区分“狗”和“猫”,我们从“爪子”和“声音”两个特征来判断。圆圈和三角形是已知的类别,“星星”代表疑问:
当K = 3时,这三条线连接最近的3个点,圆圈更多,所以“星”属于“猫”。
7.k-均值
将数据分为3类,粉色部分最大,黄色最小。
选择3、2、1作为默认值,并计算其余数据与默认值之间的距离,并将其分类为具有最短距离的类。
分类后,计算每个类的方法,并将其设置为新中心。
经过几轮之后,我们可以在类不再更改时停止。
8.Adaboost
Adaboost是提高的一种方法。
促进是收集没有得到满意结果的分类器,并生成一个可能具有更好效果的分类器。
如下图所示,树1和树2分别没有好的效果,但是如果我们输入相同的数据,并对结果进行总结,最终的结果会更有说服力。
以adaboost为例,在手写识别中,面板可以提取许多特征,例如开始方向,起点和终点之间的距离等。
在训练机器时,它会得到每个特征的重量,比如2和3,它们的起始点非常相似,所以这个特征对分类没有什么影响,因此它的重量很小。
但是这个角度有很大的可识别性,所以这个特征的重量是很大的。最后的结果将是考虑所有这些特性的结果。
9.神经网络
在NN中,输入可能会被至少分成两个类。
神经网络是由网络和网络连接形成的。
第一层是输入层,最后一层是输出层。
在隐藏层和输出层中,它们都有自己的分类器。
当输入进入网络并被激活时,计算得分将传递到下一层。输出层显示的分数是每个班级的分数。下面的例子得到第1类的结果:
传递给不同节点的相同输入产生不同的分数,这是因为在每个节点中,它具有不同的权重和偏差,这是传播。
10.马尔可夫链
马尔可夫链由状态和转换组成。
例如,基于“快速的棕色狐狸跳过懒狗”获得马尔可夫链。
首先,我们需要将每个单词设置在一个状态下,并且我们需要计算状态转换的概率。
这些是由一个句子计算出来的概率。当你使用大量的文本数据来训练计算机时,你会得到一个更大的状态转换矩阵,比如可以跟随“the”的单词,以及它们对应的概率。

欢迎关注ATYUN官方公众号
商务合作及内容投稿请联系邮箱:bd@atyun.com


广告







广告

写评论取消
回复取消